CUBRID Recovery Manager — ARIES Three-Pass Restart
Contents:
- Theoretical Background
- Common DBMS Design
- CUBRID’s Approach
- Source Walkthrough
- Source verification (as of 2026-04-30)
- Beyond CUBRID — Comparative Designs & Research Frontiers
- Sources
Theoretical Background
Section titled “Theoretical Background”The recovery manager is the contract holder of ACID-A (atomicity) and the active partner of WAL in ACID-D (durability). Mohan et al.’s ARIES (TODS 17.1, 1992) is the canonical algorithm every disk- resident relational engine implements; Database Internals (Petrov, ch. 5 §“ARIES”) is the textbook treatment. Both decompose the restart problem into three sequential passes over the log:
- Analysis pass. Walk forward from the most-recent checkpoint to the end of the log. Reconstruct the dirty-page table (DPT) and the transaction table (TT). At the end we know which transactions were active at crash, which pages may need redo, and what the minimum redo-LSA is.
- Redo pass. Walk forward from the minimum redo-LSA. For each
log record whose target page was potentially dirty at crash time,
fetch the page; if
page.lsa < record.lsa, apply the redo function. This restores the database to the exact state at the moment of crash, including the changes of transactions that never committed. - Undo pass. Walk the per-transaction LSA chain backward for each loser transaction (active-but-uncommitted at crash). For each undo-eligible record, apply the undo function and emit a compensation log record (CLR) so the undo itself is restartable.
Two implementation choices the model leaves open shape every real engine and frame the rest of this document:
- Logging granularity. Physical (byte-level page diffs) vs. physiological (“slot 5 of page X gets these bytes”) vs. logical (“insert key K with OID O into B+Tree T”). CUBRID is physiological for the data side (heap, page-level operations) and logical for index operations (B+Tree splits, unique-key conflicts) where physical undo would be impossible without recording the entire page state.
- Checkpoint placement. Sharp/consistent checkpoint (engine
stops, flushes everything, writes a single checkpoint record)
vs. fuzzy checkpoint (engine takes a snapshot of active
transactions and dirty pages without stopping; writes
LOG_START_CHKPTat one LSA andLOG_END_CHKPTat a later LSA). CUBRID does fuzzy checkpoints — almost universal in modern engines because consistent checkpoints cost too much throughput.
After the choices are named, every CUBRID-specific structure in this document either implements one of them or makes the implementation faster.
Common DBMS Design
Section titled “Common DBMS Design”Every WAL-and-recovery engine — PostgreSQL, InnoDB, Oracle, SQL Server, CUBRID — adopts the same handful of conventions on top of ARIES. They are not in the original 1992 paper; they are the engineering vocabulary that lives between the theory and the source.
Per-record-type recovery dispatch
Section titled “Per-record-type recovery dispatch”Each log record carries an LOG_RCVINDEX (or equivalent enum) into
a function table indexed by record kind. The table entry pairs
(undofun, redofun) plus a debug dump function. Adding a new
record kind is a three-step ritual: (1) add the enum value,
(2) write the redo function and the undo function, (3) register
both in the table. The ritual is identical across engines —
PostgreSQL’s RmgrTable[].rm_redo, InnoDB’s recv_parse_or_apply_log_rec_body,
CUBRID’s RV_fun[].
Dirty page table reconstructed at analysis
Section titled “Dirty page table reconstructed at analysis”At analysis time the engine cannot trust on-disk page contents because some dirty pages may have been written, others may not. The dirty page table tells redo which pages might not have made it. CUBRID rebuilds this from the previous checkpoint’s DPT plus all log records since the checkpoint that marked a page dirty.
Transaction table with loose-end annotations
Section titled “Transaction table with loose-end annotations”Analysis also rebuilds a transaction table — for each TRANID seen in the log range, what state was the transaction in at crash? Active transactions are losers and undo’d. Committed transactions with pending postpones are finished by replaying the postpones. 2PC-prepared transactions are in-doubt and stay alive after restart, waiting for the coordinator’s final decision.
Compensation log records (CLRs)
Section titled “Compensation log records (CLRs)”When an undo applies, it emits a CLR. CLRs are themselves redo-only: their forward-LSA points back at the predecessor of the undo target, so a second crash during undo simply replays the partial undo as forward redo and continues. CLRs have an “undo-next” pointer that the chain walker reads to skip already-undone records.
Fuzzy checkpoints with two log records
Section titled “Fuzzy checkpoints with two log records”A fuzzy checkpoint emits two records: LOG_START_CHKPT (the LSA
recovery analysis will start from) and LOG_END_CHKPT (carrying
the active transaction snapshot, dirty page table, and active
top-ops). Between the two, the engine continues serving traffic;
analysis tolerates the in-flight log records by treating them
the same as records after the checkpoint window.
Parallel redo
Section titled “Parallel redo”ARIES’s redo pass is sequential per-page (any single page must have redo applied in LSN order) but parallel across pages. Modern engines (PostgreSQL 15+, InnoDB, CUBRID) ship a worker pool that bins log records by target VPID and dispatches each bin to a separate worker. The hottest restart-time speedup since ARIES.
