CUBRID Log Manager — WAL, LSN, and Append Discipline
Contents:
- Theoretical Background
- Common DBMS Design
- CUBRID’s Approach
- Source Walkthrough
- Source verification (as of 2026-04-30)
- Beyond CUBRID — Comparative Designs & Research Frontiers
- Sources
Theoretical Background
Section titled “Theoretical Background”The log manager is CUBRID’s implementation of the write-ahead log (WAL) protocol, the contract every disk-resident relational engine signs with the recovery manager: no dirty data page may reach disk before the log records describing the modification reach stable storage. Database Internals (Petrov, ch. 5 §“Recovery”) frames the two halves of that contract — the log itself, and the discipline that keeps it ahead of data — as the foundation that ARIES (Mohan et al., 1992) builds on. Without WAL, redo and undo at recovery time have no authority over what may have leaked to disk; with WAL, the engine replays only what it logged and undoes only what it must.
The log is a logical, append-only sequence of typed records. Every record carries enough information for two questions to be answered later: “given the page state on disk, what should I do to reapply this change?” (redo) and “given the page state on disk, what should I do to undo this change?” (undo). Around that central record type the engine layers transaction boundaries (commit / abort), system boundaries (start, checkpoint, end-of-log), structural boundaries (savepoint, system-op start/end), and out-of-band channels (HA state, replication, supplemental info for CDC). All of them share one infinite stream identified by LSN — the log sequence number that is the engine’s universal “before / after / same as” comparator on state.
Two implementation choices the WAL model leaves open shape every real engine and frame the rest of this document:
- How the LSN is named and how records are physically arranged.
A monotonic 64-bit counter is the textbook answer; in practice
the address is decomposed into
(page_id, in-page offset)so the reader can resolve a record without scanning. The trade-off is between number space (how long until you wrap) and locality (how cheaply you can fetch a record). - How the in-memory side of the log is disciplined. The naive answer is “every appender writes its own record into the page buffer under a global lock.” Real engines instead construct records into a staging list (prior list, log batch, group buffer) under a smaller lock, then a single thread drains that list into the page buffer and flushes. The discipline shows up as different latency profiles at commit time: do we force on every commit, or do we wait for a small window of peers and force them together (group commit)?
CUBRID answers both questions concretely. The next section names the shared engineering vocabulary every WAL engine uses to answer them.
Common DBMS Design
Section titled “Common DBMS Design”Almost every WAL-based engine — PostgreSQL, InnoDB, Oracle, SQL Server, and CUBRID — composes the log out of the same handful of patterns. The patterns are not in Database Internals’s ARIES chapter; they are the engineering vocabulary that lives between the textbook and the source.
LSN as identity
Section titled “LSN as identity”The LSN names a position in the log, but engines also use it as the
equality predicate on page state. Every dirty data page carries
the LSA of the most-recent log record that modified it. The flush
rule on the buffer pool side then becomes simple: a data page may
only be written to disk after the log record whose LSA matches has
been forced. The same LSA serves the recovery manager during the
analysis pass to decide which pages need redo. PostgreSQL calls it
XLogRecPtr, InnoDB calls it lsn_t, CUBRID calls it LOG_LSA —
the structure differs but the role is the same.
Log records as a typed union
Section titled “Log records as a typed union”A log record’s first bytes are a fixed header (back-LSA, forward-LSA,
trid, type) followed by a payload whose shape depends on the type.
The type set is small (~30 in CUBRID, ~70 in InnoDB) and is treated
as a closed enum so a recovery dispatch table can map it to a
function pointer per-record. The payload itself is rarely
self-describing; the type tells the reader how to parse the rest.
Engines that started physical (InnoDB) or logical (PostgreSQL via
output plugins) and added the other later end up with hybrid
record-type sets — CUBRID’s LOG_REDO_DATA is physiological, but
LOG_SYSOP_END_LOGICAL_* carries logical undo for index operations
that touch many pages.
Append buffer as a single-writer pipeline
Section titled “Append buffer as a single-writer pipeline”A multi-writer log buffer is a contention bottleneck. The standard escape is a two-stage pipeline: appenders construct records into a prior list (linked list of staged records under a small mutex), and a single drain thread (or the log critical section under write-mode) walks the prior list and copies records into the log page buffer in LSN order. The prior list is the engine’s unit of “I am going to commit a batch”, and its head/tail pointers are the only structures that need to be touched under the prior-LSA mutex.
Force-at-commit and group commit
Section titled “Force-at-commit and group commit”The commit log record must be on stable storage before the client sees a successful commit. The naive policy — fsync per commit — is prohibitive on rotating media and still expensive on SSDs. Group commit is universal: a committing transaction places its commit record into the prior list, requests “force everything up to my LSA”, and parks. The drainer fsyncs once for many waiters. The trade-off shows up as commit latency vs. throughput; engines tune the window.
Active log and archives
Section titled “Active log and archives”The on-disk log is two-tier: a fixed-size active log (a circular file or a small set of pages) plus an arbitrary chain of archive log volumes that are read-only after creation. Archives exist for media recovery (replay from a backup) and historical reads (CDC tail, flashback). The boundary between active and archive moves forward as checkpoints establish that all earlier records’ redo no longer matters.
Theory ↔ CUBRID mapping
Section titled “Theory ↔ CUBRID mapping”| Theoretical concept | CUBRID name |
|---|---|
| LSN — log sequence number | LOG_LSA — packed pageid:48 / offset:16 bit-field (log_lsa.hpp) |
| Log record header (back/forward/trid/type) | LOG_RECORD_HEADER (log_record.hpp) |
| Log record type enum | LOG_RECTYPE — 35+ entries from LOG_UNDOREDO_DATA to LOG_SUPPLEMENTAL_INFO |
| Per-record recovery function table | LOG_RCVINDEX (recovery.h) → (undofun, redofun) in RV_fun[] |
| Staged record before page-buffer copy | LOG_PRIOR_NODE linked into LOG_PRIOR_LSA_INFO (log_append.hpp) |
| Prior-list mutex | log_prior_lsa_info::prior_lsa_mutex |
| Drain into page buffer (single writer) | logpb_prior_lsa_append_all_list (log_page_buffer.c) |
| Append cursor & last-flushed LSA | log_append_info::nxio_lsa (atomic) + prev_lsa |
| Force-flush of pages | logpb_flush_all_append_pages / logpb_force_flush_pages |
| Group-commit waiter | LOG_FLUSH_INFO + condition variable in log_page_buffer.c flush daemon |
| Active log header | LOG_HEADER in page LOGPB_HEADER_PAGE_ID = -9 (log_storage.hpp) |
| Per-page header | LOG_HDRPAGE with checksum + flags |
| Archive log header | LOG_ARV_HEADER |
| Compensation log record (CLR) | LOG_COMPENSATE + log_append_compensate |
| Postpone (deferred actions on commit) | LOG_POSTPONE + LOG_RUN_POSTPONE |
| MVCC-flavoured records | LOG_MVCC_UNDOREDO_DATA, LOG_MVCC_UNDO_DATA, LOG_MVCC_REDO_DATA |
| Supplemental records for CDC | LOG_SUPPLEMENTAL_INFO + SUPPLEMENT_REC_TYPE (DDL, INSERT/UPDATE/DELETE LSA pointers) |
By the time we name a CUBRID symbol in the next section, the reader already knows what kind of structure to expect.
