CUBRID Lock Manager — Multi-Granularity Locking, Conversion, and Deadlock Detection
Contents:
- Theoretical Background
- Common DBMS Design
- CUBRID’s Approach
- Source Walkthrough
- Source verification (as of 2026-04-29)
- Beyond CUBRID — Comparative Designs & Research Frontiers
- Sources
Theoretical Background
Section titled “Theoretical Background”A lock manager is the component that enforces logical serialization between transactions by granting and revoking locks on database objects. Database Internals (Petrov, ch. 5) is careful to distinguish locks from latches: locks protect transactional data integrity, are held for transaction duration, and are stored outside the data structure itself; latches protect physical structure (e.g., a page during a B-tree split) and are short-lived. CUBRID’s lock manager is the lock side; the page buffer’s PGBUF latches are the latch side.
The classical lock-based concurrency control protocol is two-phase locking (2PL): every transaction has a growing phase in which it may acquire locks, followed by a shrinking phase in which it may release them, with no further acquisitions allowed once any lock has been released. 2PL guarantees serializable schedules. The textbook also notes the structural cost of 2PL — contention and deadlocks — and the standard remedies: timeouts, conservative 2PL (acquire all locks up front), or a waits-for graph maintained by the transaction manager that is periodically scanned for cycles, with one transaction per cycle aborted as the deadlock victim ([WEIKUM01]). Avoidance schemes that use transaction timestamps (wait-die, wound-wait; [RAMAKRISHNAN03]) are an alternative to detection. CUBRID uses detection via a waits-for graph plus timeout as a fallback.
Two more theoretical building blocks shape the implementation:
- Lock modes and a compatibility matrix. Beyond shared (S) and
exclusive (X), real systems add intention modes (IS, IX, SIX) for
multi-granularity locking — taking a coarse lock at one level
(e.g., table) implies you are about to take finer locks at a deeper
level (e.g., row). Intention modes let two transactions both lock
different rows of the same table without false conflict at the
table level. CUBRID extends this set with
BU(bulk update),SCH-S/SCH-M(schema stability/modification), and a specialNON_2PLmarker. - Lock conversion. A transaction holding a lock in mode A that
requests mode B is granted the least upper bound of the two —
e.g.,
S + IX = SIX. A square conversion table replaces a search over per-mode rules.
The rest of this document tracks how CUBRID realizes these two pieces
plus the waits-for-graph deadlock detector in
src/transaction/lock_manager.{h,c}.
Common DBMS Design
Section titled “Common DBMS Design”The textbook gives 2PL, multi-granularity locking, and the waits-for
graph; this section names the engineering conventions almost every
DBMS lock manager (Oracle, MySQL InnoDB, SQL Server, PostgreSQL,
CUBRID) adopts in some form. CUBRID’s specific choices in
## CUBRID's Approach are best read as one set of dials within this
shared design space, not as inventions.
Lock vs latch separation
Section titled “Lock vs latch separation”Locks are logical: tied to a transaction, externalized in a lock
table, durable in their effect on serialization order. Latches are
physical: short, embedded in pages or in-memory structures,
guarding against concurrent corruption. Almost every modern DBMS has
both. Conflating them produces the wrong design — you end up either
holding logical locks during low-level page work, or guarding
transaction state with latches. CUBRID’s LK_ENTRY is the lock side;
the page buffer’s PGBUF_LATCH is the latch side.
Resource hashing
Section titled “Resource hashing”Lockable resources live in a hash table keyed by some object
identifier. The identifier shape varies — OID (volid, pageid, slotid) in CUBRID, page+slot+xid range in Oracle, a descriptor of
(relation, key range) for predicate locking in PostgreSQL. The
per-resource state is a list of holders plus a list of waiters.
Aggregate-mode cache
Section titled “Aggregate-mode cache”A naive compatibility check is O(holders): walk the list and
intersect modes. The standard optimization is to cache the
aggregate of all granted modes (total_holders_mode) and of all
waiting modes (total_waiters_mode) on the resource record itself,
turning the check into one matrix lookup. CUBRID does this; Oracle
calls the equivalent the consolidated mode; the pattern recurs.
Dual-view threading
Section titled “Dual-view threading”The same lock fact is queried from two angles: per-resource (“who
holds R?”) and per-transaction (“what does T hold?”). The cleanest
implementation is one record threaded into both lists — the lock
table indexes the resource view, and a per-transaction table indexes
the transaction view, but a single struct carries both sets of
pointers. CUBRID’s LK_ENTRY is the canonical example.
Multi-granularity locking + intention modes
Section titled “Multi-granularity locking + intention modes”Gray’s hierarchy: IS, IX, S, SIX, X. Taking a coarse lock
implies you are about to take finer locks underneath, and intention
modes let two transactions lock different rows of the same table
without false conflict at the table level. The compatibility matrix
grows from 2×2 (S, X) to 5×5 or 7×7. CUBRID extends the vocabulary to
12 modes by adding BU (bulk update), SCH-S / SCH-M (schema
stability / modification), U (update), and a NON2PL marker for
released-early locks.
Lock conversion via square table
Section titled “Lock conversion via square table”Re-requesting a lock you already hold should upgrade, not deadlock
with yourself. The new mode is the least upper bound of held and
requested — S + IX = SIX, IS + S = S, etc. Engines either compute
this on the fly or look it up in a square table indexed by (held, requested). CUBRID uses a table.
FIFO wait queue + starvation guard
Section titled “FIFO wait queue + starvation guard”Granting based on holders alone allows a steady stream of S
requests to starve a waiting X. The standard fix: the grant test
is holders ∧ waiters compat — a new request must clear both the
currently-granted aggregate and the currently-waiting aggregate.
CUBRID enforces this; PostgreSQL has the same pattern.
Deadlock handling: three schools
Section titled “Deadlock handling: three schools”- Timeout (cheap, false-positive prone). Used as a fallback in most engines, including CUBRID.
- Waits-for graph cycle scan (CUBRID, MySQL InnoDB). A background detector walks the WFG, breaks cycles by aborting a victim. Ordering choices: youngest, most-recently-blocked, fewest locks held, etc.
- Timestamp-based avoidance — wait-die, wound-wait. Textbook classic; less common in production because it interacts poorly with long-running analytics.
Isolation level — three axes, not one
Section titled “Isolation level — three axes, not one”A common shorthand says “isolation = lock duration”: Read Committed
releases per statement, RR/Serializable hold to commit. That shorthand
is accurate for a pure 2PL engine but misleading for an MVCC engine
like CUBRID, because the dominant mechanism for reader isolation
is not lock duration at all. CUBRID encodes isolation along three
axes; each operates on a specific subset of classes and a specific
phase of statement execution. The precise scoping comes straight from
two predicate functions that gate the relevant branches:
mvcc_is_mvcc_disabled_class (src/transaction/mvcc.c) and
logtb_check_class_for_rr_isolation_err
(src/transaction/log_tran_table.c).
The two predicates partition all classes for the purpose of isolation dispatch:
- MVCC-disabled set.
mvcc_is_mvcc_disabled_classreturns true for only four kinds of class: the root class (OID_IS_ROOTOID), serial classes (oid_is_serial), the collation class (OID_CACHE_COLLATION_CLASS_ID), and the HA apply-info class (OID_CACHE_HA_APPLY_INFO_CLASS_ID). Everything else, including most of the system catalog (_db_class,_db_attribute, etc.) and all user tables, is MVCC-enabled. - RR-conflict-eligible set.
logtb_check_class_for_rr_isolation_errreturns false (skip the RR/SERIALIZABLE conflict check) for three metadata classes:_db_root,_db_user,_db_trigger. Returns true for everything else.