Theory ↔ CUBRID mapping
Section titled “Theory ↔ CUBRID mapping”| Theoretical concept | CUBRID name |
|---|---|
| ARIES analysis pass | log_recovery_analysis (log_recovery.c) |
| ARIES redo pass | log_recovery_redo (log_recovery.c) |
| ARIES undo pass | log_recovery_undo (log_recovery.c) |
| Per-record analysis dispatch | log_rv_analysis_record (log_recovery.c) |
| Per-record redo dispatch | log_rv_redo_record_sync<T> template (log_recovery_redo.hpp) |
| Per-record undo dispatch | log_rv_undo_record (log_recovery.c) |
| Recovery function table | RV_fun[] of type struct rvfun { recv_index, recv_string, undofun, redofun, dump_undofun, dump_redofun } (recovery.h) |
| Recovery index enum | LOG_RCVINDEX — RVDK / RVFL / RVHF / RVOVF / RVEH / RVBT prefix families (recovery.h) |
| Recovery argument struct | LOG_RCV { mvcc_id, pgptr, offset, length, data, reference_lsa } (recovery.h) |
| Compensation log record | LOG_COMPENSATE (record type) → LOG_REC_COMPENSATE (struct in log_record.hpp) |
| Compensation function arm | log_rv_get_fun<LOG_REC_COMPENSATE> returns RV_fun[rcvindex].undofun (note: undo, not redo) |
| Fuzzy checkpoint start | LOG_START_CHKPT log record |
| Fuzzy checkpoint end | LOG_END_CHKPT → LOG_REC_CHKPT { redo_lsa, ntrans, ntops } (log_record.hpp) |
| Active-tran snapshot in checkpoint | LOG_INFO_CHKPT_TRANS (log_record.hpp) |
| Active-sysop snapshot in checkpoint | LOG_INFO_CHKPT_SYSOP (log_record.hpp) |
| Checkpoint emission | logpb_checkpoint (log_page_buffer.c) |
| Recovery phase enum | LOG_RECVPHASE { LOG_RESTARTED, ANALYSIS, REDO, UNDO, FINISH_2PC } (log_impl.h) |
| Recovery TDES annotations | LOG_RCV_TDES { sysop_start_postpone_lsa, tran_start_postpone_lsa, atomic_sysop_start_lsa, … } |
| Parallel redo coordinator | log_recovery_redo_parallel.{cpp,hpp} — per-VPID job queue |
| Restart entry point | log_recovery declared in log_recovery.h:37 |
CUBRID’s Approach
Section titled “CUBRID’s Approach”The recovery manager has four moving parts: the entry orchestrator
that drives the three passes, the per-record dispatch templates
that turn (record-type, RCVINDEX) into a function call, the
checkpoint emitter that writes the boundary records the analysis
pass restarts from, and the parallel-redo coordinator that the
modern code path uses to overlap I/O across pages. We walk them in
that order.
Overall structure
Section titled “Overall structure”flowchart TB
RST["log_recovery (entry)"]
subgraph PHASES["Three passes"]
AN["Analysis pass\nlog_recovery_analysis"]
RD["Redo pass\nlog_recovery_redo"]
UN["Undo pass\nlog_recovery_undo"]
FP["Postpone pass\nlog_recovery_finish_all_postpone"]
end
subgraph DISP["Per-record dispatch"]
RA["log_rv_analysis_record\n→ updates DPT, TT"]
RR["log_rv_redo_record_sync<T>\n→ RV_fun[idx].redofun"]
RU["log_rv_undo_record\n→ RV_fun[idx].undofun + emit CLR"]
end
subgraph TBL["RV_fun[] dispatch table"]
F1["RVDK_∗ — disk manager"]
F2["RVFL_∗ — file manager"]
F3["RVHF_∗ — heap manager"]
F4["RVBT_∗ — btree"]
F5["RVEH_∗ — extensible hash"]
F6["..."]
end
RST --> AN --> RD --> FP --> UN
AN --> RA
RD --> RR
UN --> RU
RR --> TBL
RU --> TBL
Figure 1 — Recovery pass structure. log_recovery drives four sequential phases; both redo and undo dispatches bottom out in the RV_fun[] table keyed by rcvindex, routing each record type to its registered redofun or undofun.
The figure encodes the two sequencing decisions of CUBRID’s recovery.
Pass order: analysis → redo → finish-postpone → undo. The
postpone pass sits between redo and undo because postpones are
on-commit deferred actions; they need the database in its
crash-state-restored shape before they can be replayed, but they
must run before undo of any losing transaction starts (otherwise an
undo could roll back a state the postpone needs). Dispatch
shape: every record type leads to one of three callbacks
(analysis-update, redo-apply, undo-apply), and each callback may or
may not consult the global RV_fun[] table. Records that ARIES
calls “logical” — start/end checkpoint, system-op end, savepoints —
are handled inline in the analysis routine without a function-table
hop because their semantics are fixed.
Restart orchestrator
Section titled “Restart orchestrator”The entry point is log_recovery (declared in log_recovery.h:37,
defined in log_recovery.c). It is called from log_initialize
in log_manager.c if the active log header indicates the database
was not cleanly shut down (is_shutdown == false).
// log_recovery — src/transaction/log_recovery.c (sketch)voidlog_recovery (THREAD_ENTRY *thread_p, int ismedia_crash, time_t *stopat){ LOG_LSA start_lsa = log_Gl.hdr.chkpt_lsa; /* most-recent checkpoint */ LOG_LSA start_redolsa = NULL_LSA; LOG_LSA end_redo_lsa = NULL_LSA;
log_Gl.rcv_phase = LOG_RECOVERY_ANALYSIS_PHASE; log_recovery_analysis (thread_p, &start_lsa, &start_redolsa, &end_redo_lsa, ismedia_crash, stopat, /* etc. */);
log_Gl.rcv_phase = LOG_RECOVERY_REDO_PHASE; log_recovery_redo (thread_p, &start_redolsa, &end_redo_lsa);
log_recovery_finish_all_postpone (thread_p);
log_Gl.rcv_phase = LOG_RECOVERY_UNDO_PHASE; log_recovery_undo (thread_p);
log_Gl.rcv_phase = LOG_RESTARTED;}log_Gl.rcv_phase (log_impl.h) is the global recovery-phase enum.
Other modules read it to decide their behaviour during restart —
e.g., the buffer manager skips dirty-tracking checks during redo
because the dirty bits are not yet meaningful.