CUBRID’s Approach
Section titled “CUBRID’s Approach”CUBRID has four moving parts on the log path: the LSA scheme that names every record, the typed log record that lives at that address, the prior list where records are staged before they reach a page, and the log page buffer + flush daemon that drives records to disk. We walk them in that order.
Overall structure
Section titled “Overall structure”
Figure 1 — Three-tier log pipeline. Transaction threads append into the prior list, the drainer copies nodes into the LOG_PAGE ring buffer, and the flush daemon writes pages to the active log file; each boundary serialises one concern without blocking the others.
The figure encodes the three boundaries that matter for correctness: (prior-list boundary) appenders see only their own node and the list tail under one mutex; (page-buffer boundary) the drain thread is the single writer of LSAs into pages; (disk boundary) the flush daemon is the single writer of pages to the active log file. Each boundary serializes one concern (record ordering, LSA assignment, durability) without serializing the others.
LSA — naming a position in the log
Section titled “LSA — naming a position in the log”The LSA is a 64-bit packed value: 48 bits of logical page id, 16 bits
of in-page offset. CUBRID exposes it both as a struct with operators
and as a set of macro shims (LSA_COPY, LSA_LT, …) for the C side.
// struct log_lsa — src/transaction/log_lsa.hppstruct log_lsa{ std::int64_t pageid:48; /* Log page identifier : 6 bytes */ std::int64_t offset:16; /* Offset in page : 2 bytes (defined as 16-bit INT64 for alignment) */
inline log_lsa () = default; inline constexpr log_lsa (std::int64_t log_pageid, std::int16_t log_offset);
constexpr inline bool is_null () const; constexpr inline bool is_max () const;
constexpr inline bool operator== (const log_lsa &olsa) const; inline bool operator< (const log_lsa &olsa) const; // ... condensed ...};
constexpr std::int64_t NULL_LOG_PAGEID = -1;constexpr std::int16_t NULL_LOG_OFFSET = -1;constexpr log_lsa NULL_LSA { NULL_LOG_PAGEID, NULL_LOG_OFFSET };constexpr log_lsa MAX_LSA = { /* 47-bit max */, /* 15-bit max */ };
Figure 2 — How a position in the log is named. The 64-bit log_lsa
packs a 48-bit logical page id and a 16-bit in-page offset. The page
field gives a ~500-petabyte log address space before wrap; the offset
is signed-16 for alignment but is really bounded by the log page size.
Lexicographic ordering on (pageid, offset) is the comparator every
monotonicity check in the append path relies on.
Three points worth marking up. (a) The bit-field decomposition
means pageid saturates at 2^47 − 1 ≈ 1.4 × 10^14 logical pages.
With db_logpagesize typically 4 KiB, that is a log address space
of roughly 5 × 10^17 bytes — five hundred petabytes — before
exhaustion. The 16-bit offset is signed for alignment, but its
maximum is bounded by LOG_PAGESIZE, not INT16_MAX. (b) <
is lexicographic on (pageid, offset), which is the comparator the
prior-list and page-buffer drain rely on to enforce monotonicity.
(c) NULL_LSA is (-1, -1). is_null() checks only pageid
because that is the field engines mostly read; set_null() writes
both to silence valgrind on partially-initialised structs (the
inline comment in log_lsa.hpp calls this out explicitly).
Log record — header plus typed payload
Section titled “Log record — header plus typed payload”Every record begins with LOG_RECORD_HEADER, immediately followed by
a type-specific header struct, which is followed by zero or more
data buffers (undo image, redo image, key, OID, …).
// LOG_RECORD_HEADER and the record-type enum — src/transaction/log_record.hppstruct log_rec_header{ LOG_LSA prev_tranlsa; /* Address of previous log record for the same transaction */ LOG_LSA back_lsa; /* Backward log address */ LOG_LSA forw_lsa; /* Forward log address */ TRANID trid; /* Transaction identifier */ LOG_RECTYPE type; /* Log record type */};
enum log_rectype{ LOG_SMALLER_LOGREC_TYPE = 0, /* lower bound check */ LOG_UNDOREDO_DATA = 2, /* an undo and redo data record */ LOG_UNDO_DATA = 3, LOG_REDO_DATA = 4, LOG_DBEXTERN_REDO_DATA = 5, LOG_POSTPONE = 6, LOG_RUN_POSTPONE = 7, LOG_COMPENSATE = 8, /* CLR — compensate an undone undo */ LOG_COMMIT_WITH_POSTPONE = 14, LOG_COMMIT = 17, LOG_SYSOP_START_POSTPONE = 18, LOG_SYSOP_END = 20, /* nested top-op end (commit / abort / logical) */ LOG_ABORT = 22, LOG_START_CHKPT = 25, LOG_END_CHKPT = 26, LOG_SAVEPOINT = 27, LOG_2PC_PREPARE = 28, /* 2PC voted yes */ /* LOG_2PC_START / COMMIT_DECISION / ABORT_DECISION / INFORM / RECV_ACK ... */ LOG_END_OF_LOG = 35, LOG_DUMMY_HEAD_POSTPONE = 36, /* no-op markers */ LOG_DUMMY_CRASH_RECOVERY = 37, LOG_REPLICATION_DATA = 39, LOG_REPLICATION_STATEMENT = 40, LOG_DIFF_UNDOREDO_DATA = 43, /* diff undo+redo to save space */ LOG_DUMMY_HA_SERVER_STATE = 44, LOG_DUMMY_OVF_RECORD = 45, /* overflow-record marker */ LOG_MVCC_UNDOREDO_DATA = 46, /* MVCC variant: carries MVCCID + vacuum info */ LOG_MVCC_UNDO_DATA = 47, LOG_MVCC_REDO_DATA = 48, LOG_MVCC_DIFF_UNDOREDO_DATA = 49, LOG_SYSOP_ATOMIC_START = 50, LOG_DUMMY_GENERIC = 51, /* "ridiculous, but flush needs it" — comment in header */ LOG_SUPPLEMENTAL_INFO = 52, /* CDC supplemental: tran user, DDL, undo/redo LSA, raw image */ LOG_LARGER_LOGREC_TYPE,};The triple-LSA in the header (prev_tranlsa, back_lsa, forw_lsa)
is the structure ARIES needs at recovery time. prev_tranlsa chains
records belonging to the same transaction and is the entry point for
rollback (the undo pass walks the chain backward from the
transaction’s tail). back_lsa and forw_lsa chain records in
physical order on the log so the analysis and redo passes can scan
forward without re-reading every page header. The MVCC-flavoured
records add an MVCCID and a LOG_VACUUM_INFO (prev_mvcc_op_log_lsa
vfid) so the vacuum subsystem can walk MVCC operations without re-parsing the entire log. The type set is intentionally append-only: old code (commented-out#if 0blocks forLOG_CLIENT_NAME,LOG_LCOMPENSATE,LOG_UNLOCK_COMMIT) is preserved as numbered holes so a binary log compatible with old releases still parses.