With that partition fixed, the three axes are:
- Visibility axis (MVCC snapshot timing). Which committed version
a reader sees is decided by when the transaction’s snapshot is
taken. READ COMMITTED rebuilds a fresh snapshot per statement;
REPEATABLE READ and SERIALIZABLE both keep the snapshot taken at
transaction start. Applies to MVCC-enabled classes, which is most
classes. See
cubrid-mvcc.md, §“Snapshot acquisition timing is the isolation knob”. - Locking axis — MVCC-disabled classes only. The four MVCC-disabled
class kinds are the only classes for which instance row locks
participate in isolation. For these, under READ COMMITTED the S
locks are short-duration (released when the acquiring statement
finishes, tracked in
non2plfor later re-read conflict detection); under REPEATABLE READ / SERIALIZABLE the same S locks are held to commit. In practice, the scan-time S-lock path on these classes is exercised only for serials:scan_manager.ctakesS_LOCKon instance OIDs only inside theif (mvcc_disabled_class && oid_is_serial)arm. - First-updater-wins write-conflict axis (RR/SERIALIZABLE,
MVCC-enabled, RR-eligible). On UPDATE / DELETE of a row in a class
that is MVCC-enabled and not in the metadata-exempt set, if the
isolation level is greater than READ COMMITTED, the engine performs
a snapshot-vs-current-version check before applying the write. If
the version visible to our snapshot is no longer the latest
(another transaction modified the row after our snapshot was taken),
the engine raises
ER_MVCC_SERIALIZABLE_CONFLICTand aborts the operation. The check sits inlocator_sr.c, immediately after the comment/* Check REPEATABLE READ/SERIALIZABLE isolation restrictions. */. This is first-updater-wins write-conflict detection on the write path; it acquires no new locks and does no range locking.
Three properties that the textbook shorthand obscures, and that fall out of reading the source directly:
- Plain MVCC SELECT readers acquire no instance row locks, on any
isolation level.
scan_manager.centers thelock_objectbranch only insideif (hsidp->scan_cache.mvcc_disabled_class), and even there the S-lock arm fires only for serials. The MVCC-table branch oflock_unlock_object_by_isolationis a no-op with the comment “READ COMMITTED isolation uses snapshot instead of locks. We don’t have to release anything here.” - Write-path X locks are long-duration under every isolation level,
including READ COMMITTED.
lock_unlock_objectshort-circuits with/* These will not be released. */for any mode that is notS_LOCK. The X locks an INSERT / UPDATE / DELETE acquires on its target rows are held to commit regardless of isolation. - REPEATABLE READ and SERIALIZABLE are runtime-identical for MVCC
operations. No code path in the server source dispatches on
TRAN_SERIALIZABLEwithout also dispatching identically onTRAN_REPEATABLE_READ; every isolation-sensitive branch uses the patternisolation > TRAN_READ_COMMITTEDorisolation == TRAN_REPEATABLE_READ || isolation == TRAN_SERIALIZABLE. The two levels share snapshot timing (Axis 1), share lock duration on MVCC-disabled classes (Axis 2), and share the first-updater-wins check (Axis 3). CUBRID’s user-facingSERIALIZABLElevel is honestly Snapshot Isolation; the alias ofTRAN_SERIALIZABLEtoTRAN_NO_PHANTOM_READ(compat/dbtran_def.h) reflects the actual guarantee — phantoms within a snapshot are prevented by the snapshot, but write skew is not prevented because there is no SSI conflict graph.
Class and schema locks are always long-duration regardless of isolation level (intention locks must outlive their children).
Theory ↔ CUBRID mapping
Section titled “Theory ↔ CUBRID mapping”The textbook concepts of §“Theoretical Background” map to CUBRID’s
named entities as follows. ## CUBRID's Approach is the slow zoom
into each row.
| Theory | CUBRID name |
|---|---|
| Lockable resource | LK_RES keyed by LK_RES_KEY{type, OID, class_OID} |
| Held / pending lock instance | LK_ENTRY (granted_mode + blocked_mode) |
| Lock modes (S / X + intention modes) | 12-mode vocabulary in lock_table.h (NA…SCH-M) |
| Compatibility matrix | 12×12 (NA, NON2PL, U omitted in printed table) lookup driven by total_holders_mode / _waiters_mode |
| Conversion (lub of held + requested) | square table in lock_table.c consulted on re-request |
| Per-transaction state | LK_TRAN_LOCK (root / class / inst hold lists + local pool) |
| Global registry | lk_global_data (hash → LK_RES, per-tran table, free list) |
| Waits-for graph | LK_WFG_NODE / LK_WFG_EDGE, scanned by deadlock daemon |
| Deadlock victim | LOCK_RESUMED_ABORTED set on victim’s wait state |
| Released-early lock tracker (RC) | non2pl list, NON2PL mode marker |
CUBRID’s Approach
Section titled “CUBRID’s Approach”CUBRID instantiates the conventions above with a single global
lk_global_data, a per-transaction LK_TRAN_LOCK table, and a
shared LK_ENTRY record threaded into both views (resource and
transaction). The distinguishing choices are: (1) OID-shaped
resource keys that match the on-disk record identity exactly; (2)
a 12-mode vocabulary (NA…SCH-M) extending Gray’s MGL with BU,
SCH-S / SCH-M, U (defined in the enum and tables but never
issued by any current code path), and NON2PL; (3) a two-API
split between lock_scan (intent locks at class grain — a single
live call site at heap-scan start; most class-grain intent locks are
in fact planted by lock_object’s own MGL preparation) and
lock_object (real locks at instance grain); (4) a periodic WFG
cycle scan whose victim is picked by six ordered tie-breakers
(lock holder in the cycle → active → no deadlock priority → fewest
log records → finite timeout → youngest), plus per-request timeout
as a fallback.
How a lock request flows
Section titled “How a lock request flows”A query touches the lock manager through two API surfaces, one per grain. The pattern is deliberate: take an intention lock at the class first, then the real lock at the row.
flowchart LR
Q["query / DML"] --> S["lock_scan(class_oid, mode)\n• IS for SELECT\n• IX for INSERT/UPDATE/DELETE"]
S --> O["lock_object(record_oid, class_oid, mode)\n• X for write target\n• S for MVCC-disabled read\n (serials, in practice)\n• S for WITH LOCK · FOR UPDATE → X\n• plain MVCC SELECT: no call\n (visibility via snapshot)"]
O --> R{"compat with\nholders ∧ waiters?"}
R -- "yes" --> W["statement runs"]
R -- "no" --> B["suspend → WFG edge\n→ deadlock daemon scans cycles"]
B --> W
W --> U{"isolation\nlevel?"}
U -- "READ COMMITTED" --> RC["lock_unlock_object(\n move_to_non2pl=true)\nrelease per statement\n(S on MVCC-disabled classes only;\n X locks always held to commit)"]
U -- "RR == SERIALIZABLE" --> EOT["release at commit/rollback\n(strict 2PL).\nWrite path on MVCC-enabled,\nRR-eligible classes also raises\nER_MVCC_SERIALIZABLE_CONFLICT\nif visible version is stale\n(locator_sr.c)"]
Figure 1 — Lock request flow. Class-grain intent (lock_scan) precedes
row-grain real lock (lock_object); compatibility is checked against
both total_holders_mode and total_waiters_mode; the release path
branches on isolation level, with the textbook RC-vs-RR distinction
applying only to S locks on MVCC-disabled classes — see §“Lock release
— duration and isolation level”.
Each labeled box is unpacked in the subsections below — the OID-shaped
resource hierarchy, the LK_ENTRY dual-list layout, the 12-mode
vocabulary and 12×12 compatibility matrix, the acquisition state
machine, escalation, and the WFG deadlock detector. The boxes do not
move; only the level of detail increases.
Resource hierarchy and OID-shaped keys
Section titled “Resource hierarchy and OID-shaped keys”Every lockable thing in CUBRID — database, class, instance — is named
by an OID = (volid, pageid, slotid). The hierarchy used by intention
locking is literally the database OID hierarchy:
flowchart TB DB["Database / Root Class\n(OID_Root_class_oid)"] C1["Class C_a\n(class OID)"] C2["Class C_b"] I1a["Instance I_a1\n(instance OID, class_oid = C_a)"] I1b["Instance I_a2"] I1n["..."] I2a["Instance I_b1"] I2n["..."] DB --> C1 DB --> C2 C1 --> I1a C1 --> I1b C1 --> I1n C2 --> I2a C2 --> I2n
Figure 2 — OID hierarchy. The database root, every class, and every
instance share the same OID = (volid, pageid, slotid) shape, so the
lock manager indexes all three uniformly via LK_RES_KEY.