Analysis pass — rebuild DPT and TT
Section titled “Analysis pass — rebuild DPT and TT”log_recovery_analysis (log_recovery.c:2587) walks forward from
chkpt_lsa reading every record’s header. It maintains:
- A transaction table indexed by TRANID, recording each
transaction’s
head_lsa,tail_lsa, current state, and anyLOG_RCV_TDESannotations (e.g.,analysis_last_aborted_sysop_lsafor nested system ops that aborted but whose end record predates the next system op’s start). - A dirty page table indexed by VPID, recording the LSA at which each page first became dirty after the checkpoint.
The per-record dispatcher is log_rv_analysis_record
(log_recovery.c:2378). Its body is a switch over LOG_RECTYPE
that updates the DPT and TT according to record kind. Examples:
// log_rv_analysis_record — switch arms (sketch from log_recovery.c)switch (log_type) { case LOG_UNDOREDO_DATA: case LOG_MVCC_UNDOREDO_DATA: /* TT: extend tran's tail_lsa, mark TRAN_ACTIVE. DPT: add (vpid, this_lsa) if not present. */ break;
case LOG_COMMIT: /* TT: state = TRAN_UNACTIVE_COMMITTED. */ break;
case LOG_ABORT: /* TT: state = TRAN_UNACTIVE_ABORTED. */ break;
case LOG_SYSOP_END: /* Open sysop bracket closes; LOG_RCV_TDES bookkeeping for logical-undo / logical-compensate / logical-run-postpone arms. */ break;
case LOG_2PC_PREPARE: /* TT: state = TRAN_UNACTIVE_2PC_PREPARE. At end of analysis, this tran is in-doubt — keep, not loser. */ break; case LOG_END_CHKPT: /* If this is a *new* checkpoint within the analysis window, merge its DPT/TT into ours. */ break; case LOG_END_OF_LOG: /* Stop. */ break; // ... condensed ... }At end of analysis, every TRANID is classified: committed, aborted,
loser, or in-doubt. The DPT’s smallest LSA becomes start_redolsa
— the redo pass need not touch anything earlier because no page
was dirty before then.
Redo pass — modern dispatch via templates
Section titled “Redo pass — modern dispatch via templates”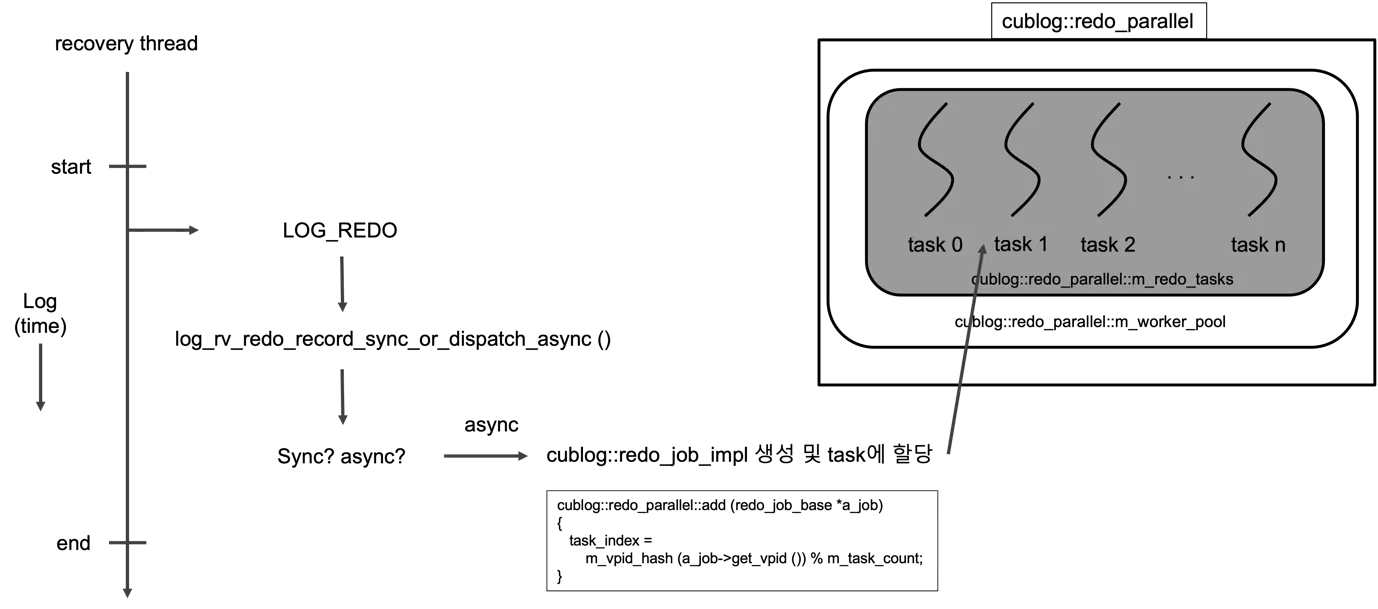
Figure 2 — One recovery thread reads LOG_REDO records in LSA order
along the left timeline. For each record it calls
log_rv_redo_record_sync_or_dispatch_async. If the record’s recovery
function is sync-only the thread applies the change inline; otherwise
it builds a cublog::redo_job_impl and adds it to
cublog::redo_parallel, which hashes by VPID into one of m_redo_tasks
worker threads. The hash partitioning is the property that makes
parallel redo correct without per-page locks: every record touching a
given page lands on the same worker, so per-page LSA monotonicity is
preserved while disjoint pages overlap freely. (Source:
recovery manager_v0.2.docx, redo dispatch figure.)
The redo pass walks forward from start_redolsa. For every record
that updates a page (LOG_*UNDOREDO_DATA, LOG_REDO_DATA,
LOG_MVCC_*, LOG_RUN_POSTPONE, LOG_COMPENSATE), it must:
- Fix the target page in the buffer pool.
- Compare
page.lsawithrecord.lsa. Ifpage.lsa >= record.lsa, the change is already on disk — skip. Otherwise apply. - Apply by calling
RV_fun[record.rcvindex].redofun (rcv). - Set
page.lsa = record.lsa, mark dirty. - Unfix.