Figure 3 — A record and its links. Each record is a fixed
LOG_RECORD_HEADER, then a type-specific header, then zero or more
data buffers. The header carries three LSAs that build two
independent chains: back_lsa / forw_lsa thread every record in
physical log order (so the analysis and redo passes scan forward),
while prev_tranlsa (the thick edge) chains only the records of one
transaction — note it skips trid 9 to link trid 7’s two records,
which is the chain the undo pass walks backward at rollback.
The type tag in the header selects which payload shape follows, out of a small closed set. Grouping the ~35 constants by role shows the union the recovery dispatch table is built around:

Figure 4 — The record-type taxonomy. The enum is one flat closed
set, but every constant falls into one of seven roles. The data /
recovery family is the hot path (undo, redo, CLR, postpone); the MVCC
family carries the extra MVCCID + vacuum link; the replication / CDC
family is the out-of-band channel covered in cubrid-cdc.md and
cubrid-ha-replication.md. The dummy markers are no-ops the flush and
recovery machinery lean on.
A specific union worth marking up is LOG_REC_SYSOP_END, the record
written when a system op (a sub-transactional unit of recovery)
finishes:
// LOG_REC_SYSOP_END — src/transaction/log_record.hppstruct log_rec_sysop_end{ LOG_LSA lastparent_lsa; /* last address before the top action */ LOG_LSA prv_topresult_lsa; /* previous top action's end LSA */ LOG_SYSOP_END_TYPE type; /* COMMIT | ABORT | LOGICAL_UNDO | LOGICAL_MVCC_UNDO | LOGICAL_COMPENSATE | LOGICAL_RUN_POSTPONE */ const VFID *vfid; union { LOG_REC_UNDO undo; /* logical undo */ LOG_REC_MVCC_UNDO mvcc_undo; /* logical MVCC undo */ LOG_LSA compensate_lsa; /* logical compensate */ struct { LOG_LSA postpone_lsa; bool is_sysop_postpone; } run_postpone; };};A “system op” in CUBRID is the engine’s private nested transaction — used by index splits, heap-overflow allocations, and other operations that need to be atomic as a group even though they touch many pages. The union carries either the logical-undo image (so recovery can reverse the system op without replaying its physical changes backward), or the LSA of the postpone record (so a postpone interrupted by crash can resume), or the LSA of the compensate target (so an undone system op leaves a clean trail). The type constant on the record selects which arm is live.

Figure 5 — The system-op end record. System ops nest on the
transaction’s topops.stack[]; when the innermost one finishes it
emits a LOG_REC_SYSOP_END whose type discriminates a union. A
plain COMMIT / ABORT carries no extra payload, but the four
logical variants each carry exactly the LSA or undo image recovery
needs to reverse a multi-page operation (index split, overflow grow)
as one atomic unit rather than replaying its physical page changes
backward.
The prior list — staging before the page buffer
Section titled “The prior list — staging before the page buffer”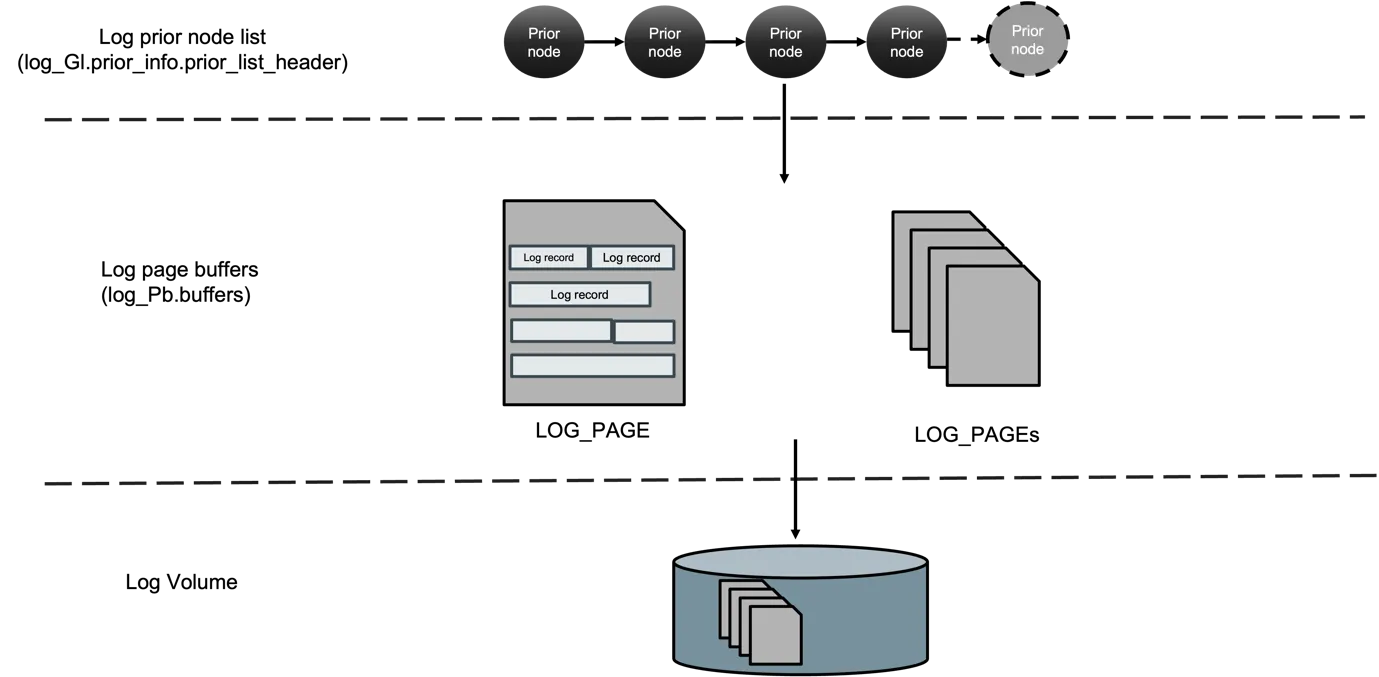
Figure 6 — The three storage tiers a log record passes through. At the
top, transactions chain LOG_PRIOR_NODE values onto the prior list at
log_Gl.prior_info.prior_list_header. The drain thread copies nodes
into log_Pb.buffers — an in-memory ring of LOG_PAGE frames — and
the flush daemon writes those pages to the active log volume on disk.