The OID itself is a three-tuple stored inline as a db_identifier:
// OID — src/compat/dbtype_def.htypedef struct db_identifier DB_IDENTIFIER;struct db_identifier{ int pageid; short slotid; short volid;};typedef DB_IDENTIFIER OID;A lock resource key, an LK_RES, and one acquired-or-pending lock,
LK_ENTRY, are the three core types:
// struct lk_res_key — src/transaction/lock_manager.hstruct lk_res_key{ LOCK_RESOURCE_TYPE type; /* class, instance, root_class */ OID oid; OID class_oid;};
// struct lk_res — src/transaction/lock_manager.hstruct lk_res{ LK_RES_KEY key; /* hash key */ LOCK total_holders_mode; /* aggregate lock mode of all holders */ LOCK total_waiters_mode; /* aggregate of all waiters */ LK_ENTRY *holder; /* per-resource holder list */ LK_ENTRY *waiter; /* per-resource waiter list */ LK_ENTRY *non2pl; /* released-early-but-still-tracked list */ pthread_mutex_t res_mutex; LK_RES *hash_next; /* hash chain */ LK_RES *stack; /* freelist */ UINT64 del_id; /* lock-free reclamation */};
// struct lk_entry — src/transaction/lock_manager.hstruct lk_entry{ struct lk_res *res_head; /* back to the resource */ THREAD_ENTRY *thrd_entry; int tran_index; LOCK granted_mode; LOCK blocked_mode; int count; /* re-entrant request counter */ UINT64 del_id; LK_ENTRY *stack; LK_ENTRY *next; /* per-resource list (holder or waiter) */ LK_ENTRY *tran_next; /* per-transaction list */ LK_ENTRY *tran_prev; LK_ENTRY *class_entry; /* parent class's LK_ENTRY (for instances) */ int ngranules; /* count of finer-grain children below */ int instant_lock_count; int bind_index_in_tran; XASL_ID xasl_id;};Two views of the same lock state
Section titled “Two views of the same lock state”The same LK_ENTRY (one acquired or pending lock) is threaded into
two different lists so the same lock state can be queried from either
side without scanning:
flowchart LR
subgraph TT["transaction view (LK_TRAN_LOCK)"]
direction TB
R["root_class_hold"]
C["class_hold_list"]
I["inst_hold_list"]
R -.-> C
C -.-> I
end
subgraph RT["resource view (LK_RES, hashed by LK_RES_KEY)"]
direction TB
H["holder list (granted)"]
W["waiter list (blocked)"]
end
E1["LK_ENTRY #1\n(tran 7, X-mode)\nres = R_91"]
E2["LK_ENTRY #2\n(tran 7, IX-mode)\nres = C_a"]
E3["LK_ENTRY #3\n(tran 9, blocked X)\nres = R_91"]
I -- "tran_next/prev" --> E1
C -- "tran_next/prev" --> E2
H -- "next" --> E1
W -- "next" --> E3
Figure 3 — Dual-view threading (abstract). The same LK_ENTRY is
spliced into both the resource-side list (holder or waiter of one
LK_RES) and the transaction-side list (root / class / instance
sub-list of one LK_TRAN_LOCK), so either view can be walked without
scanning the other.
The tran_next/tran_prev doubly-linked list is per-transaction and
separates root, class, and instance locks into three sub-lists. The
single next pointer threads holders or waiters per-resource. One
LK_ENTRY is in exactly one resource list (holder or waiter) and
exactly one transaction list at any moment.
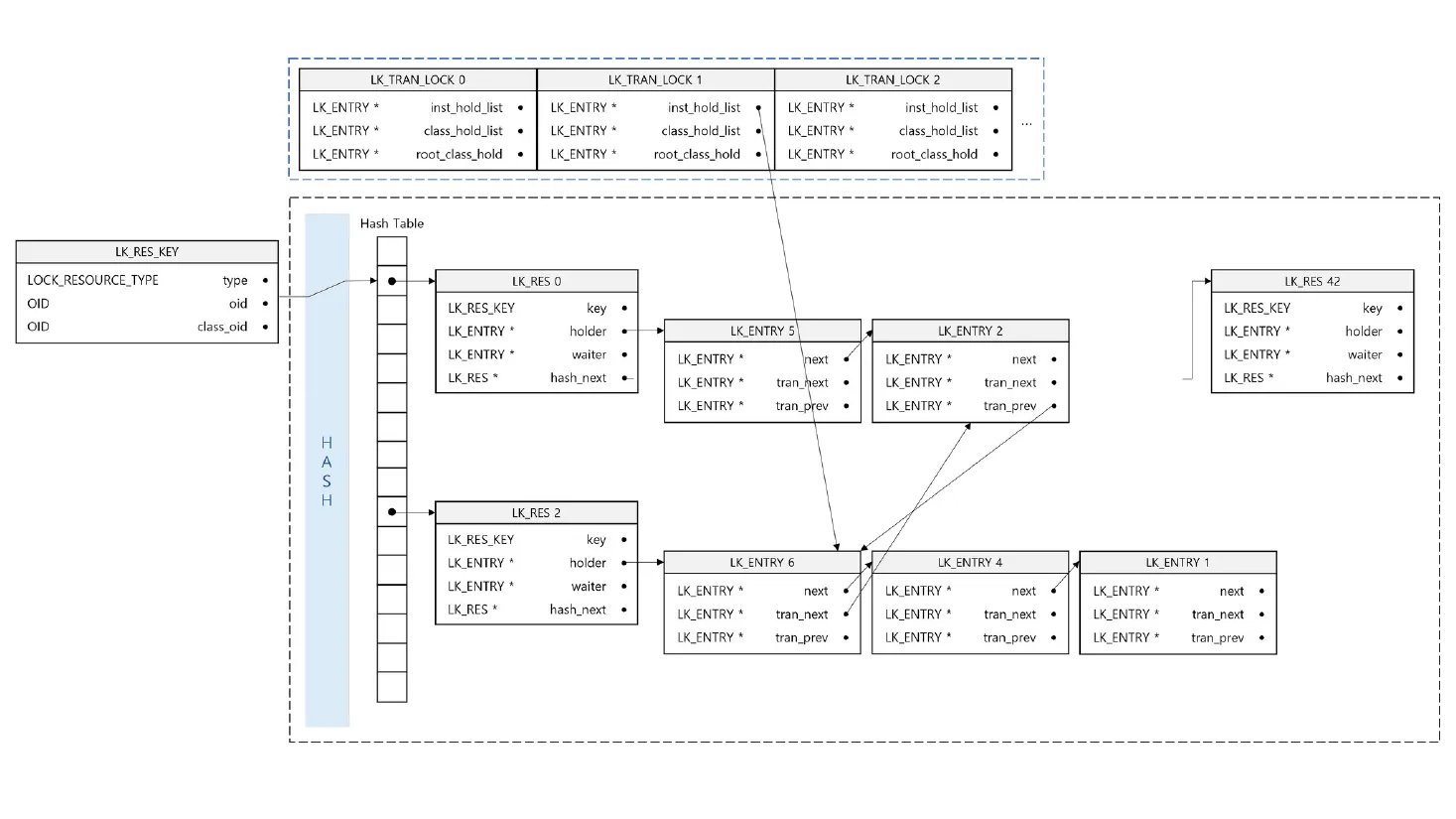
Figure 4 — Dual-view threading made concrete. Top row: three
per-transaction tables (LK_TRAN_LOCK 0/1/2), each pointing into
its own inst_hold_list/class_hold_list/root_class_hold.
Bottom box: the global hash table of LK_RES records, each
with its own holder/waiter lists. The arrows from top to bottom and
within the bottom group show that a single LK_ENTRY is reachable
from both views — tran_next/tran_prev from the transaction side,
next from the resource side. This is what lets release-at-commit
walk one list and compatibility checks walk another, both in O(1)
amortized. (Source: deck slide 35.)
The lock table — lk_global_data
Section titled “The lock table — lk_global_data”A single global struct holds:
m_obj_hash_table— hash fromLK_RES_KEY(OID-derived) toLK_RES. The hash function combinespageidandslotidmodulohtsize = MAX_NTRANS * 300; collisions resolve into a chain viaLK_RES.hash_next.tran_lock_table[tran_index]— per-transactionLK_TRAN_LOCK.obj_free_entry_list— global free list of recyclableLK_ENTRYs, used after the per-transaction local pool (lk_tran_lock.lk_entry_pool, default 10 entries) is exhausted.
flowchart TB HT["m_obj_hash_table\n(LK_RES_KEY → LK_RES)"] TLT["tran_lock_table[]\n(per tran_index)"] FREE["obj_free_entry_list\n(global LK_ENTRY freelist)"] HT --> R0["LK_RES (slot 0)\nholder, waiter, hash_next"] R0 --> R0H["holder LK_ENTRY chain"] R0 --> R0W["waiter LK_ENTRY chain"] R0 -. "hash collision" .-> R1["LK_RES (slot 0, chained)"] TLT --> TL0["LK_TRAN_LOCK[0]\n• inst_hold_list\n• class_hold_list\n• root_class_hold\n• lk_entry_pool[10]"] TLT --> TLN["LK_TRAN_LOCK[N]"] R0H -. "same LK_ENTRY,\ndifferent linkage" .-> TL0
Figure 5 — Global lock-table layout. m_obj_hash_table
(LK_RES_KEY → LK_RES, with per-bucket hash-collision chains via
hash_next), the per-transaction tran_lock_table[], and a global
obj_free_entry_list together back every active lock; the dashed
edge shows that a single LK_ENTRY appears in both a resource-side
list and a transaction-side list at once (cf. Figure 3).