CUBRID expresses this as a templated dispatcher
log_rv_redo_record_sync<T> in log_recovery_redo.hpp. The template
parameter T is the log record’s typed payload (LOG_REC_UNDOREDO,
LOG_REC_MVCC_UNDOREDO, LOG_REC_REDO, LOG_REC_COMPENSATE, etc.),
and per-T specialisations of log_rv_get_log_rec_data<T>,
log_rv_get_log_rec_redo_length<T>, log_rv_get_log_rec_offset<T>,
log_rv_get_log_rec_mvccid<T>, and log_rv_get_fun<T> extract the
fields that vary by record kind.
// log_rv_redo_record_sync<T> — src/transaction/log_recovery_redo.hpp (condensed)template <typename T>voidlog_rv_redo_record_sync (THREAD_ENTRY *thread_p, log_rv_redo_context &redo_context, const log_rv_redo_rec_info<T> &record_info, const VPID &rcv_vpid){ const LOG_DATA &log_data = log_rv_get_log_rec_data<T> (record_info.m_logrec);
LOG_RCV rcv; if (!log_rv_fix_page_and_check_redo_is_needed (thread_p, rcv_vpid, rcv, log_data.rcvindex, record_info.m_start_lsa, redo_context.m_end_redo_lsa)) return; /* page.lsa >= record.lsa, no work */
rcv.length = log_rv_get_log_rec_redo_length<T> (record_info.m_logrec); rcv.mvcc_id = log_rv_get_log_rec_mvccid<T> (record_info.m_logrec); rcv.offset = log_rv_get_log_rec_offset<T> (record_info.m_logrec);
log_rv_get_log_rec_redo_data<T> (thread_p, redo_context, record_info, rcv);
rvfun::fun_t redofunc = log_rv_get_fun<T> (record_info.m_logrec, log_data.rcvindex); redofunc (thread_p, &rcv);
pgbuf_set_lsa (thread_p, rcv.pgptr, &record_info.m_start_lsa);}There is a subtle but load-bearing specialisation worth marking up.
For LOG_REC_COMPENSATE (the CLR), log_rv_get_fun returns
RV_fun[rcvindex].undofun, not redofun:
// log_rv_get_fun specialisation — src/transaction/log_recovery_redo.hpp:396template <>inline rvfun::fun_tlog_rv_get_fun<LOG_REC_COMPENSATE> (const LOG_REC_COMPENSATE &, LOG_RCVINDEX rcvindex){ // yes, undo return RV_fun[rcvindex].undofun;}The “yes, undo” comment is in the source. The reason: a CLR’s payload is the undo image of an action that previously rolled back. When recovery encounters a CLR during redo, it must apply that undo image forward to restore the post-undo state. The function table’s undo arm carries the right behaviour; redo would re-apply the original change. Mistakes here are how engines lose data during double-fault recovery.
The recovery dispatch table
Section titled “The recovery dispatch table”RV_fun[] (recovery.h:234) is the central dispatch table. Each
entry is:
// struct rvfun — src/transaction/recovery.hstruct rvfun{ using fun_t = int (*)(THREAD_ENTRY *thread_p, LOG_RCV *logrcv); using dump_fun_t = void (*)(FILE *fp, int length, void *data);
LOG_RCVINDEX recv_index; /* For verification — must equal the array index */ const char *recv_string; /* For debug logging */ fun_t undofun; fun_t redofun; dump_fun_t dump_undofun; dump_fun_t dump_redofun;};The recovery argument struct passed to the functions:
// LOG_RCV — src/transaction/recovery.hstruct log_rcv{ MVCCID mvcc_id; PAGE_PTR pgptr; /* Page to recover; recovery functions must not free but must mark dirty when needed. */ PGLENGTH offset; /* Offset/slot in pgptr */ int length; const char *data; /* Replacement data; pointer becomes invalid after the call */ LOG_LSA reference_lsa; /* For compensate / postpone — the related LSA */};The LOG_RCVINDEX enum (recovery.h:36) is grouped by subsystem:
| Prefix | Subsystem | Example |
|---|---|---|
| RVDK_ | Disk manager (volumes, sectors) | RVDK_FORMAT, RVDK_RESERVE_SECTORS |
| RVFL_ | File manager (extents, file headers) | RVFL_ALLOC, RVFL_DEALLOC, RVFL_EXTDATA_* |
| RVHF_ | Heap file manager | RVHF_INSERT, RVHF_MVCC_INSERT, RVHF_UPDATE |
| RVOVF_ | Heap overflow records | RVOVF_NEWPAGE_INSERT, RVOVF_PAGE_UPDATE |
| RVEH_ | Extensible hash (older index type) | RVEH_INSERT, RVEH_DELETE |
| RVBT_ | B+Tree | RVBT_NDHEADER_UPD, RVBT_NDRECORD_INS, etc. |
The RCV_IS_BTREE_LOGICAL_LOG macro (recovery.h:241) flags the
B+Tree indices whose logging is logical rather than physical —
those need different handling because the page state at undo time
may not match what physical undo would assume. The list includes
RVBT_DELETE_OBJECT_PHYSICAL, RVBT_MVCC_DELETE_OBJECT,
RVBT_MVCC_INSERT_OBJECT, and friends.
Undo pass — walk loser chains backward
Section titled “Undo pass — walk loser chains backward”log_recovery_undo (log_recovery.c:4418) iterates the loser
transactions identified by analysis. For each, it walks the
prev_tranlsa chain backward from the transaction’s tail_lsa,
calling log_rv_undo_record (log_recovery.c:163) on each
undo-eligible record. Each undo emits a CLR. When the chain hits
the transaction’s head_lsa (or a LOG_SYSOP_END_LOGICAL_UNDO
that handles a logical-undo system op), the transaction is marked
TRAN_UNACTIVE_UNILATERALLY_ABORTED.