The dashed boundaries are the three serialization points the prose
below names: prior-list mutex, single-writer drain, single-writer
flush. (Source: log manager_v0.5.docx, prior-list overview figure.)
When a transaction wants to log an undo+redo data record, it calls
prior_lsa_alloc_and_copy_data (log_append.cpp:273). The function
allocates a LOG_PRIOR_NODE, fills the header type-specific fields
from the caller-supplied buffers, and returns a node that does not
yet have an LSA.
// LOG_PRIOR_NODE / LOG_PRIOR_LSA_INFO — src/transaction/log_append.hppstruct log_prior_node{ LOG_RECORD_HEADER log_header; LOG_LSA start_lsa; /* assertion-only — assigned on attach */ bool tde_encrypted;
int data_header_length; char *data_header;
int ulength; /* undo length */ char *udata; int rlength; /* redo length */ char *rdata;
LOG_PRIOR_NODE *next;};
struct log_prior_lsa_info{ LOG_LSA prior_lsa; /* next LSA to assign */ LOG_LSA prev_lsa; /* last attached node's LSA */
LOG_PRIOR_NODE *prior_list_header; LOG_PRIOR_NODE *prior_list_tail; INT64 list_size; /* bytes */ LOG_PRIOR_NODE *prior_flush_list_header;
std::mutex prior_lsa_mutex;};The transaction then calls prior_lsa_next_record (1553) — or
prior_lsa_next_record_with_lock (1559) when it already holds the
prior mutex — to attach the node. Attaching is two coordinated
operations under the mutex: assign prior_lsa to the node’s
start_lsa, and append the node to the tail of prior_list. The
returned LSA is the transaction’s “I have logged this” promise.
// prior_lsa_next_record_internal — src/transaction/log_append.cppLOG_LSAprior_lsa_next_record_internal (THREAD_ENTRY *thread_p, LOG_PRIOR_NODE *node, LOG_TDES *tdes, int with_lock){ // ... condensed ... if (with_lock == LOG_PRIOR_LSA_WITHOUT_LOCK) log_Gl.prior_info.prior_lsa_mutex.lock ();
start_lsa = log_Gl.prior_info.prior_lsa; prior_lsa_start_append (thread_p, node, tdes); /* assigns node->start_lsa, bumps prior_lsa by record size */ prior_lsa_end_append (thread_p, node); /* attaches to prior_list tail */
if (with_lock == LOG_PRIOR_LSA_WITHOUT_LOCK) log_Gl.prior_info.prior_lsa_mutex.unlock ();
return start_lsa;}Two properties fall out of this discipline. (a) The mutex is
held for the duration of “decide where the record lives” plus
“attach” — both O(1). The actual record copy from caller buffers
happened earlier in prior_lsa_alloc_and_copy_data, outside the
mutex, so the critical section is short. (b) Because attaching
also assigns the LSA, a transaction’s LSA totally orders against
every other transaction’s LSA: there is no “I appended at LSA X but
my neighbour at X+δ committed first” race.
The page buffer drain — single-writer LSN order
Section titled “The page buffer drain — single-writer LSN order”The next stage is the drain. logpb_prior_lsa_append_all_list
(log_page_buffer.c:3106) is called by the log critical section,
the flush daemon, and any path that needs to ensure records are in
the page buffer. Its job is to walk the prior list and copy each
node into the appropriate LOG_PAGE. Each copy looks up — and
allocates if needed — pages from the page buffer pool initialised
by logpb_initialize_pool (553).
// logpb_prior_lsa_append_all_list — src/transaction/log_page_buffer.cintlogpb_prior_lsa_append_all_list (THREAD_ENTRY *thread_p){ // ... condensed ... /* Detach the prior list under the mutex; release it; copy outside. */ std::unique_lock<std::mutex> lk (log_Gl.prior_info.prior_lsa_mutex); LOG_PRIOR_NODE *first = log_Gl.prior_info.prior_list_header; log_Gl.prior_info.prior_list_header = NULL; log_Gl.prior_info.prior_list_tail = NULL; log_Gl.prior_info.list_size = 0; lk.unlock ();
for (LOG_PRIOR_NODE *node = first; node != NULL; node = node->next) { logpb_append_next_record (thread_p, node); if (logpb_is_page_in_archive (...)) /* page boundary crossing */ logpb_next_append_page (thread_p, ...); logpb_free_node (node); } return NO_ERROR;}Two properties that matter for correctness. (a) The drain is a
single writer into the log page buffer; the prior-list mutex
serialises appenders against each other, the drain mutex
serialises appenders against the drain. (b) Page boundaries
are crossed by logpb_next_append_page (2630), which marks the
current page dirty in the flush info, allocates a new logical page,
and threads its physical descriptor.