Lock modes (12) and the compatibility matrix
Section titled “Lock modes (12) and the compatibility matrix”CUBRID’s lock vocabulary, ordered by strength:
| Value | Mode | Meaning |
|---|---|---|
| 0 | NA | no lock |
| 1 | NON2PL | incompatible 2PL marker (released early) |
| 2 | NULL | placeholder |
| 3 | SCH-S | schema stability (DDL must wait) |
| 4 | IS | intention shared |
| 5 | S | shared |
| 6 | IX | intention exclusive |
| 7 | BU | bulk update |
| 8 | SIX | shared + intention exclusive |
| 9 | U | update (S that intends to upgrade to X) |
| 10 | X | exclusive |
| 11 | SCH-M | schema modification |
The compatibility matrix (12×12; NA, NON2PL, U omitted from the
printed 9×9 below) is a static lookup table. From Lock_Manager.pdf,
slide 20:
| NULL | SCH-S | IS | S | IX | BU | SIX | X | SCH-M | |
|---|---|---|---|---|---|---|---|---|---|
| NULL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| SCH-S | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ |
| IS | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ |
| S | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| IX | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| BU | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| SIX | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| X | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| SCH-M | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
A new request must be compatible with both the resource’s
total_holders_mode and total_waiters_mode:
- The holders test prevents conflicts with currently-granted locks.
- The waiters test is the starvation guard: a stream of S requests cannot leapfrog a waiting X request just because they happen to be compatible with the current holders.
Aggregated mode bits replace per-holder list scans, turning each compatibility test into O(1).
Wake reasons for blocked threads
Section titled “Wake reasons for blocked threads”A blocked thread waits with a per-request timeout and resumes for one of these reasons:
// enum LOCK_WAIT_STATE — src/transaction/lock_manager.ctypedef enum{ LOCK_SUSPENDED, LOCK_RESUMED, /* lock granted */ LOCK_RESUMED_TIMEOUT, LOCK_RESUMED_DEADLOCK_TIMEOUT, /* picked as deadlock victim */ LOCK_RESUMED_ABORTED, /* must abort due to deadlock */ LOCK_RESUMED_ABORTED_FIRST, LOCK_RESUMED_ABORTED_OTHER, LOCK_RESUMED_INTERRUPT} LOCK_WAIT_STATE;Initializing an entry as granted vs. blocked
Section titled “Initializing an entry as granted vs. blocked”Two helpers diverge on which mode field is populated:
// lock_initialize_entry_as_granted — src/transaction/lock_manager.cstatic voidlock_initialize_entry_as_granted (LK_ENTRY * entry_ptr, int tran_index, LK_RES * res, LOCK lock){ entry_ptr->tran_index = tran_index; entry_ptr->res_head = res; entry_ptr->granted_mode = lock; entry_ptr->blocked_mode = NULL_LOCK; entry_ptr->count = 1; /* ... list pointers nulled ... */}
// lock_initialize_entry_as_blocked — src/transaction/lock_manager.cstatic voidlock_initialize_entry_as_blocked (LK_ENTRY * entry_ptr, THREAD_ENTRY * thread_p, int tran_index, LK_RES * res, LOCK lock){ entry_ptr->tran_index = tran_index; entry_ptr->thrd_entry = thread_p; entry_ptr->res_head = res; entry_ptr->granted_mode = NULL_LOCK; entry_ptr->blocked_mode = lock; entry_ptr->count = 1; /* ... list pointers nulled ... */}For an entry that lives in the holder list, granted_mode is the
useful field; for a waiter, blocked_mode is.
Conversion-in-progress holders use both: granted_mode is the
currently held mode, blocked_mode is the upgrade being awaited.
Lock acquisition flow — lock_object → lock_internal_perform_lock_object
Section titled “Lock acquisition flow — lock_object → lock_internal_perform_lock_object”// lock_internal_perform_lock_object — src/transaction/lock_manager.c (annotated excerpt)static intlock_internal_perform_lock_object (THREAD_ENTRY *thread_p, int tran_index, const OID *oid, const OID *class_oid, LOCK lock, int wait_msecs, LK_ENTRY **entry_addr_ptr, LK_ENTRY *class_entry){ /* ... */
start: if (class_oid != NULL && !OID_IS_ROOTOID (class_oid)) { /* instance lock request */ ret_val = lock_escalate_if_needed (thread_p, class_entry, tran_index); /* ... if class lock now subsumes the request, return granted ... */ } else { /* class lock request — try to find existing entry first */ entry_ptr = lock_find_class_entry (tran_index, oid); if (entry_ptr != NULL) { res_ptr = entry_ptr->res_head; goto lock_tran_lk_entry; } }
/* find or add the lockable object in the lock table */ search_key = lock_create_search_key ((OID *) oid, (OID *) class_oid); (void) lk_Gl.m_obj_hash_table.find_or_insert (thread_p, search_key, res_ptr); is_res_mutex_locked = true;
if (res_ptr->holder == NULL && res_ptr->waiter == NULL && res_ptr->non2pl == NULL) { /* fresh resource: grant unconditionally */ /* ... lock_initialize_resource_as_allocated, allocate granted entry ... */ } else { /* check compatibility with total_holders_mode | total_waiters_mode */ /* ... if compatible: splice into holder list, update aggregates ... */ /* ... else: splice as waiter, update aggregates, suspend thread ... */ }}End-to-end:
flowchart TD
A["lock_object(thread, oid, class_oid, mode)"]
A --> B{"class lock\nor instance lock?"}
B -- "instance" --> C["lock_escalate_if_needed\n(parent class)"]
C --> D{"class lock\nsubsumes request?"}
D -- "yes" --> Z1["return LK_GRANTED"]
D -- "no" --> H
B -- "class" --> E{"existing entry\nfor this tran?"}
E -- "yes" --> J["bump count / request conversion"]
E -- "no" --> H["m_obj_hash_table.find_or_insert(LK_RES_KEY)"]
H --> F{"res empty\n(no holder/waiter)?"}
F -- "yes" --> G["grant fresh:\ninitialize_entry_as_granted,\nsplice into holder list"]
G --> Z2["return LK_GRANTED"]
F -- "no" --> K{"compat with holders|waiters?"}
K -- "yes" --> L["splice into holder list,\nupdate total_holders_mode"]
L --> Z3["return LK_GRANTED"]
K -- "no" --> M["splice into waiter list,\nupdate total_waiters_mode,\nsuspend thread"]
M --> N{"resume reason"}
N -- "LOCK_RESUMED" --> Z4["granted"]
N -- "LOCK_RESUMED_TIMEOUT" --> Z5["LK_NOTGRANTED_DUE_TIMEOUT"]
N -- "LOCK_RESUMED_ABORTED\n(deadlock victim)" --> Z6["abort transaction"]
Figure 6 — lock_object acquisition state machine. Instance-vs-class
dispatch first triggers lock_escalate_if_needed, then a re-entrant
shortcut, then the fresh-resource grant path, and finally the
compatibility-checked grant or enqueue. A suspended waiter resumes
through one of three reasons — granted, timed out, or marked as
deadlock victim.