The CLR’s undo_nxlsa field (in LOG_REC_COMPENSATE) points at
the predecessor of the just-undone record — so a re-crash during
undo simply replays the partial CLR chain forward in the next redo
pass and resumes from the right place. This is the
“undo-is-itself-redoable” property ARIES is named for.
Postpone pass — replay deferred actions
Section titled “Postpone pass — replay deferred actions”log_recovery_finish_all_postpone (log_recovery.c:4243) handles
the in-between case: transactions that committed but had postpone
operations queued. Postpones are deferred actions that run after
commit (e.g., catalog cleanups, file decrement counters) and are
recovery-discoverable: each emits a LOG_POSTPONE record before
commit, and the commit emits LOG_COMMIT_WITH_POSTPONE to mark
that postpones are pending.
The pass walks each TT entry in the relevant state
(TRAN_UNACTIVE_COMMITTED_WITH_POSTPONE,
TRAN_UNACTIVE_TOPOPE_COMMITTED_WITH_POSTPONE), runs its postpones
to completion, then transitions to TRAN_UNACTIVE_COMMITTED.
Checkpoint — the boundary the next analysis starts from
Section titled “Checkpoint — the boundary the next analysis starts from”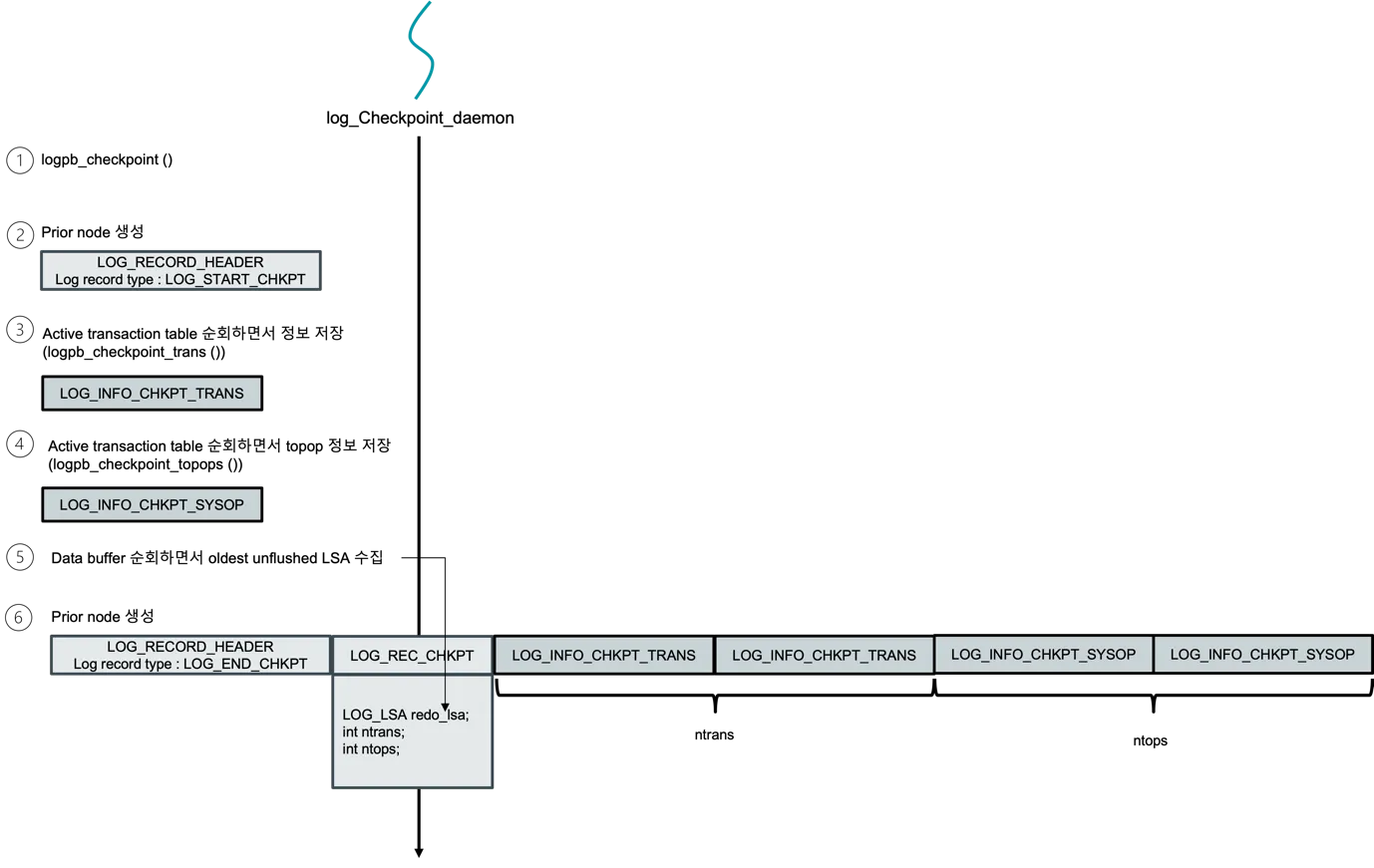
Figure 3 — The numbered timeline log_Checkpoint_daemon follows on
each tick. ① Call logpb_checkpoint. ② Emit a LOG_START_CHKPT
record — its LSA is the chkpt_lsa the next restart will analyse
from. ③ Walk the active transaction table, emitting one
LOG_INFO_CHKPT_TRANS per live TDES via logpb_checkpoint_trans. ④
Walk the active system-op stack, emitting one LOG_INFO_CHKPT_SYSOP
each via logpb_checkpoint_topops. ⑤ Walk the page-buffer dirty list
to find the smallest unflushed LSA — the redo-LSA hint that lets the
next analysis pass skip everything below it. ⑥ Emit LOG_END_CHKPT
followed by a packed LOG_REC_CHKPT payload (redo_lsa, ntrans, ntops,
plus the per-tran/per-sysop arrays). The fuzzy property is that steps
③–⑤ run without freezing the trantable — that’s why this is “fuzzy”
checkpointing rather than the textbook quiescent variant. (Source:
recovery manager_v0.2.docx, checkpoint daemon figure.)