Flush — making it durable
Section titled “Flush — making it durable”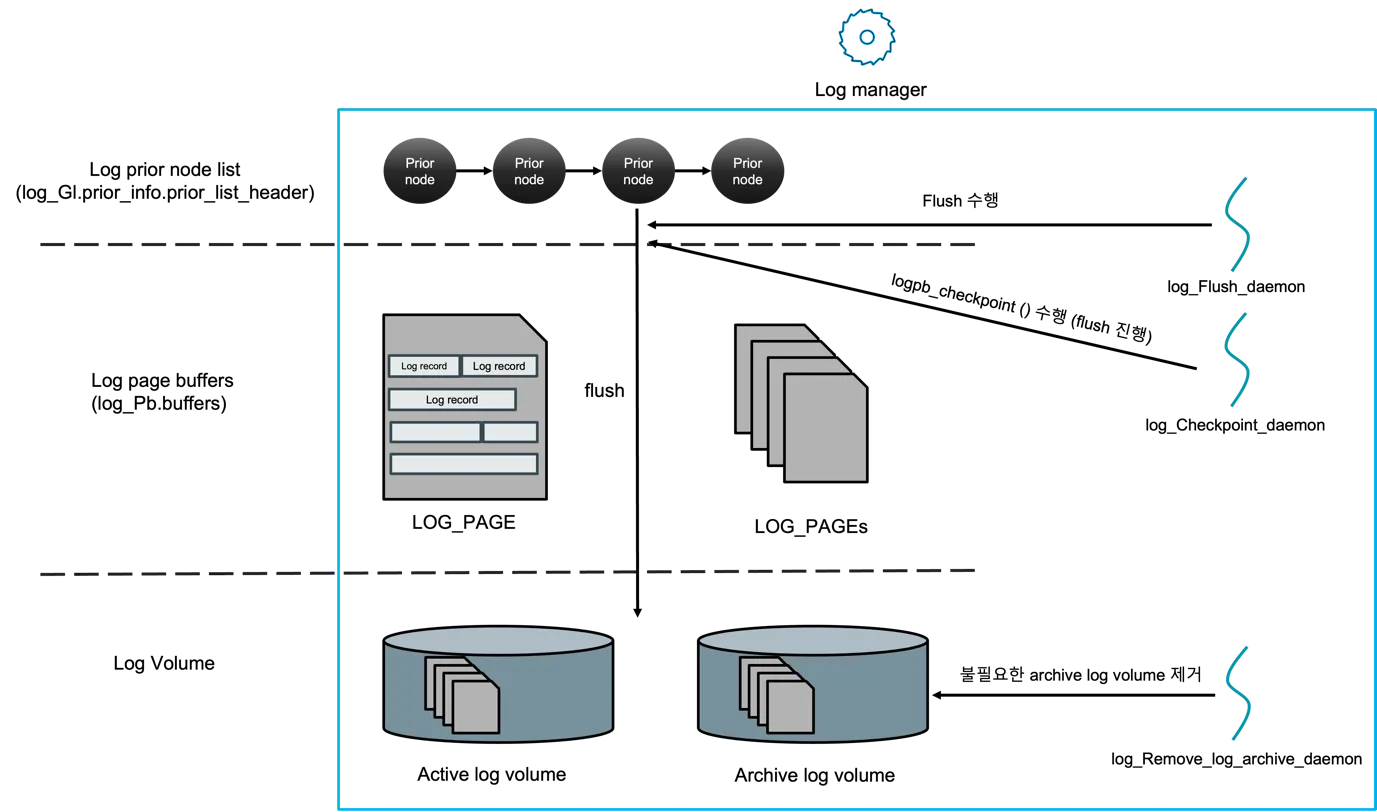
Figure 7 — Same three tiers as Figure 6, with the three log-manager
daemons attached. log_Flush_daemon is the actual writer to the
active log volume; log_Checkpoint_daemon periodically calls
logpb_checkpoint so the next analysis pass has a closer starting
LSA; log_Remove_log_archive_daemon reclaims archive volumes whose
records are no longer needed by any HA replica or backup. The daemons
are the only writers to disk — appenders never block on I/O
themselves. (Source: log manager_v0.5.docx, log-manager + daemons
figure.)
Flushing is the last stage. logpb_flush_all_append_pages (3232) is
the workhorse. It walks the dirty list of the page buffer, writes
each page to the active log file via the file_io subsystem, and
updates log_append_info::nxio_lsa — the next-IO LSA, the watermark
that says “everything below me is on stable storage”.
// log_append_info — src/transaction/log_append.hppstruct log_append_info{ int vdes; /* volume descriptor of active log */ std::atomic<LOG_LSA> nxio_lsa; /* lowest LSA not yet on disk */ LOG_LSA prev_lsa; /* last appended record */ LOG_PAGE *log_pgptr; /* the currently fixed log page */ bool appending_page_tde_encrypted;};The forced-flush path is logpb_force_flush_pages (4096), invoked at
commit (log_commit → logpb_force_flush_pages directly when the
HA configuration demands it, otherwise indirectly via the flush
daemon). The flush daemon (log_wakeup_log_flush_daemon —
declared in log_manager.h) sleeps on a condition variable and is
woken by appenders that need to be sure their record is on disk
before they return. The waiter checks nxio_lsa >= my_commit_lsa
on wake; if not, it sleeps again. This is the group-commit
implementation: many waiters, one fsync.
The corresponding read-side guarantee is the WAL invariant: a
data page flush in the buffer manager (pgbuf_flush_page_*) must
ensure nxio_lsa >= page->lsa before issuing the page write. CUBRID
enforces it in pgbuf_flush_check_log_lsa, which calls back into the
log manager to force as needed. (The buffer manager side is covered
in cubrid-page-buffer-manager.md.)
Compression, archiving, and the active-log header
Section titled “Compression, archiving, and the active-log header”Beyond the hot append path, the log manager owns three pieces of machinery that are not on the per-record path but matter for operability.
Compression. Records over log_Zip_min_size_to_compress are
compressed in place during prior_lsa_alloc_and_copy_data using zlib
through a per-thread LOG_ZIP context (log_compress.c,
log_append_get_zip_undo / log_append_get_zip_redo). The flag
log_Zip_support is a global toggle. The compression boundary is
the prior-list node, not the page; this means the record’s
compressed shape is stable across page boundaries and the recovery
side decompresses with the same context.
Archiving. The active log is fixed-size; once it fills, the
oldest pages roll over to an archive volume. LOG_ARV_HEADER names
each archive file (log_storage.hpp); nxarv_pageid and
nxarv_phy_pageid in LOG_HEADER track the next page to archive.
The archive remove daemon (log_wakeup_remove_log_archive_daemon)
deletes archives once the checkpoint LSA has moved past them and
no replication / CDC reader still depends on them.
Active-log header. LOG_HEADER, stored at logical page
LOGPB_HEADER_PAGE_ID = -9, is the bootstrap structure: it carries
the database creation time, page size, next transaction ID, next
MVCC ID, append LSA, checkpoint LSA, archive bookkeeping, HA state,
backup LSAs, and vacuum bookkeeping. The header is the single
source of truth for “where is the log up to” across crash boundaries.
Its eof_lsa is the LSN of LOG_END_OF_LOG, which the recovery
analysis pass uses to find the end of the legitimate log.

Figure 8 — The two-tier on-disk log. The active volume is a
fixed-size circular file; logical page -9 is the LOG_HEADER, the
bootstrap record copied into every archive so emergency recovery can
start from any volume. As the active log fills, its oldest pages roll
into a fresh, immutable archive volume (nxarv_pageid tracks the
boundary). The archive-remove daemon deletes an archive only once the
checkpoint LSA has moved past it and no CDC reader, HA replica, or
backup still depends on its page range.
The append APIs the rest of the engine sees
Section titled “The append APIs the rest of the engine sees”From outside the log manager, three families of entry points cover ~all uses:
// Append API surface — log_manager.h (excerpt)extern void log_append_undoredo_data (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int undo_length, int redo_length, const void *undo_data, const void *redo_data);extern void log_append_undo_data (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int length, const void *data);extern void log_append_redo_data (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int length, const void *data);extern void log_append_compensate (THREAD_ENTRY *, LOG_RCVINDEX, const VPID *, PGLENGTH, PAGE_PTR, int length, const void *data, LOG_TDES *);extern void log_append_postpone (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int length, const void *data);extern LOG_LSA *log_append_savepoint (THREAD_ENTRY *, const char *savept_name);
extern TRAN_STATE log_commit (THREAD_ENTRY *, int tran_index, bool retain_lock);extern TRAN_STATE log_abort (THREAD_ENTRY *, int tran_index);
extern void log_sysop_start (THREAD_ENTRY *);extern void log_sysop_commit (THREAD_ENTRY *);extern void log_sysop_abort (THREAD_ENTRY *);extern void log_sysop_end_logical_undo (THREAD_ENTRY *, LOG_RCVINDEX, const VFID *, int undo_size, const char *undo_data);The LOG_DATA_ADDR struct (log_append.hpp) bundles a page pointer,
a file id, and an in-page offset — the addressing the recovery side
will need to redo or undo. LOG_RCVINDEX is the dispatch key into
the global RV_fun[] array (recovery.h) that pairs a redo function
with an undo function for each record kind. The append API’s job is
to turn the caller’s (rcvindex, addr, payload) tuple into a
LOG_PRIOR_NODE of the right LOG_RECTYPE, attach it to the prior
list, and return.