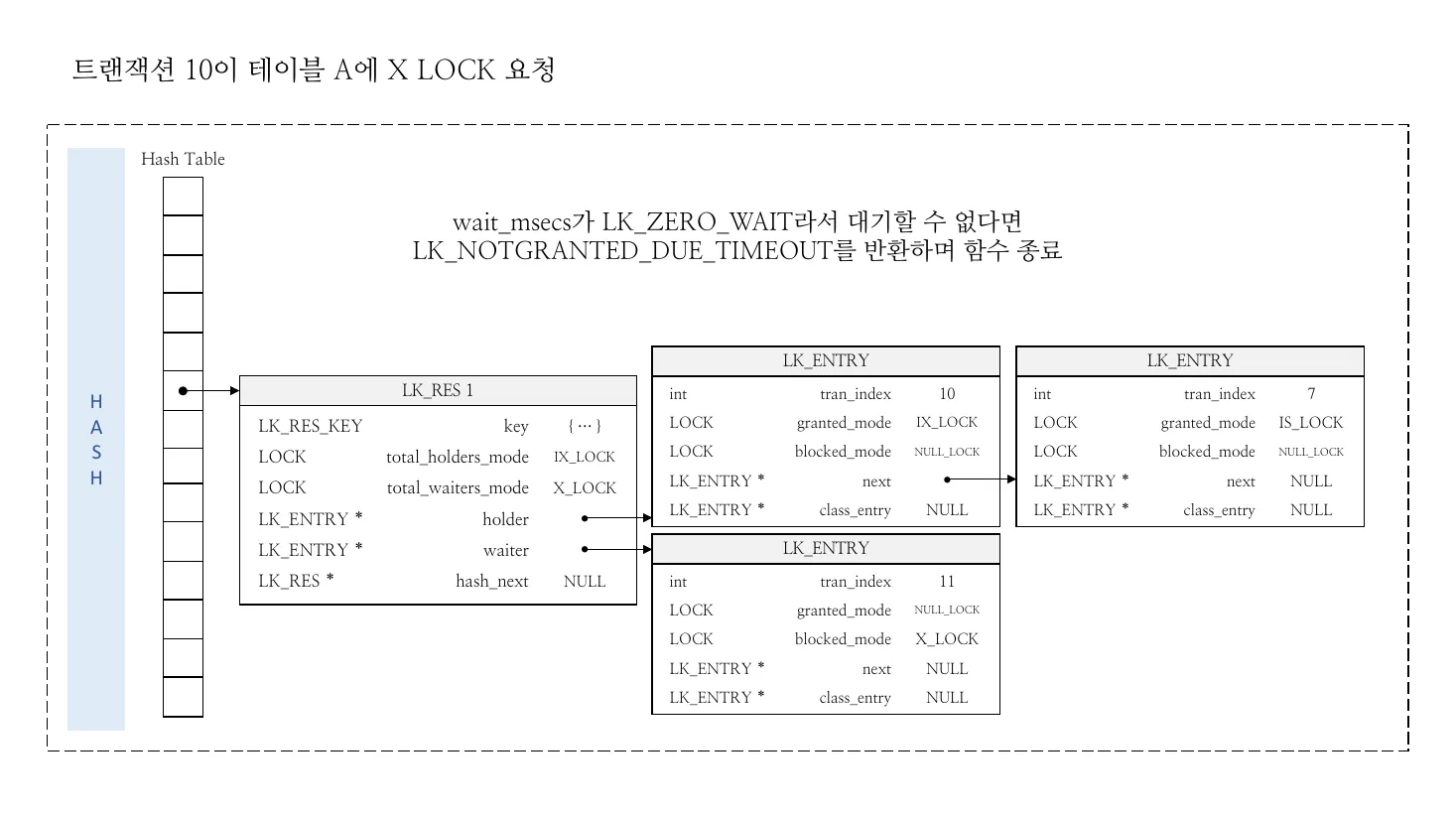
Figure 7 — Concrete acquisition scenario. Transaction 10
requests X_LOCK on table A. The hash table already contains
LK_RES 1 for table A with two holders: tran 7 holding IS_LOCK,
tran 11 currently waiting with blocked_mode = X_LOCK. The
aggregate fields carry the answer: total_holders_mode = IX_LOCK
(LUB of currently-granted IS+IX), total_waiters_mode = X_LOCK. A
new X_LOCK request fails compatibility against the holders side,
fails against the waiters side, and so is enqueued; if wait_msecs == LK_ZERO_WAIT, the call returns LK_NOTGRANTED_DUE_TIMEOUT instead
of suspending. (Source: deck slide 110.)
Lock release — duration and isolation level
Section titled “Lock release — duration and isolation level”This section is the locking-axis half of §“Isolation level — three
axes, not one”. The release-timing rules below are scoped narrowly:
they apply to S instance locks on MVCC-disabled classes (root
class, serials, collation, HA apply-info) and to S locks taken via
explicit SELECT … WITH LOCK. (SELECT … FOR UPDATE is not in
this bucket: it takes X row locks — scan_manager.c maps
S_UPDATE → X_LOCK — and X locks hold to commit.) Plain MVCC SELECT
readers take no instance row locks at all; X locks acquired on the
write path are not eligible for early release at any isolation
level.
The dispatch (all symbols in src/transaction/lock_manager.c; line
numbers are in the position-hint table):
lock_unlock_objectshort-circuits with the comment “These will not be released” wheneverlock != S_LOCK. So X locks always hold to commit, regardless of isolation level. The bullets below describe the fate of the S locks only.- Under REPEATABLE READ / SERIALIZABLE, the same function returns “nothing to do” — even S locks are long-duration.
- Under READ COMMITTED, it calls
lock_unlock_object_by_isolation, which splits onmvcc_is_mvcc_disabled_class. The MVCC-enabled branch is a no-op (snapshot-based reads never took a lock to release). The MVCC-disabled branch callslock_unlock_shared_inst_lockto release the S lock.
With that scoping in mind, the durations are:
- S instance locks under READ COMMITTED, MVCC-disabled classes —
released as soon as the statement that acquired them finishes
(short-duration), and recorded in
non2plso subsequent re-reads in the same transaction can still detect conflicts. - S instance locks under REPEATABLE READ / SERIALIZABLE — released at transaction end. Standard 2PL.
- X instance locks — released at transaction end regardless of
isolation level. The early-release path is gated to
S_LOCKonly. - Class locks — released at transaction end regardless of isolation level (intention locks have to outlive their children).
- Schema locks (SCH-S/SCH-M) — special-cased; SCH-M conflicts with
every other mode except
NULL.
Note — is statement-grain release safe? A natural worry on first reading: doesn’t releasing the S lock at statement end break 2PL’s safety guarantees? It does break serializability — that is exactly the contract READ COMMITTED weakens — but two other safety properties survive:
- No dirty reads. The S lock is held during the read; no concurrent writer can hold an incompatible X simultaneously. So whatever the statement read is committed data, not in-flight writes.
- No cascading aborts (recoverability). Write-path X locks are never released early —
lock_unlock_objectshort-circuits with “These will not be released” for any mode that is notS_LOCK. So no other transaction can see this transaction’s uncommitted writes regardless of isolation level.What READ COMMITTED deliberately admits in exchange: non-repeatable reads and phantoms. The
NON2PLside-list keeps a trace of the early-released lock so a later same-transaction re-read can still detect that the row was touched, but RC’s contract does not require the engine to re-acquire or re-validate. Bamboo (Guo et al. 2021) generalizes this “release early, re-validate later” idea — see §“Beyond CUBRID”.
The release path is lock_unlock_object →
lock_internal_perform_unlock_object (both in
src/transaction/lock_manager.c).
lock_unlock_object_by_isolation implements the per-isolation,
per-MVCC-status policy.
