CUBRID Page Buffer Manager — BCB, Three-Zone LRU, Private Quotas, Direct Victim Handoff, and Custom Latches
Contents:
- Theoretical Background
- Common DBMS Design
- CUBRID’s Approach
- Source Walkthrough
- Source verification (as of 2026-04-29)
- Beyond CUBRID — Comparative Designs & Research Frontiers
- Sources
Theoretical Background
Section titled “Theoretical Background”A page buffer (or buffer pool) is the in-memory cache between the disk and every other module of a database engine. Disk I/O is several orders of magnitude slower than memory access, so the engine keeps a copy of recently-touched pages in RAM and routes all reads and writes through that copy. Database System Concepts (Silberschatz, Korth, Sudarshan, 6th ed., Ch. 13 “Storage and File Structure”) frames the buffer as the unit that lets the rest of the engine pretend disk latency does not exist — most pages are in memory most of the time, and the buffer manager is the component that maintains that illusion.
The textbook account names four pieces every buffer manager has:
- Page table — a hash from disk page identifier to in-memory buffer slot. Lookup is the hot path of every read.
- Free / replacement list — when a page is requested that is not in the buffer, an empty slot is found or a victim is chosen and evicted. The classical algorithm is LRU; refinements (clock, ARC, 2Q, LRU-K) trade accuracy against bookkeeping cost.
- Fix / unfix protocol — a thread that intends to read or modify
a page first fixes the buffer slot, increments a per-slot
reference count, and acquires a page latch (read or write).
While fixed, the slot cannot be evicted. Unfix releases the
latch and decrements the count. Distinct from transactional
locks — page latches are short, embedded in the buffer slot, and
unrelated to isolation (see
cubrid-lock-manager.md§“Lock vs latch separation”). - Write-ahead logging (WAL) integration — a dirty page (one modified since last flush) cannot be written to disk before the log records of those modifications are flushed. The classical reference is Mohan et al. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging (TODS 1992). The buffer manager and the log manager therefore have a one-way ordering constraint: log first, then page.
Two more architectural ingredients shape every modern implementation:
- Free-page coordination at high concurrency. When multiple threads simultaneously look for a victim, they would serialize on the LRU list under a naive lock. Real systems split the list into many smaller lists, each guarded by its own lock or running lock-free.
- Background flushers and double-write. Pages are flushed not
only when evicted but also by background daemons (PostgreSQL
bgwriter, MySQL
innodb_io_capacityflushers, CUBRID’s page flush daemon). Some engines additionally write each page to a double-write buffer before its real location, to recover from torn writes on systems whose disk page size differs from the database page size.
This document tracks how CUBRID realizes each of these pieces in
src/storage/page_buffer.{h,c} and the related
src/storage/double_write_buffer.{hpp,cpp}.
Common DBMS Design
Section titled “Common DBMS Design”The textbook gives the model; this section names the engineering
conventions that almost every DBMS buffer manager — PostgreSQL,
Oracle, MySQL InnoDB, SQL Server, CUBRID — adopts in some form.
CUBRID’s specific choices in ## CUBRID's Approach are best read as
one set of dials within this shared design space, not as inventions.
Buffer Control Block (BCB) — page metadata + the slot itself
Section titled “Buffer Control Block (BCB) — page metadata + the slot itself”The buffer pool is an array of fixed-size slots, one per cached
page. Each slot is wrapped by a small control block holding the
page’s identifier, latch state, fix count, dirty bit, LRU position,
and pointers used by the various lists the slot participates in.
PostgreSQL calls it BufferDesc, Oracle calls it a buffer header,
CUBRID calls it PGBUF_BCB. The data plane (the actual page bytes)
is separated from the control plane (metadata) so the pages
themselves can be aligned to the OS / disk page size for efficient
I/O.
Page table = hash from VPID to slot
Section titled “Page table = hash from VPID to slot”A hash table maps disk page identifier to BCB. CUBRID keys it on
VPID = (volid, pageid); PostgreSQL on BufferTag = (rel, fork, blocknum); the shape is the same. Sized once at server start
(CUBRID: 2²⁰ buckets fixed, chaining), the table is the hot path of
every page access and is therefore aggressively partitioned to avoid
contention.