Record lifecycle, end to end
Section titled “Record lifecycle, end to end”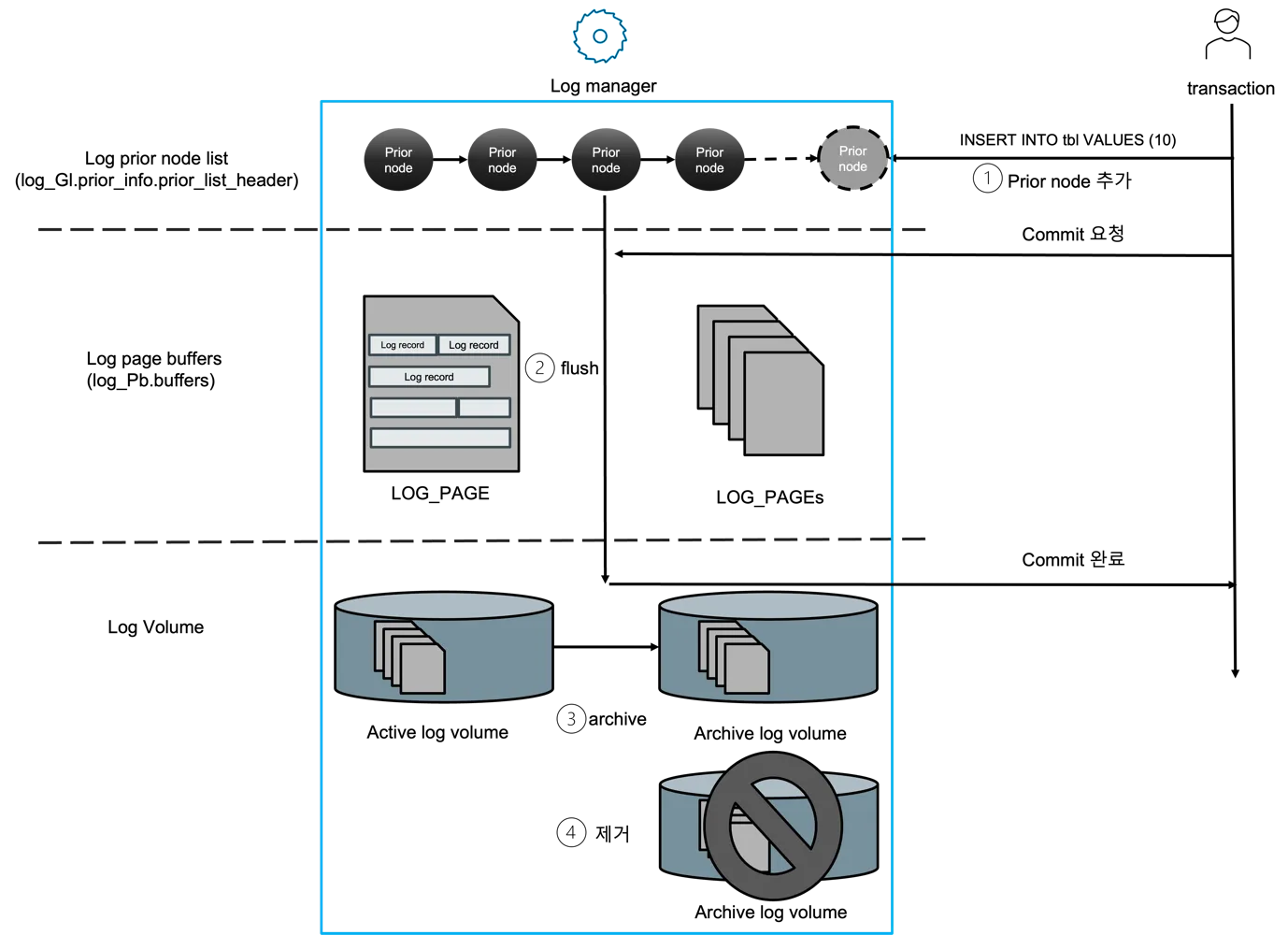
Figure 9 — A concrete INSERT INTO tbl VALUES (10) followed by
COMMIT, walked through the four numbered steps the deck used: ① the
transaction calls prior_lsa_alloc_and_copy_data and attaches the
new prior node; ② the drain copies the node into a LOG_PAGE and the
flush daemon writes it; ③ the active log volume eventually rolls into
an archive; ④ archives that no past replica still reads are removed.
Steps ① and ② happen inline with the commit (the caller blocks on
nxio_lsa); ③ and ④ are background. The sequence diagram
below adds the symbol-level call chain. (Source: log manager_v0.5.docx,
commit walkthrough figure.)

Figure 10 — Commit flush sequence. The transaction thread allocates a prior-list node and returns immediately; the flush daemon later forces pages up to the commit LSA and wakes blocked committers once nxio_lsa advances past their LSA.
The diagram shows the two interleaved orderings the design holds. LSA order is enforced at attach time by the prior-list mutex — every LSA the engine ever hands out is monotonically greater than the previous. Disk order is enforced at flush time by the single writer to the active log volume. The two orderings agree because the drain copies nodes in prior-list order and the flush writes pages in page-id order.
Source Walkthrough
Section titled “Source Walkthrough”Anchor on symbol names, not line numbers. Lines drift.
Header & types
Section titled “Header & types”log_lsa(log_lsa.hpp) — packedpageid:48 / offset:16LSN.LOG_RECORD_HEADER(log_record.hpp) — header at every record’s front, containingprev_tranlsa,back_lsa,forw_lsa,trid,type.LOG_RECTYPE(log_record.hpp) — closed enum of record kinds.LOG_PAGE/LOG_HDRPAGE/LOG_HEADER(log_storage.hpp) — the on-disk layout.LOG_PRIOR_NODE/LOG_PRIOR_LSA_INFO(log_append.hpp) — staged records between caller and page buffer.log_append_info(log_append.hpp) — global append cursor andnxio_lsa.