Checkpoints are emitted by logpb_checkpoint (log_page_buffer.c:6877),
called by the checkpoint daemon on a configurable interval
(chkpt_every_npages in LOG_GLOBAL). The procedure is the
fuzzy variant:
- Acquire read mode on the trantable critical section so transactions continue running.
- Append
LOG_START_CHKPT. Its LSA becomes thechkpt_lsarecovery will analyse from on the next restart. - Walk the trantable, building a
LOG_INFO_CHKPT_TRANSsnapshot per active TDES (head/tail LSA, undo-next LSA, postpone-next LSA, savepoint LSA, state, user). This is whatlogpb_checkpoint_trans(log_page_buffer.c:6783) does. - Walk active system ops, building
LOG_INFO_CHKPT_SYSOPsnapshots —logpb_checkpoint_topops(log_page_buffer.c:6833). - Walk the buffer manager’s dirty page list, capturing each
dirty page’s
(vpid, recovery_lsa)pair. The smallest of these becomes the redo-LSA hint. - Append
LOG_END_CHKPTwithLOG_REC_CHKPT { redo_lsa, ntrans, ntops }followed by the trans/topops/dpt arrays. - Force-flush the log so both records are durable.
- Update
log_Gl.hdr.chkpt_lsato the start record’s LSA and force-flush the log header.
Crucial property: between step 2 and step 6, transactions continue
making progress and writing log records. Analysis tolerates this
by reading LOG_END_CHKPT first and then re-walking from the
start record forward — any record in the window is processed
the same as a record after the checkpoint.
Parallel redo — overlap I/O across pages
Section titled “Parallel redo — overlap I/O across pages”log_recovery_redo_parallel.{cpp,hpp} is the modern code path for
the redo pass. Its core insight: redo on a single page must be
sequential (LSN order), but redo across pages is
embarrassingly parallel. The coordinator maintains a per-VPID job
queue, dispatches jobs to a thread pool (size configurable), and
uses page-fix as the natural synchronisation primitive — multiple
workers cannot fix the same page concurrently, so the buffer
manager serialises work on contended pages.
The performance counter scaffolding in
log_recovery_redo_perf.hpp (PSTAT_LOG_REDO_FUNC_EXEC,
perfmon_counter_timer_raii_tracker) reports per-redo timing for
both this restart-time path and the page-server replication path
(which uses the same dispatcher).
Three-pass timeline
Section titled “Three-pass timeline”sequenceDiagram participant LR as log_recovery participant AN as log_recovery_analysis participant RD as log_recovery_redo participant FP as log_recovery_finish_all_postpone participant UN as log_recovery_undo participant DK as Disk Note over LR: server start, hdr.is_shutdown == false LR->>AN: walk from chkpt_lsa AN->>DK: read log records AN-->>LR: TT, DPT, start_redolsa, end_redo_lsa LR->>RD: redo from start_redolsa to end_redo_lsa RD->>DK: fix-and-apply per record (parallel by VPID) LR->>FP: finish committed-with-postpone trans FP->>DK: replay postpones LR->>UN: undo loser trans UN->>DK: walk prev_tranlsa, apply undofun, emit CLR Note over LR: rcv_phase = LOG_RESTARTED
Figure 4 — Three-pass restart timeline. log_recovery serialises analysis → redo → finish-postpone → undo; the redo pass reads log records and applies them to disk pages in parallel, while undo walks each loser transaction’s prev_tranlsa chain backward and emits CLRs.
Source Walkthrough
Section titled “Source Walkthrough”Anchor on symbol names, not line numbers.
Restart entry
Section titled “Restart entry”log_recovery(log_recovery.h, defined inlog_recovery.c) — three-pass driver.log_Gl.rcv_phaseof typeLOG_RECVPHASE(log_impl.h) — global phase indicator.log_recovery_resetlog(log_recovery.c) — used after successful recovery to truncate the log to the new append LSA.
Analysis pass
Section titled “Analysis pass”log_recovery_analysis(log_recovery.c) — forward walk from checkpoint.log_rv_analysis_record(log_recovery.c) — switch over record type updating TT and DPT.LOG_INFO_CHKPT_TRANS/LOG_INFO_CHKPT_SYSOP(log_record.hpp) — checkpoint snapshot entries the analysis reads to bootstrap.
Redo pass
Section titled “Redo pass”log_recovery_redo(log_recovery.c) — forward walk from start_redo_lsa.log_rv_redo_record_sync<T>(log_recovery_redo.hpp) — per-record-type templated dispatcher.log_rv_get_fun<T>(log_recovery_redo.hpp) — selectsredofunorundofundepending on record kind (CLRs use undo).log_rv_fix_page_and_check_redo_is_needed(log_recovery.h, defined inlog_recovery.c) — the LSN comparison that decides whether to apply.log_rv_get_log_rec_redo_data<T>(log_recovery_redo.hpp) — unzip + diff-merge forLOG_DIFF_UNDOREDO_DATA.log_recovery_redo_parallel.{cpp,hpp}— per-VPID job queue and worker pool.
Undo pass
Section titled “Undo pass”log_recovery_undo(log_recovery.c).log_rv_undo_record(log_recovery.c) — per-record undo dispatcher; emits CLR.log_rv_get_unzip_log_data(log_recovery.c, declared inlog_recovery.h) — decompression of compressed undo records.
Postpone pass
Section titled “Postpone pass”log_recovery_finish_all_postpone(log_recovery.c).log_do_postpone(log_manager.c) — the runtime postpone driver that the recovery pass also uses.