Invalid (free) list of unused slots
Section titled “Invalid (free) list of unused slots”A small singly-linked list of slots that hold no page. New requests prefer this list; eviction (victim selection) is only run when it is empty. Splitting the “unused-slot” path from the “evict-someone-else” path is a universal optimization — it cuts the cost of common-case allocations by an order of magnitude.
Multi-zone LRU = recency-aware eviction
Section titled “Multi-zone LRU = recency-aware eviction”A pure LRU list is vulnerable to sequential flooding: one large scan touches every page in the database and pushes everything else out. Real systems use two or three zones — recently-touched pages live in a “hot” zone, fall through a “warm” middle zone if untouched, and only pages that drop into a “cold” zone are eligible for eviction. CUBRID has three zones (LRU 1 / 2 / 3 = top / middle / bottom). PostgreSQL’s clock-sweep, MySQL InnoDB’s mid-point insertion strategy, and Oracle’s touch-count are the same idea under different names.
Per-worker (private) LRUs against scan flooding
Section titled “Per-worker (private) LRUs against scan flooding”When many worker threads run concurrently, a single shared LRU list becomes both a contention bottleneck and an information bottleneck — one worker’s full table scan ruins another’s hot working set. The fix is per-thread (private) LRUs: each worker primarily promotes and evicts within its own LRU list, and pages migrate to the shared LRUs only when they survive the worker’s local replacement pressure. CUBRID’s private LRUs come with a per-list quota that adapts to recent hit activity.
Lock-free queues for victim coordination
Section titled “Lock-free queues for victim coordination”When the buffer is under pressure, many threads simultaneously look for a victim. Coordinating that search via a single lock is a disaster at high core counts. The standard fix: a lock-free circular queue of LRU lists known to currently contain at least one evictable page. Threads pop a list off the queue, scan it for a candidate, and (under contention) move on. CUBRID calls it LFCQ; the same data structure recurs in many engines.
Direct victim hand-off
Section titled “Direct victim hand-off”Even with private LRUs and LFCQs, there are moments when no candidate is immediately available. The naive answer is to spin or sleep on a global condition variable; the better answer is direct victim hand-off — a thread that frees a slot (e.g., a flush completing) hands it directly to a sleeping waiter via a per-thread slot in a static array. CUBRID implements this with two priority queues (high / low), giving vacuum workers and re-attempting allocators preference.
Custom user-level page latches
Section titled “Custom user-level page latches”OS mutexes are several hundred nanoseconds even on the fast path.
For the page latch — taken on every read and write of every page —
that overhead dominates. Real engines build a custom user-level
read/write latch on top of an atomic counter, often with a
holder/waiter list and explicit promotion. PostgreSQL has
LWLock, MySQL InnoDB has rw_lock_t, CUBRID has the BCB latch.
All include the same three primitives: read/write compatibility,
FIFO waiter wake, and read-to-write promotion.
Ordered fix to avoid multi-page deadlock
Section titled “Ordered fix to avoid multi-page deadlock”A heap operation that touches home page + forwarded page +
overflow page must take all three latches. If different threads
take them in different orders, deadlock is possible. The textbook
fix is ordered fix — every page has a numerical rank (e.g.,
heap-header < heap-normal < overflow), and pages are always fixed in
ascending rank order. CUBRID exposes this as pgbuf_ordered_fix +
the PGBUF_WATCHER struct. PostgreSQL solves the same problem by
relying on the index/heap protocol in _bt_findinsertloc-style
flows; the underlying constraint is identical.
Background flush daemons + double-write buffer
Section titled “Background flush daemons + double-write buffer”Several daemons run alongside foreground threads:
- Page Flush Daemon writes dirty pages out periodically.
- Page Post-Flush Daemon post-processes flushed pages, often handing them to direct-victim waiters.
- Page Maintenance Daemon adjusts private-LRU quotas based on recent activity.
To recover from torn pages (writes that complete only partially because the OS page size is smaller than the DB page size, e.g., 4K vs 16K), a double-write buffer is interposed between the page buffer and the disk. The page is written first to a sequential log-like region, then to its real location; on crash, the engine checks the DWB for any page whose real location is corrupt. Both MySQL InnoDB and CUBRID implement DWB; PostgreSQL relies on full-page-image WAL records instead.