Prior-list (staging)
Section titled “Prior-list (staging)”prior_lsa_alloc_and_copy_data(log_append.cpp) — build a node from(rcvindex, addr, undo, redo), optionally zip.prior_lsa_alloc_and_copy_crumbs(log_append.cpp) — variant that takes a list ofLOG_CRUMBdata fragments.prior_lsa_next_record_internal(log_append.cpp) — assign LSA and attach to tail under prior mutex.prior_lsa_start_append/prior_lsa_end_append(log_append.cpp) — split halves of attach.log_append_undoredo_dataand friends (log_manager.c) — the surface the rest of the engine calls.
Page-buffer drain
Section titled “Page-buffer drain”logpb_initialize_pool(log_page_buffer.c) — set up the log page buffer pool ofLOGPB_BUFFER_NPAGES_LOWER+ pages.logpb_prior_lsa_append_all_list(log_page_buffer.c) — drain the prior list into the page buffer.logpb_next_append_page(log_page_buffer.c) — cross page boundary; mark current page dirty.
logpb_flush_all_append_pages(log_page_buffer.c) — write dirty pages to active log; advancenxio_lsa.logpb_force_flush_pages(log_page_buffer.c) — force-flush variant for commit demand and HA.log_wakeup_log_flush_daemon(log_manager.h) — wake the daemon that drives group-commit batching.
Lifecycle
Section titled “Lifecycle”log_create(log_manager.c) — create active log + header at database init.log_initialize(log_manager.c) — open / recover the log on server start.log_commit(log_manager.c) — appendLOG_COMMIT, force, release locks.log_abort(log_manager.c) — drive undo, appendLOG_ABORT.log_complete(log_manager.c) — final state transition; emits end-of-transaction record.log_final(log_manager.c) — graceful shutdown, force, writeLOG_HEADER::is_shutdown = true.
Compression & archive
Section titled “Compression & archive”log_append_init_zip/log_append_final_zip(log_append.cpp).log_append_get_zip_undo/log_append_get_zip_redo(log_append.cpp).log_wakeup_remove_log_archive_daemon(log_manager.h) — daemon that deletes obsolete archive volumes.
CDC integration (forward boundary)
Section titled “CDC integration (forward boundary)”cdc_*family (log_manager.h) —cdc_find_lsa,cdc_get_logitem_info,cdc_make_dml_loginfo,cdc_validate_lsa,cdc_min_log_pageid_to_keep. Exposed here because CDC walks the log forward throughlog_readerand depends on the log manager to keep the relevant range alive.
Position hints as of 2026-04-30
Section titled “Position hints as of 2026-04-30”| Symbol | File | Line |
|---|---|---|
log_lsa (struct) | log_lsa.hpp | 35 |
log_rec_header | log_record.hpp | 146 |
enum log_rectype | log_record.hpp | 35 |
log_rec_sysop_end | log_record.hpp | 305 |
log_prior_node | log_append.hpp | 91 |
log_prior_lsa_info | log_append.hpp | 112 |
log_append_info | log_append.hpp | 73 |
log_header | log_storage.hpp | 113 |
log_create | log_manager.c | 791 |
log_initialize | log_manager.c | 1059 |
log_append_undoredo_data | log_manager.c | 1893 |
log_append_redo_data | log_manager.c | 2035 |
log_commit | log_manager.c | 5352 |
log_abort | log_manager.c | 5461 |
log_complete | log_manager.c | 5653 |
prior_lsa_alloc_and_copy_data | log_append.cpp | 273 |
prior_lsa_alloc_and_copy_crumbs | log_append.cpp | 410 |
prior_lsa_next_record_internal | log_append.cpp | 1357 |
prior_lsa_next_record | log_append.cpp | 1553 |
prior_lsa_start_append | log_append.cpp | 1593 |
prior_lsa_end_append | log_append.cpp | 1652 |
logpb_initialize_pool | log_page_buffer.c | 553 |
logpb_next_append_page | log_page_buffer.c | 2630 |
logpb_prior_lsa_append_all_list | log_page_buffer.c | 3106 |
logpb_flush_all_append_pages | log_page_buffer.c | 3232 |
logpb_force_flush_pages | log_page_buffer.c | 4096 |
Source verification (as of 2026-04-30)
Section titled “Source verification (as of 2026-04-30)”Each entry is a fact about the current source — readable without the original analysis materials. Trailing notes show the verification trail.
Verified facts
Section titled “Verified facts”-
LOG_LSAis a 64-bit packed struct:pageid:48 / offset:16, defined as bit-fields onint64_t. Verified inlog_lsa.hpp:35. Theoffsetfield is intentionally typed asint64_t:16rather thanint16_tfor alignment; the comment in the source calls this out. Implication: a single log page must fit in 32 KiB minus a small header, since the offset is signed 16-bit; CUBRID’s defaultdb_logpagesizeis 4 KiB. -
Null LSA is
(-1, -1), butlog_lsa::is_null()checks onlypageid. Verified inlog_lsa.hpp:97-101and matchingset_null()at line 109. Theset_nullfunction explicitly writes both fields, with the inline comment “this is how LOG_LSA is initialized many times; we need to initialize both fields or we’ll have ‘conditional jump or move on uninitialized value’”. -
The append pipeline is two-stage: prior list → page buffer. Verified by reading
log_append.hpp(struct definitions),log_append.cpp(prior_lsa_*functions), andlog_page_buffer.c(logpb_prior_lsa_append_all_list). The prior-list mutex (prior_lsa_mutex) is the only lock appenders contend on; the drain is single-writer. -
LSA assignment happens inside the prior-list mutex, in
prior_lsa_start_append. Verified atlog_append.cpp:1593. This means LSAs are totally ordered by the order in which appenders take the mutex, not by when they copied their record bytes. Implication: the LSA returned fromlog_append_undoredo_datais a stable handle even for concurrent appenders. -
Group commit is implemented via a flush daemon woken by waiters on
nxio_lsa. Verified bylog_wakeup_log_flush_daemoninlog_manager.h:221pluslog_append_info::nxio_lsa(atomic) inlog_append.hpp:76. The daemon’s main loop is inlog_page_buffer.c(searchlog_flush_daemon); the waiter side islogpb_flush_all_append_pages. -
Log records are zlib-compressed in place when over a configured size threshold. Verified by
log_append_init_zip,log_append_get_zip_undo/_redoinlog_append.hpp:162-165andlog_compress.c. The toggle islog_Zip_support; the threshold islog_Zip_min_size_to_compress(both globals). -
The active log header lives at logical page id
-9, hard-coded asLOGPB_HEADER_PAGE_ID. Verified inlog_storage.hpp:51. It is kept on the active portion of the log and is backed up in all archive logs — this is what makes emergency recovery (log_restart_emergency) possible from any archive. -
Record types are append-only across releases. Verified in
log_record.hpp:35-141by counting the#if 0blocks for obsolete types (LOG_CLIENT_NAME = 1,LOG_LCOMPENSATE = 9,LOG_UNLOCK_COMMIT = 41, etc.). The numbered holes mean an old binary log is parseable by a current build. -
MVCC log records carry both
MVCCIDandLOG_VACUUM_INFO. Verified inlog_record.hpp:202-217(LOG_REC_MVCC_UNDOREDO,LOG_REC_MVCC_UNDO). Thevacuum_info.prev_mvcc_op_log_lsalinks MVCC operations into a chain the vacuum subsystem can walk without re-reading every other record. -
LOG_SUPPLEMENTAL_INFOis the channel CDC uses for catalog-visible events. Verified inlog_record.hpp:418-439(SUPPLEMENT_REC_TYPEenum) and thelog_append_supplemental_*declarations inlog_manager.h:171-179. The supplemental record type set includesTRAN_USER,DDL,INSERT/UPDATE/DELETE, andTRIGGER_INSERT/UPDATE/DELETE— the same set CDC consumers de-serialise on the downstream side (cubrid-cdc.md).