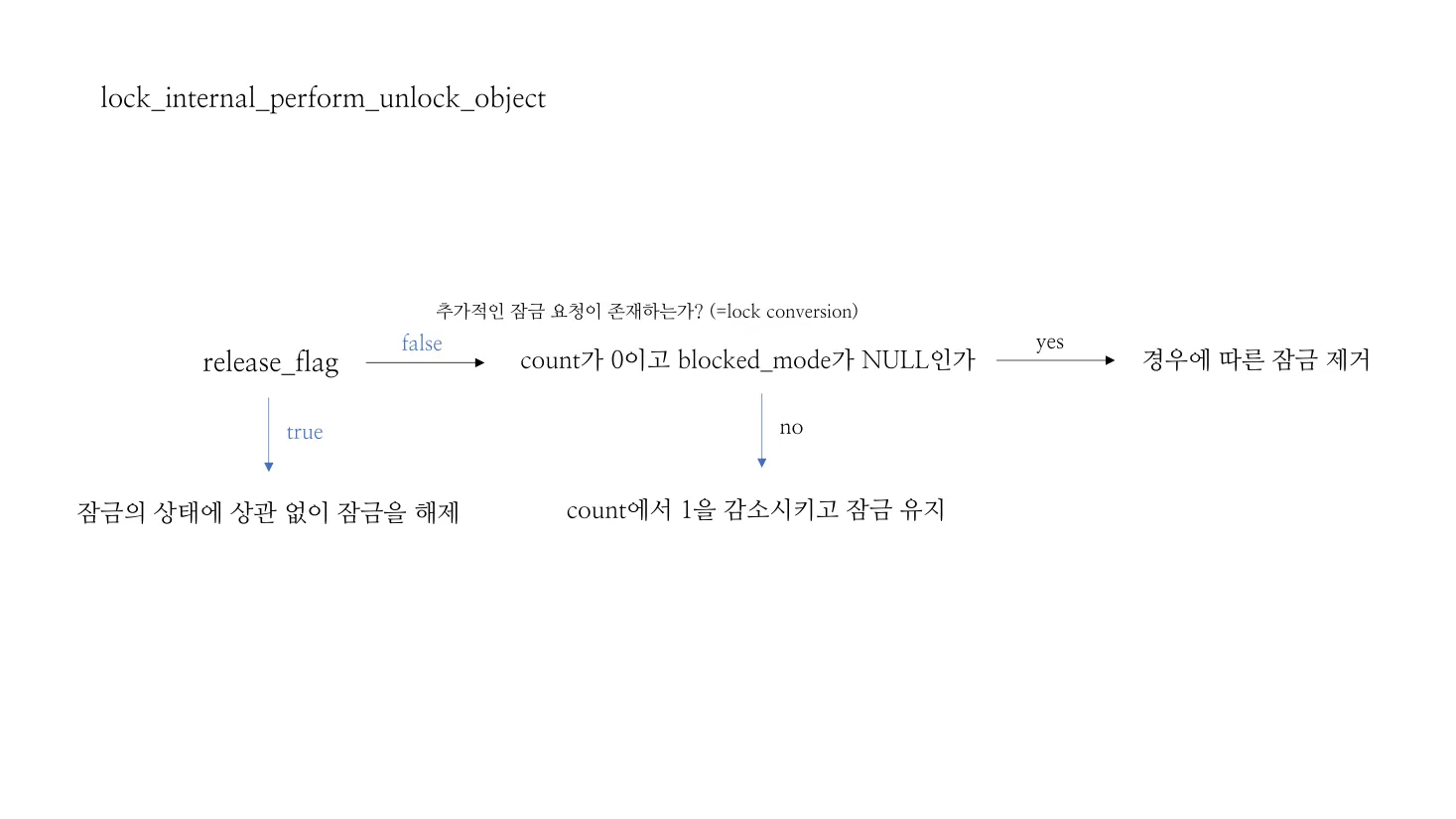
Figure 8 — lock_internal_perform_unlock_object decision tree.
release_flag = true is the unconditional path used at transaction
end. With release_flag = false, the function checks for a
re-entrant request (count > 0 and a pending conversion in
blocked_mode); if more requests are outstanding, the lock is kept
and count is just decremented. Only when count == 0 and
blocked_mode == NULL_LOCK does the entry actually leave the holder
list. (Source: deck slide 180.)
Lock escalation
Section titled “Lock escalation”Per-transaction lock counts are bounded. When a transaction acquires
more than lock_escalation_threshold instance locks on a single
class, lock_escalate_if_needed (in src/transaction/lock_manager.c)
replaces the per-row locks with a single class-level lock and frees
the instance entries. This is a memory-pressure relief valve and is also the
reason LK_ENTRY carries ngranules (count of children for an
intention lock) and a class_entry back-pointer.
Deadlock detection — waits-for graph
Section titled “Deadlock detection — waits-for graph”CUBRID uses a waits-for graph (WFG) maintained in
src/transaction/wait_for_graph.{h,c} and walked periodically by a
dedicated checker. The two graph types live in lock_manager.c:
// TWFG (transaction wait-for graph) types — src/transaction/lock_manager.c/* TWFG (transaction wait-for graph) entry and edge */typedef struct lk_WFG_node LK_WFG_NODE;struct lk_WFG_node{ int first_edge; bool candidate; int current; int ancestor; INT64 thrd_wait_stime; int tran_edge_seq_num; bool checked_by_deadlock_detector; bool DL_victim;};
typedef struct lk_WFG_edge LK_WFG_EDGE;struct lk_WFG_edge{ int to_tran_index; int edge_seq_num; int holder_flag; int next; INT64 edge_wait_stime; LK_ENTRY *holder; LK_ENTRY *waiter;};When transaction T1 blocks waiting for a lock currently held by T2,
an LK_WFG_EDGE is added from T1’s LK_WFG_NODE to T2’s. The
detector (lock_detect_local_deadlock) walks the graph looking for
cycles, picks an LK_DEADLOCK_VICTIM by six ordered tie-breakers
(lock holder in the cycle → active → no deadlock priority → fewest
log records → finite timeout → youngest; lock_select_deadlock_victim,
detail doc ch. 8), and wakes it as LOCK_RESUMED_ABORTED_* — or as
the retryable LOCK_RESUMED_DEADLOCK_TIMEOUT when the victim has a
finite wait_msecs; the lock-acquisition loop in the victim then
sees the abort flag and propagates it as a rollback.

Figure 9 — Waits-For Graph cycle and deadlock detection (abstract).
A three-transaction cycle (T1 → T2 → T3 → T1) discovered by DFS in
the periodic lock_detect_local_deadlock scan. The victim is chosen
by six ordered tie-breakers (lock_select_deadlock_victim,
detail doc ch. 8 — not “most recently blocked”, as an earlier
revision of this document claimed); the wake state on its LK_ENTRY
(LOCK_RESUMED_ABORTED_*, or the retryable DEADLOCK_TIMEOUT for
finite-wait victims) makes the acquisition loop propagate rollback
or a retryable error.
The “local” qualifier is intentional: distributed deadlock detection is out of scope for the per-node manager. Timeout-based deadlock breaking is the fallback when graph maintenance lags.
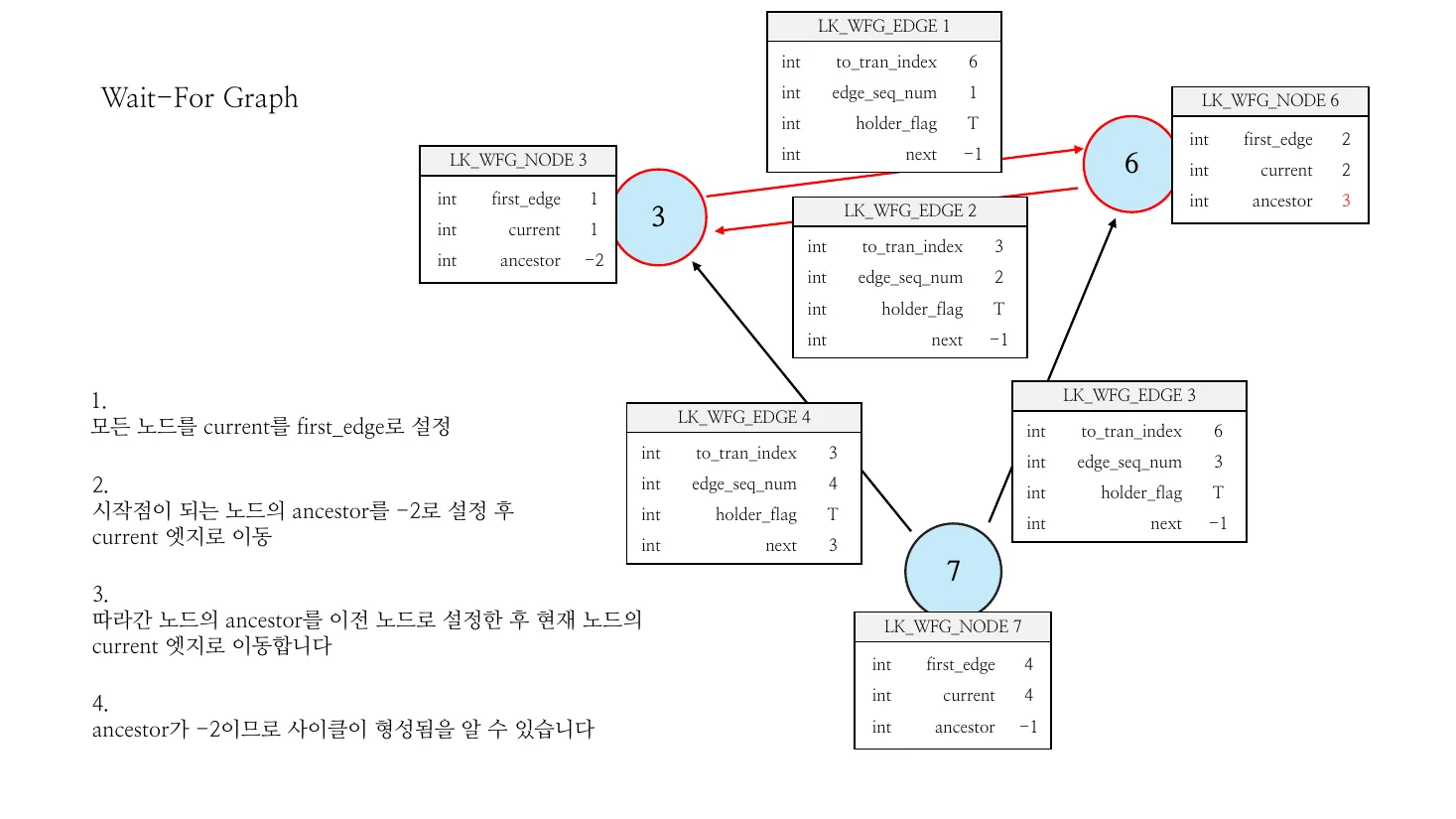
Figure 10 — Wait-For Graph cycle detection step by step. Three
transactions (3, 6, 7) and four edges form the WFG; the algorithm
performs a DFS marking each LK_WFG_NODE.current and .ancestor,
and detects a cycle when a follow-up walk returns to a node whose
ancestor == -2 (start sentinel). The exact field semantics shown
on the right are the same first_edge, current, ancestor,
to_tran_index, edge_seq_num, holder_flag, next fields walked
by lock_detect_local_deadlock. (Source: deck slide 160.)