Theory ↔ CUBRID mapping
Section titled “Theory ↔ CUBRID mapping”The textbook concepts of §“Theoretical Background” map to CUBRID’s
named entities as follows. ## CUBRID's Approach is the slow zoom
into each row.
| Theory | CUBRID name |
|---|---|
| Buffer control block | PGBUF_BCB (in page_buffer.c) |
| Physical page format on disk | FILEIO_PAGE (LSA + ptype + page contents) |
| Page identifier | VPID = (volid, pageid) |
| Page table (hash) | pgbuf_Pool.buf_HT[] (2²⁰ buckets, chaining) |
| Free / invalid list | pgbuf_Pool.buf_invalid_list |
| Three-zone LRU | LRU 1 / 2 / 3 = top / middle / bottom (per LRU list) |
| Per-worker LRUs | private LRU lists, one per worker thread |
| Adjustable quota per private list | pgbuf_adjust_quotas (Page Maintenance Daemon) |
| Lock-free victim coordination | LFCQ (big private / private / shared) |
| Direct victim hand-off | pgbuf_assign_direct_victim / pgbuf_get_direct_victim |
| Custom page latch | BCB latch (PGBUF_LATCH_READ / _WRITE / _FLUSH) |
| Per-VPID lock during alloc | PGBUF lock |
| Ordered fix to avoid deadlock | pgbuf_ordered_fix + PGBUF_WATCHER + PGBUF_ORDERED_RANK |
| Background flush | Page Flush / Post-Flush / Maintenance daemons |
| Torn-write recovery | Double Write Buffer (double_write_buffer.{hpp,cpp}) |
CUBRID’s Approach
Section titled “CUBRID’s Approach”CUBRID instantiates the conventions above with one global
pgbuf_Pool struct holding a fixed-size array of PGBUF_BCBs,
five state zones, three flavors of LFCQ, three background daemons,
and a custom BCB latch. The distinguishing choices are: (1) three
LRU zones (1 / 2 / 3) with 5 % default thresholds and old-enough
gating on boost; (2) per-worker private LRUs with adaptive
quotas, plus shared LRUs for pages that survive private
replacement pressure; (3) lock-free circular queues layered as
big-private / private / shared so victim search prefers the most
over-quota lists; (4) direct victim hand-off via a per-thread
slot in bcb_victims[], with two priority queues; (5) a custom
BCB latch with explicit promotion and a separate FLUSH wait state;
(6) a PGBUF lock at the VPID granularity to serialize
concurrent allocations of the same page.
How a page fix flows
Section titled “How a page fix flows”flowchart LR
A["pgbuf_fix(VPID, fetch_mode,\nlatch_mode, condition)"] --> B{"in page table?"}
B -- "yes" --> L["check BCB latch compatibility"]
L -- "compatible" --> F["fcnt++, return PAGE_PTR"]
L -- "incompatible" --> W["join waiter list,\nsleep until unlatched"]
W --> L
B -- "no" --> A1["pgbuf_claim_bcb_for_fix:\nallocate a BCB"]
A1 --> I{"invalid list\nempty?"}
I -- "no" --> G["take a free BCB"]
I -- "yes" --> V["pgbuf_get_victim:\nscan private/shared LFCQs"]
V --> V2{"victim found?"}
V2 -- "yes" --> G
V2 -- "no" --> D["sleep on direct-victim queue\n(High / Low priority)"]
D --> G
G --> R{"fetch_mode\n== NEW_PAGE?"}
R -- "no" --> RD["read from DWB; else from disk"]
R -- "yes" --> Z["zero-fill"]
RD --> P["insert into page table,\nfix latch, return PAGE_PTR"]
Z --> P
F --> END
P --> END[" "]
Figure 1 — pgbuf_fix page-fix flow. A page-table hit checks BCB latch compatibility and either grants immediately or joins the waiter list; a miss calls pgbuf_claim_bcb_for_fix, which searches the invalid list, then private and shared LFCQs via pgbuf_get_victim, sleeping on the direct-victim queue if all sources are exhausted.
Each labeled box is unpacked in the subsections below.