Open questions
Section titled “Open questions”-
What is the exact group-commit window policy? Is it a fixed timeout, a count-of-waiters threshold, or a hybrid? The flush daemon’s wake condition would tell us. Investigation path: read the daemon body in
log_page_buffer.c(search for thelog_flush_daemonfunction or thread entry), correlate withlog_writer.c(76 KB) which appears to drive the flush coordination. -
How is the prior-list size bounded?
LOG_PRIOR_LSA_INFO::list_sizeis tracked but its consumers / triggers were not located in this pass. Is there a soft cap that forces appenders to drain before continuing? Investigation path: grep forlist_sizeaccesses; look inlog_append.cppandlog_page_buffer.c. -
TDE-encrypted log pages: exact placement of encryption.
log_prior_node::tde_encryptedandlog_append_info::appending_page_tde_encryptedare present, but whether encryption happens at attach, drain, or flush time is unverified. Investigation path: readprior_set_tde_encryptedandprior_is_tde_encryptedinlog_append.cpp; correlate withtde.h. -
LOG_DUMMY_GENERIC(record type 51) — flush-only marker. The header comment calls it “ridiculous, but flush needs it”. What invariant does it preserve? A no-op record at a specific LSA forces page-boundary flush? Investigation path: grep for producers ofLOG_DUMMY_GENERIC; check if it is ever consumed by recovery dispatch. -
Active-log size policy.
LOG_HEADER::npagesis set at create time but the resize / rotation policy is not surfaced in the header. Is there a configurable knob? Investigation path: search fornpageswrites outside oflog_create_internal. -
CDC-keep-alive interaction with archive deletion.
cdc_min_log_pageid_to_keep(declared inlog_manager.h:235) gates the archive-remove daemon, but the synchronisation between CDC’s progress and the daemon was not traced. Investigation path: readlog_wakeup_remove_log_archive_daemonand followcdc_min_log_pageid_to_keepconsumers.
Beyond CUBRID — Comparative Designs & Research Frontiers
Section titled “Beyond CUBRID — Comparative Designs & Research Frontiers”Pointers, not analysis. Each bullet is a starting handle for a follow-up doc.
-
PostgreSQL XLOG —
XLogRecPtris a flat 64-bit LSN, decomposed into(timeline, segment, offset)outside the integer. The record format uses a separate “block-data” array per record rather than a packed payload. CUBRID’s prior-list staging maps cleanly to PG’sWAL insertion locks(multiple, hashed) — a comparison would tell us how CUBRID’s single prior mutex scales vs. PG’s striped locks. -
InnoDB redo log (mtr / log_t) — uses mini-transactions (
mtr_t) as the staging unit, then a fixed-size circular log file with a separatelog_bufring. Group commit is via theflush_loopthread on aos_event. ComparingLOG_RUN_POSTPONEagainst InnoDB’s deferred-buffer-pool work would isolate where the two engines disagree on “must be on disk before commit”. -
ARIES original (Mohan et al., 1992) — the canonical model for every WAL engine here. CUBRID’s three-LSA header (
prev_tranlsa,back_lsa,forw_lsa) is the ARIES record layout; the CLR viaLOG_COMPENSATEis the ARIES CLR. A side-by-side of CUBRID’sLOG_SYSOP_ENDagainst ARIES’s nested top-actions would surface where CUBRID extends the model (logical undo, MVCC undo). -
Aurora’s offload-WAL (Verbitski et al., SIGMOD 2017) — moves WAL into the storage layer so each compute node writes log records, not data pages. CUBRID’s WAL is process-local, so this is more of a structural contrast than a feature gap; comparing the protocols highlights what changes when “WAL is the database” rather than “WAL describes the database”.
-
Silo (Tu et al., SOSP 2013) and epoch-based recovery — alternative to ARIES that batches commits per-epoch. CUBRID’s group-commit window is a softer version of the same idea (force a small batch together) without the strict epoch boundary.
-
TimescaleDB / Hyper logging for time-series workloads — log compression strategies that exploit the columnar nature of redo data. CUBRID’s
LOG_DIFF_UNDOREDO_DATA(record type 43) is a primitive form of the same idea.
Sources
Section titled “Sources”Raw analyses (raw/code-analysis/cubrid/storage/)
Section titled “Raw analyses (raw/code-analysis/cubrid/storage/)”log_manager/log manager_v0.5.docxrecovery_manager/log_manager_v0.3.pptx— earlier deck filed under recovery_manager but covering the log manager surface.
Textbook chapters (under knowledge/research/dbms-general/)
Section titled “Textbook chapters (under knowledge/research/dbms-general/)”- Database Internals (Petrov), Ch. 5 “Transactions and Recovery”, §“Write-Ahead Logging” and §“Log Sequence Numbers”.
- Mohan et al., ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging (TODS 17.1, 1992) — referenced in the recovery doc but the LSN scheme and CLR design are first stated there.
CUBRID source (/data/hgryoo/references/cubrid/)
Section titled “CUBRID source (/data/hgryoo/references/cubrid/)”src/transaction/log_manager.{c,h}src/transaction/log_append.{cpp,hpp}src/transaction/log_record.hppsrc/transaction/log_lsa.{hpp,cpp}src/transaction/log_storage.hppsrc/transaction/log_page_buffer.csrc/transaction/log_compress.{c,h}src/transaction/log_writer.c
Sibling docs in this knowledge base
Section titled “Sibling docs in this knowledge base”knowledge/code-analysis/cubrid/cubrid-page-buffer-manager.md— data-page side of the WAL invariant.knowledge/code-analysis/cubrid/cubrid-mvcc.md— consumers ofLOG_MVCC_*records.knowledge/code-analysis/cubrid/cubrid-recovery-manager.md— reader of this log; in-progress in the same 2026-04-30 batch.knowledge/code-analysis/cubrid/cubrid-cdc.md— consumer ofLOG_SUPPLEMENTAL_INFO; in-progress in the same batch.knowledge/code-analysis/cubrid/cubrid-2pc.md— owner ofLOG_2PC_*records; in-progress in the same batch.