Lifecycle
Section titled “Lifecycle”lock_initialize(insrc/transaction/lock_manager.c) allocates the hash table, per-tran tables, free entry list, and the deadlock-detection state.lock_finalizetears them down, withlock_finalize_tran_lock_tablehandling the per-tran half.
Source Walkthrough
Section titled “Source Walkthrough”Anchor on symbol names, not line numbers. The CUBRID source moves; a function name (or struct/enum tag) is the stable handle. Use
git grep -n '<symbol>' src/transaction/to locate the current position. The position-hint table at the end of this section was observed when the document was lastupdated:.
Type definitions (src/transaction/)
Section titled “Type definitions (src/transaction/)”struct lk_entry(inlock_manager.h) — one acquired or pending lock; threaded into both a resource list and a transaction list.struct lk_res_key(inlock_manager.h) — OID-shaped hash key.struct lk_res(inlock_manager.h) — per-resource state withtotal_holders_mode,total_waiters_mode, holder/waiter lists.enum LOCK_WAIT_STATE(inlock_manager.c) — wake reasons (LOCK_RESUMED,LOCK_RESUMED_TIMEOUT,LOCK_RESUMED_DEADLOCK_TIMEOUT,LOCK_RESUMED_ABORTED, …).struct lk_WFG_node,struct lk_WFG_edge,struct lk_deadlock_victim(inlock_manager.c) — waits-for graph nodes/edges plus victim record.
Initialization (src/transaction/lock_manager.c)
Section titled “Initialization (src/transaction/lock_manager.c)”lock_initialize— entry point; calls each of the helpers below.lock_initialize_tran_lock_table— per-tran tables.lock_initialize_object_hash_table—m_obj_hash_table(MAX_NTRANS * 300slots).lock_initialize_object_lock_entry_list— global free list ofLK_ENTRY.lock_initialize_deadlock_detection— WFG state.
Acquisition / conversion / release (src/transaction/lock_manager.c)
Section titled “Acquisition / conversion / release (src/transaction/lock_manager.c)”lock_object— public entry.lock_object_wait_msecs— variant with explicit timeout.lock_internal_perform_lock_object— real work (excerpted above).lock_internal_perform_unlock_object.lock_unlock_object.lock_unlock_objects_lock_set— bulk release forLC_LOCKSET.lock_initialize_entry_as_granted/lock_initialize_entry_as_blocked/lock_initialize_entry_as_non2pl— entry constructors.
Escalation and deadlock (src/transaction/lock_manager.c)
Section titled “Escalation and deadlock (src/transaction/lock_manager.c)”lock_escalate_if_needed— escalate per-instance to per-class.lock_detect_local_deadlock— periodic WFG cycle scan.#include "wait_for_graph.h"near the top of the file — the WFG abstraction lives insrc/transaction/wait_for_graph.{h,c}.
Lock-mode tables
Section titled “Lock-mode tables”src/transaction/lock_table.h— declarations for the compatibility and conversion matrices.src/transaction/lock_table.c— the actual 12×12 tables.
Position hints as of this revision
Section titled “Position hints as of this revision”These line numbers held when the document was last updated:. If you
land at a different definition, the symbol name above is authoritative;
update the table on your way through.
| Symbol | File | Line |
|---|---|---|
struct lk_entry | lock_manager.h | 79 |
struct lk_res_key | lock_manager.h | 164 |
struct lk_res | lock_manager.h | 175 |
enum LOCK_WAIT_STATE | lock_manager.c | 180 |
struct lk_WFG_node/_edge/deadlock_victim | lock_manager.c | 256 |
lock_initialize_entry_as_granted | lock_manager.c | 920 |
lock_initialize_entry_as_blocked | lock_manager.c | 940 |
lock_initialize_tran_lock_table | lock_manager.c | 1061 |
lock_initialize_object_hash_table | lock_manager.c | 1121 |
lock_initialize_object_lock_entry_list | lock_manager.c | 1152 |
lock_initialize_deadlock_detection | lock_manager.c | 1180 |
lock_escalate_if_needed | lock_manager.c | 2974 |
lock_internal_perform_lock_object | lock_manager.c | 3223 |
lock_internal_perform_unlock_object | lock_manager.c | 3945 |
lock_initialize | lock_manager.c | 5627 |
lock_finalize_tran_lock_table | lock_manager.c | 5702 |
lock_finalize | lock_manager.c | 5859 |
lock_object | lock_manager.c | 5945 |
lock_object_wait_msecs | lock_manager.c | 6273 |
lock_scan | lock_manager.c | 6303 |
lock_classes_lock_hint | lock_manager.c | 6379 |
lock_unlock_object | lock_manager.c | 6630 |
lock_unlock_objects_lock_set | lock_manager.c | 6722 |
lock_unlock_classes_lock_hint | lock_manager.c | 6792 |
lock_unlock_object_by_isolation | lock_manager.c | 9841 |
lock_unlock_inst_locks_of_class_by_isolation | lock_manager.c | 9879 |
Source verification (as of 2026-04-29)
Section titled “Source verification (as of 2026-04-29)”Each entry is a fact about the current source — readable without the original analysis materials. The trailing note shows how it was checked and, where relevant, historical drift or limits of verification. Open questions follow as the curator’s recorded gaps; future readers should treat them as starting points, not as known bugs.
Verified facts
Section titled “Verified facts”-
LK_ENTRY,LK_RES_KEY, andLK_RESare the three core types insrc/transaction/lock_manager.h. Symbol names are the stable handle; line numbers in the position-hint table above are scoped to this revision’supdated:date and will drift with reformatting. -
The lock vocabulary has 12 modes (NA, NON2PL, NULL, SCH-S, IS, S, IX, BU, SIX, U, X, SCH-M).
BU(bulk update) is incompatible withIS,S,IX,SIX,X,SCH-M— verified inlock_table.con 2026-04-29. (Whether the bulk-update path is actively exercised on a current build vs. legacy is an open question.) -
The object hash size is
MAX_NTRANS * 300, hard-coded. Verified inlock_initialize_object_hash_table(lock_manager.c) on 2026-04-29. The “300” is a literal multiplier in the source, not a parameter. Tuning it requires a source change, not a config setting. -
The per-transaction local entry pool size is
LOCK_TRAN_LOCAL_POOL_MAX_SIZE = 10. Verified on 2026-04-29.lock_get_new_entry/lock_free_entrysearch the local pool before the global free list — the local-first lookup ordering matters because hot OLTP transactions can satisfy most lock needs without touching the shared free-list lock. -
LK_ENTRY.class_entryis a one-hop pointer, not a multi-step chain. For instances, it points to the parent class’sLK_ENTRY; for classes, to the root-classLK_ENTRY. Verified inlock_internal_perform_lock_objectandlock_escalate_if_neededon 2026-04-29. Designed for fast escalation, not for hierarchical traversal. -
Wake reasons for blocked threads are enumerated in
enum LOCK_WAIT_STATE(lock_manager.c). Confirmed members includeLOCK_RESUMED,LOCK_RESUMED_TIMEOUT,LOCK_RESUMED_DEADLOCK_TIMEOUT,LOCK_RESUMED_ABORTED,LOCK_RESUMED_INTERRUPT. Verified on 2026-04-29. -
Deadlock victim policy is six ordered tie-breakers — lock holder in the cycle → active → no deadlock priority → fewest log records written → finite timeout → youngest. Verified by walking
lock_select_deadlock_victimon 2026-06-10. (An earlier revision of this entry claimed “most-recently-blocked”, inferred from WFG insertion order — that was wrong: the source applies an explicit comparison chain. Open Question §1 is closed.)