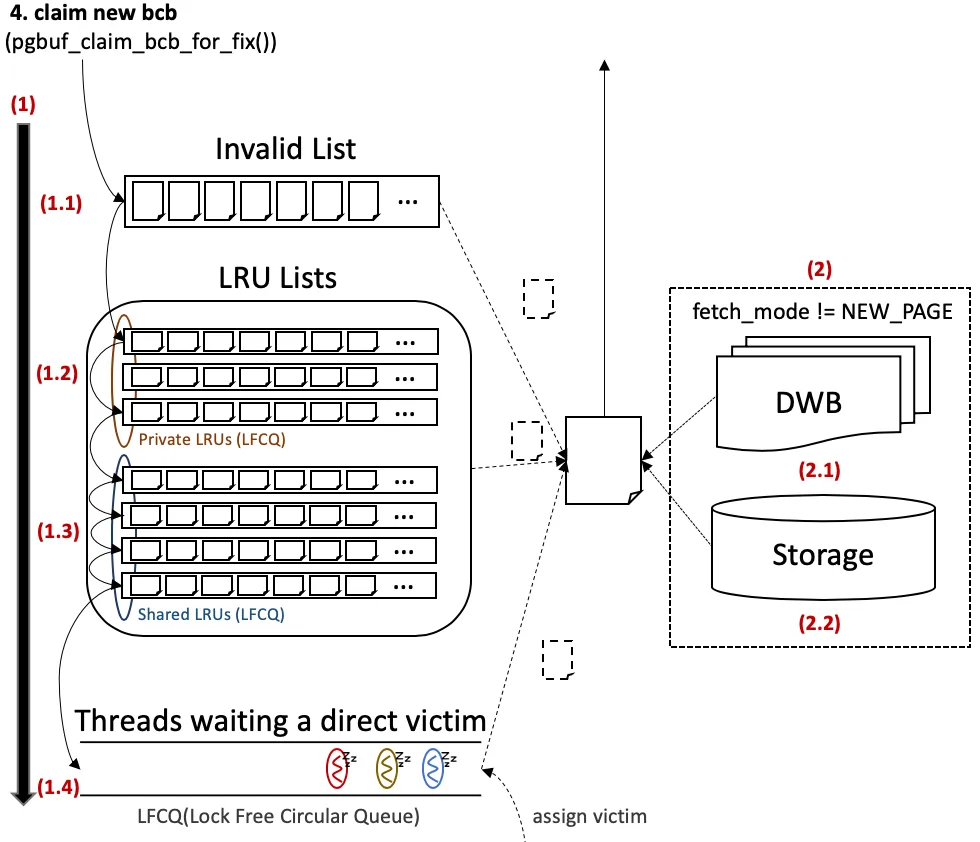
Figure 2 — The right half of the Mermaid above, drawn
with the deck’s own conventions. Step 1 searches three places
in order: (1.1) the Invalid List of free BCBs, (1.2) the
worker’s Private LRUs (via the LFCQ), (1.3) the Shared LRUs
(via the LFCQ); on miss, (1.4) the thread joins a direct-victim
LFCQ and sleeps. Step 2 — once a BCB is in hand and
fetch_mode != NEW_PAGE — the page bytes are loaded by checking
(2.1) the DWB first, then (2.2) the actual Storage if the
DWB has no copy. (Source: deck Figure 4.)
Buffer Control Block — PGBUF_BCB
Section titled “Buffer Control Block — PGBUF_BCB”A BCB wraps one buffer slot. It holds the page identifier, fix
count, latch state, dirty bit, LRU pointers, hash-chain pointers,
and pointers to the actual page bytes (PGBUF_IOPAGE_BUFFER).
// PGBUF_BCB (condensed) — src/storage/page_buffer.cstruct pgbuf_bcb{ pthread_mutex_t mutex; /* per-BCB mutex */ VPID vpid; /* (volid, pageid) of resident page */ int fcnt; /* fix count */ PGBUF_LATCH_MODE latch_mode; /* current latch mode */ THREAD_ENTRY *next_wait_thrd; /* head of waiter list */ volatile int flags; /* zone | LRU_index | BCB flags */
PGBUF_BCB *hash_next; /* hash chain (page table) */ PGBUF_BCB *prev_BCB; /* LRU chain — back */ PGBUF_BCB *next_BCB; /* LRU chain — forward */
int tick_lru_list; /* LRU bookkeeping */ int tick_lru3; int hit_age; volatile int count_fix_and_avoid_dealloc;
LOG_LSA oldest_unflush_lsa; /* oldest LSA not yet on disk */
PGBUF_IOPAGE_BUFFER *iopage_buffer; /* the page bytes */};The flags field packs several pieces of state into one 32-bit
word — see §“BCB flags” below. The data plane lives in
iopage_buffer, which carries a FILEIO_PAGE whose first 16 bytes
are the page’s LOG_LSA (last update LSN) and ptype (volume
header / heap / btree / …) — read by the page-write code to enforce
WAL ordering.