Checkpoint
Section titled “Checkpoint”logpb_checkpoint(log_page_buffer.c) — fuzzy checkpoint emitter.logpb_checkpoint_trans(log_page_buffer.c) — per-TDES snapshot.logpb_checkpoint_topops(log_page_buffer.c) — per-sysop snapshot.logpb_dump_checkpoint_trans(log_page_buffer.c) — debug dump of the snapshot forcubrid logdump.
Recovery dispatch
Section titled “Recovery dispatch”RV_fun[](recovery.h) — dispatch table.LOG_RCVINDEXenum (recovery.h).LOG_RCVstruct (recovery.h).RCV_IS_BTREE_LOGICAL_LOGmacro (recovery.h).rv_check_rvfuns(recovery.h) — debug-build invariant checker that assertsRV_fun[i].recv_index == ifor every entry.
Position hints as of 2026-04-30
Section titled “Position hints as of 2026-04-30”| Symbol | File | Line |
|---|---|---|
log_recovery (declaration) | log_recovery.h | 37 |
log_rv_analysis_record | log_recovery.c | 2378 |
log_recovery_analysis | log_recovery.c | 2587 |
log_recovery_redo | log_recovery.c | 3251 |
log_recovery_finish_all_postpone | log_recovery.c | 4243 |
log_recovery_undo | log_recovery.c | 4418 |
log_recovery_resetlog | log_recovery.c | 5221 |
log_rv_redo_record | log_recovery.c | 430 |
log_rv_undo_record | log_recovery.c | 163 |
log_rv_redo_record_modify | log_recovery.c | 6173 |
log_rv_undo_record_modify | log_recovery.c | 6191 |
log_rv_redo_record_sync<T> (tmpl) | log_recovery_redo.hpp | 587 |
log_rv_get_fun<LOG_REC_COMPENSATE> | log_recovery_redo.hpp | 396 |
log_rv_redo_context | log_recovery_redo.hpp | 33 |
LOG_RCV struct | recovery.h | 195 |
struct rvfun | recovery.h | 221 |
LOG_RCVINDEX enum | recovery.h | 36 |
RCV_IS_BTREE_LOGICAL_LOG macro | recovery.h | 241 |
logpb_checkpoint | log_page_buffer.c | 6877 |
logpb_checkpoint_trans | log_page_buffer.c | 6783 |
logpb_checkpoint_topops | log_page_buffer.c | 6833 |
LOG_REC_CHKPT struct | log_record.hpp | 345 |
LOG_INFO_CHKPT_TRANS struct | log_record.hpp | 354 |
LOG_INFO_CHKPT_SYSOP struct | log_record.hpp | 372 |
Source verification (as of 2026-04-30)
Section titled “Source verification (as of 2026-04-30)”Verified facts
Section titled “Verified facts”-
The pass order is analysis → redo → postpone → undo, not analysis → redo → undo as the textbook ARIES suggests. Verified in
log_recoverybody (sketched above) and the explicitlog_recovery_finish_all_postponecall. The departure from textbook order is intentional: postpones reify deferred actions of committed transactions, so they must complete before undo of losers could roll back state the postpones depend on. -
Compensation log records in redo dispatch use the undo function from
RV_fun[], not the redo function. Verified atlog_recovery_redo.hpp:396-401— the inline comment in the source is “yes, undo”. The reason is that a CLR’s payload is the undo image of a previously-rolled-back action, and replaying it forward during redo means re-applying that undo, which is what the undo arm does. -
Per-record dispatch in redo is templated by record-payload type, not by
LOG_RECTYPE. Verified inlog_recovery_redo.hpp— thelog_rv_redo_record_sync<T>primary template plus per-Tspecialisations forLOG_REC_UNDOREDO,LOG_REC_MVCC_UNDOREDO,LOG_REC_REDO,LOG_REC_MVCC_REDO,LOG_REC_RUN_POSTPONE,LOG_REC_COMPENSATE. Compile-time dispatch eliminates the runtime payload-shape check in the hot redo loop. -
The recovery argument struct
LOG_RCVdeletes its copy and move operations. Verified atrecovery.h:208-213. Implication: recovery functions take it by pointer; ownership ofdatais borrowed and invalidated when the surrounding scope ends. The source comment is explicit: “Pointer becomes invalid once the recovery of the data is finished”. -
Checkpoints are fuzzy:
LOG_START_CHKPTandLOG_END_CHKPTare separate records. Verified by readinglogpb_checkpointand observingLOG_START_CHKPTis appended before the trans/topops/DPT enumeration andLOG_END_CHKPTafter. The globallog_Gl.hdr.chkpt_lsaadvances to the start record’s LSA. -
Active log header has separate
chkpt_lsaandsmallest_lsa_at_last_chkpt. Verified atlog_storage.hpp:141andlog_storage.hpp:163. The first is the recovery start point; the second is used as a watermark for archive removal (no archive containing pages below it is needed for crash recovery). -
The recovery-time TDES annotations are stored inside the TDES, not in a separate map. Verified at
log_impl.h:558(LOG_TDES::rcvfield of typeLOG_RCV_TDES). The annotations carrysysop_start_postpone_lsa,tran_start_postpone_lsa,atomic_sysop_start_lsa,analysis_last_aborted_sysop_lsaand_start_lsa. They are populated only during analysis and consumed by the later passes. -
The recovery dispatch table is statically defined; adding a new
LOG_RCVINDEXrequires registering both undo and redo function pointers. Verified byrecovery.h:221-234(struct definition + extern declaration) andrv_check_rvfunsdebug invariant. The check enforces thatRV_fun[i].recv_index == i, so reordering or skipping is caught at startup. -
Parallel redo dispatches by VPID, not by transaction. Inferred from the existence of
log_recovery_redo_parallel.cpp(30 KB) plus the per-page LSN-order constraint in ARIES. Page-fix in the buffer manager is the natural serialisation — multiple workers cannot fix the same page concurrently. -
The same redo dispatcher is used for crash recovery and for page-server replication. Verified by the comment in
log_recovery_redo.hpp:638-643: “perf data for actually calling the log redo function; it is relevant in two contexts: log recovery redo after a crash (either synchronously or using the parallel infrastructure); log replication on the page server”.