Open questions
Section titled “Open questions”-
Is “most-recently-blocked” the intended victim policy, or an artifact of WFG insertion order?Resolved (2026-06-10): the premise was wrong —lock_select_deadlock_victimapplies an explicit six-criteria comparison chain (holder → active → no deadlock priority → fewest log records → finite timeout → youngest); nothing depends on WFG insertion order. Detail doc ch. 8 §8.6 has the annotated walk. -
Distributed deadlocks.
lock_detect_local_deadlockis named “local” deliberately; CUBRID distributed setups (HA / shard load balancing) presumably handle cross-node deadlocks via timeout. Worth verifying once the heartbeat / CDC analyses are pulled in. -
NON2PLexact protocol.lock_initialize_entry_as_non2plmarks locks released early underREAD COMMITTEDthat other transactions may still want to “see” for serialization purposes. The exact handshake — which transactions check non2pl when, and what happens when a non2pl entry “wins” a conflict — is worth tracing through the unlock path. -
Remaining MVCC / locking boundary questions. The high-level boundary is mapped in §“Isolation level — three axes, not one”: visibility via snapshot on MVCC-enabled classes; instance row locks only on the four MVCC-disabled class kinds, on explicit
WITH LOCK/FOR UPDATE, and on the write path; RR/SERIALIZABLE add a snapshot-based first-updater-wins check at update time on MVCC-enabled, RR-eligible classes. The two predicates (mvcc_is_mvcc_disabled_class,logtb_check_class_for_rr_isolation_err) are now also fully mapped: they are independent and combined asMVCC-enabled AND RR-eligibleat the conflict-check site. Narrower items still open:- The exact protocol by which
NON2PL-tracked early-released S locks interact with later re-reads in the same RC transaction against an MVCC-disabled class — i.e., how aNON2PLentry “wins” a serialization conflict in practice. - Whether any code path still acquires a class-grain
S_LOCKfor SERIALIZABLE / RR SELECTs. The singlelock_scancaller (insrc/storage/heap_file.c) hard-codesIS_LOCK. If a class-S path exists, it would go throughlock_classes_lock_hintor a directlock_objecton the class OID — provenance not yet traced.
- The exact protocol by which
-
Bulk-update path liveness.
BUis in the vocabulary and the matrix, but is the bulk-update code path actually exercised on current builds, or has it become legacy? Investigation path:git log -S BU_LOCK -- src/transaction/plus a runtime trace of anyloaddb-style ingest.
Beyond CUBRID — Comparative Designs & Research Frontiers
Section titled “Beyond CUBRID — Comparative Designs & Research Frontiers”Pointers, not analysis. Each bullet is a starting handle for a follow-up doc; depth here is intentionally shallow.
- Bamboo: releasing locks early. Guo et al. (2021) — release
exclusive locks before commit when subsequent readers can be
re-validated, reducing tail latency on contended OLTP. CUBRID’s
NON2PLmachinery already tracks early-released RC locks for conflict detection; Bamboo generalizes the pattern. - Brook-2PL: deadlock-free 2PL. Pre-analyzes a static dependency ordering to make deadlocks impossible. The trade-off is the pre-analysis cost — interesting only for stable, repeating workloads.
- TXSQL: lock optimizations for contended workloads. Adaptive
lock-mode adjustment, batching, and contention-aware scheduling.
Cross-pollination candidates with CUBRID’s
lock_escalate_if_needed. - Optimistic CC without a central lock manager. Hekaton, Silo, Cicada eliminate the lock table — validation at commit time replaces acquisition. Different design point; relevant for in-memory workloads and the OCC-vs-2PL debate at high core counts.
- VLL — Very Lightweight Locking. Reduces lock-acquisition cost through partitioning. Useful pattern when the lock table itself is the contention hotspot.
- HTM-assisted lock managers. Hardware transactional memory fast-paths short transactions to avoid lock acquisition entirely. Still niche in production but explored for OLTP.
- Serializable Snapshot Isolation (PostgreSQL SSI). Cahill et al.
add a runtime conflict-graph (rw-antidependency tracking) on top of
SI so that workloads exhibiting write skew are aborted before
commit. CUBRID’s
SERIALIZABLEis Snapshot Isolation with first-updater-wins (theER_MVCC_SERIALIZABLE_CONFLICTcheck at update time on MVCC-enabled, RR-eligible classes — see §“Isolation level — three axes, not one”); it does not implement SSI’s rw-antidependency tracking and therefore admits write skew. SSI is the natural follow-up if true serializability is wanted without reverting to 2PL. - Formal models of lock escalation. KAIST DBLAB (Chang 2005)
formalizes the trade-offs between memory pressure relief and
unintended serialization caused by escalation. Relevant for tuning
CUBRID’s
lock_escalation_threshold. - Recent paper trail (from Notion’s “Storage – Concurrency” overview): Cahill et al., Serializable Snapshot Isolation in PostgreSQL (2008/2012); Yu et al., Staring into the Abyss (VLDB 15); Wu et al., empirical MVCC (VLDB 17); Bamboo (2021); Brook-2PL (2025); TXSQL (2025).
The intent of this section is to seed next documents, not to analyze. Each bullet should become its own curated note when its turn comes.
Sources
Section titled “Sources”Raw analyses (under raw/code-analysis/cubrid/storage/lock_manager/)
Section titled “Raw analyses (under raw/code-analysis/cubrid/storage/lock_manager/)”Lock_Manager.pdf— primary deck; lock modes, hash table, resource/entry layout, compatibility/conversion matrices.lock manager_발표.pdfand.pptx— presentation deck with step-by-step compatibility/conversion examples (e.g., anSrequest arriving with mixed holders).LOG_TDES_LOCK_Data.pdf— narrative description oflk_global_data,lk_tran_lock,lk_entry,lk_resand their interrelations from the transaction-descriptor side.
Textbook chapters (under knowledge/research/dbms-general/)
Section titled “Textbook chapters (under knowledge/research/dbms-general/)”- Database Internals (Petrov), Ch. 5: §“Locks vs Latches” (≈ line 4404), §“Two-Phase Locking” (≈ line 4321), §“Deadlocks” (≈ line 4344) including waits-for graphs and the wait-die / wound-wait avoidance schemes.
- Ch. 1, §“Lock manager” (≈ line 777) — high-level role of the component within DBMS architecture.
Notion (CUBRID DEV WIKI)
Section titled “Notion (CUBRID DEV WIKI)”- Storage – Concurrency 코드 분석 — module-level positioning that frames Lock Manager alongside MVCC and Vacuum.
- Lock Manager 코드 분석 — 자료구조·초기화·잠금 획득 흐름 —
authoritative for the
LK_GLOBAL_DATA,LK_TRAN_LOCK, and thelock_internal_perform_lock_objectstate machine; the dual-view framing in §“Mental model” is distilled from this page. - Lock Manager 코드 분석 — Isolation Level별 잠금 동작 — the
lock_unlock_objectisolation branch; basis for the “isolation is policy, not mechanism” claim in §“How a lock request flows”. - Lock Manager 코드 분석 — Deadlock Detection / Lock Escalation / Lock Suspend·Resume / Composite Lock / Instant Lock Mode / non2pl 리스트 상세 / 디버깅 가이드 / lock_scan() — auxiliary chapters in the same workspace that drill into specific subsystems referenced here.
CUBRID source (under /data/hgryoo/references/cubrid/)
Section titled “CUBRID source (under /data/hgryoo/references/cubrid/)”src/transaction/lock_manager.hsrc/transaction/lock_manager.csrc/transaction/lock_table.hsrc/transaction/lock_table.csrc/transaction/wait_for_graph.h(deadlock-detection abstraction)src/transaction/wait_for_graph.c(deadlock-detection implementation)