Open questions
Section titled “Open questions”-
Parallel-redo worker pool size. Configurable parameter name and default value were not located in this pass. Investigation path: read
log_recovery_redo_parallel.cpp’s constructor; checksystem_parameter.{c,h}for aPRM_ID_LOG_RECOVERY_*parameter. -
Checkpoint frequency knob.
LOG_GLOBAL::chkpt_every_npagesexists but its server parameter binding was not traced. Investigation path: search forchkpt_every_npageswriters. -
Behaviour when checkpoint and crash interleave. If a crash occurs between
LOG_START_CHKPTandLOG_END_CHKPT, the end record is missing. What does analysis do? Skip the partial checkpoint and use the previous one? Or treat the start record as the recovery boundary anyway? Investigation path: tracelog_rv_analysis_recordarms forLOG_START_CHKPTandLOG_END_CHKPT. -
In-doubt 2PC transaction recovery. The fifth phase
LOG_RECOVERY_FINISH_2PC_PHASEis named inlog_impl.h:631but does not appear in thelog_recoverydriver sketched above. Where is it run? Investigation path: search forLOG_RECOVERY_FINISH_2PC_PHASEwriters; cross-reference withcubrid-2pc.md. -
Page-server replication path interaction. The redo dispatcher is shared with page-server replication, but the division of responsibility between recovery and replication wasn’t traced. Investigation path: search for callers of
log_rv_redo_record_syncoutsidelog_recovery.c. -
TDE-encrypted log pages during recovery. The redo path must decrypt before applying. Where exactly does decryption happen — in
log_reader::fetch_page_with_buffer, or downstream in the dispatcher? Investigation path: readlog_reader.cppand grep fortde_decryptcalls.
Beyond CUBRID — Comparative Designs & Research Frontiers
Section titled “Beyond CUBRID — Comparative Designs & Research Frontiers”Pointers, not analysis. Each bullet is a starting handle for a follow-up doc.
-
PostgreSQL recovery (
xlog.c) — single-pass design that combines analysis and redo. Loser undo is unnecessary because PostgreSQL transactions are versioned via MVCC and committed state is encoded inline. CUBRID retains the three-pass model because heap-side undo records (e.g., file-allocation rollback) cannot be expressed as MVCC versions. -
InnoDB recovery (
recv_recovery_*) — two-pass: scan + redo, with rollback handled by backgroundpurgerather than a dedicated undo pass. Themtr_tmini-transaction provides atomic groups much like CUBRID’s system ops. -
ARIES original (Mohan et al., TODS 17.1, 1992) — the canonical reference. CUBRID’s CLR semantics, fuzzy checkpoint, and three-pass restart are a faithful implementation. The parallel-redo and
log_rv_redo_record_sync<T>template are modern additions ARIES did not contemplate. -
Silo recovery (Tu et al., SOSP 2013) — epoch-based recovery that batches commit per-epoch and replays the per-epoch log range without LSN ordering. CUBRID’s per-page LSN order is an explicit non-goal in Silo. A side-by-side would highlight what is sacrificed for parallelism.
-
Aurora’s offload-WAL recovery (Verbitski et al., SIGMOD 2017) — recovery happens at the storage layer, not at the compute node. The compute node restart is consequently fast (no log scan). CUBRID is process-local; this is a structural contrast.
-
Snapshot Isolation Serializability under recovery (Cahill, Ports, et al.) — for SERIALIZABLE workloads, recovery must re-establish predicate-lock state. CUBRID’s SERIALIZABLE relies on the lock manager not the recovery manager, so this is more a non-issue than a feature; comparison with PG SSI’s recovery side would document the difference.
Sources
Section titled “Sources”Raw analyses (raw/code-analysis/cubrid/storage/recovery_manager/)
Section titled “Raw analyses (raw/code-analysis/cubrid/storage/recovery_manager/)”Recovery_manager_v0.6.pptxrecovery manager_v0.2.pdfrecovery manager_v0.2.docxlog_manager_v0.3.pptx(filed in this folder; covers the log-side whichcubrid-log-manager.mdmines).
Textbook chapters (under knowledge/research/dbms-general/)
Section titled “Textbook chapters (under knowledge/research/dbms-general/)”- Database Internals (Petrov), Ch. 5 §“ARIES” and §“Recovery Algorithm”.
- Mohan, Haderle, Lindsay, Pirahesh, Schwarz, ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging, TODS 17.1, 1992.
CUBRID source (/data/hgryoo/references/cubrid/)
Section titled “CUBRID source (/data/hgryoo/references/cubrid/)”src/transaction/log_recovery.{c,h}src/transaction/log_recovery_redo.{cpp,hpp}src/transaction/log_recovery_redo_parallel.{cpp,hpp}src/transaction/log_recovery_redo_perf.hppsrc/transaction/recovery.hsrc/transaction/log_page_buffer.c(checkpoint).src/transaction/log_compress.{c,h}(decompression during redo).
Sibling docs in this knowledge base
Section titled “Sibling docs in this knowledge base”knowledge/code-analysis/cubrid/cubrid-log-manager.md— the log this manager reads.knowledge/code-analysis/cubrid/cubrid-transaction.md— the TDES whose state recovery rebuilds.knowledge/code-analysis/cubrid/cubrid-mvcc.md— MVCCID handling inside MVCC-flavoured records during redo.knowledge/code-analysis/cubrid/cubrid-2pc.md— in-doubt path theLOG_RECOVERY_FINISH_2PC_PHASEarm handles; in-progress in the same batch.knowledge/code-analysis/cubrid/cubrid-page-buffer-manager.md— data-page side of the WAL invariant the redo pass restores.