Page table — VPID hash
Section titled “Page table — VPID hash”// pgbuf_Pool.buf_HT[] — src/storage/page_buffer.c (sketch)// Fixed at 1 << 20 = 1,048,576 buckets, chaining, ~16M slot capacity.struct pgbuf_buffer_hash{ pthread_mutex_t hash_mutex; /* per-bucket mutex */ PGBUF_BCB *hash_next; /* head of BCB chain */ PGBUF_BUFFER_LOCK *lock_next; /* per-VPID lock chain (PGBUF lock) */};Two distinct chains hang off each bucket. The first is the BCB chain — every BCB whose VPID hashes to this bucket. The second is the PGBUF lock chain — used when a thread is mid-allocation and no BCB exists yet for the requested VPID. The PGBUF lock prevents two concurrent threads from both allocating a fresh BCB for the same VPID; the first wins, the second waits, observes the now- present BCB, and proceeds via the normal hash-hit path.
Invalid list — free pool
Section titled “Invalid list — free pool”flowchart LR S["server start"] --> I["all BCBs in invalid_list"] I --> AL["pgbuf_get_bcb_from_invalid_list\n(picks head)"] AL --> U["BCB now in VOID zone\n(transient)"] U --> P["after fix +unfix → LRU 2"] P --> Z["BCB lives in some zone\nfor the rest of its life"] Z -. "error path" .-> I
Figure 3 — Invalid-list BCB lifecycle. At server start all BCBs sit in invalid_list; pgbuf_get_bcb_from_invalid_list picks the head; after a successful fix-unfix cycle the BCB moves to LRU 2 and stays in some zone for its lifetime; an error path returns the BCB to the list.
A simple singly-linked list of BCBs not yet bound to any page. At server start all BCBs are here. The list is only consulted when a new BCB is needed; victim search is a separate mechanism. If an error occurs mid-allocation, the BCB is returned to this list.
Three-zone LRU lists
Section titled “Three-zone LRU lists”Each LRU list is a doubly-linked list of BCBs split into three
zones — top (LRU 1), middle (LRU 2), bottom (LRU 3) — by two
threshold counters (threshold_lru1, threshold_lru2, default
5 % each).
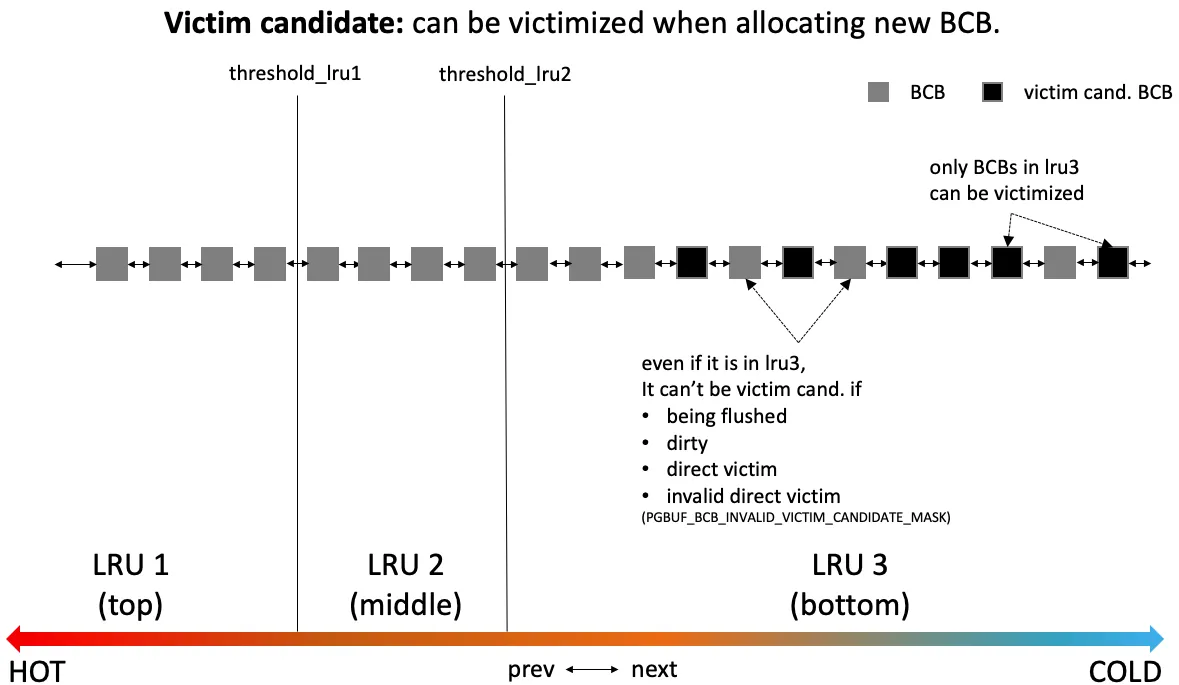
Figure 4 — A single LRU list with three zones. Black squares are victim candidates — only BCBs in LRU 3 (bottom) are eligible, and even there a BCB is excluded if it is currently being flushed, dirty, already chosen as a direct victim, or marked as an invalid direct victim. Promotions move a BCB toward LRU 1 on hit; demotions push it toward LRU 3 over time. Eviction always picks from the cold end. (Source: original Buffer Manager analysis deck, Figure 6.)
The four exclusion conditions in the figure correspond to flags on the BCB:
PGBUF_BCB_FLUSHING_TO_DISK_FLAG— flush in progress.PGBUF_BCB_DIRTY_FLAG— modified since last flush; cannot evict before the WAL is on disk.PGBUF_BCB_VICTIM_DIRECT_FLAG— already promised to a sleeping waiter via direct hand-off.PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG— was promised but is no longer eligible because it was re-fixed.
Private LRU lists + adaptive quota
Section titled “Private LRU lists + adaptive quota”flowchart TB
subgraph PRIVATE["Private LRU lists (one per worker)"]
P1["worker 1 LRU\n(LRU 1/2/3 zones)"]
P2["worker 2 LRU"]
Pn["worker N LRU"]
end
subgraph SHARED["Shared LRU lists"]
S1["shared LRU 1"]
S2["shared LRU 2"]
Sm["shared LRU M"]
end
PMD["Page Maintenance Daemon\n(every 100 ms)"]
PMD -- "measures activity\n(hits per list)" --> P1
PMD -- "redistributes" --> P2
PMD -- "shared thresholds" --> S1
P1 -- "hot AND old enough\n(fix ≥ 64), or\nunfix by other thread" --> S1
P2 -- "..." --> S2
Figure 5 — Private and shared LRU list topology. Each worker thread owns a private LRU (three zones); BCBs that grow hot enough or are unfixed by a foreign thread migrate to one of the shared LRU lists; the Page Maintenance Daemon (pgbuf_adjust_quotas) measures per-list hit activity every 100 ms and redistributes quotas.
Each worker thread owns a private LRU list; new BCBs allocated by that worker are inserted into its private list. When a BCB grows old enough (more than half of LRU 2 has been pushed past it) and hot (fix count ≥ 64), or when it is unfixed by a thread other than the one that fixed it, the BCB is migrated to a shared LRU list. Shared lists hold pages that survived their owner’s eviction pressure.
The adaptive quota logic runs every 100 ms in the Page
Maintenance Daemon (pgbuf_adjust_quotas):
- Compute total hits across all private LRUs in the last interval.
- Compute the private ratio = hits in private / total hits.
all_private_quota = (total_buffers - invalid) * private_ratio.- Distribute
all_private_quotaacross private lists in proportion to per-list activity. - Recompute per-list
threshold_lru1/threshold_lru2from the new quota. - Distribute the remaining buffers equally as the threshold base for shared lists.
Quota matters for victim search — a private list is eligible to be victimized from only if its BCB count exceeds its quota. This keeps each worker’s hot pages within its own quota, and forces eviction onto workers (and pages) that grew beyond their share.
LFCQ — victim selection
Section titled “LFCQ — victim selection”When a BCB allocator needs to evict, it walks lock-free circular queues of LRU lists, each carrying lists known to contain at least one victim candidate.
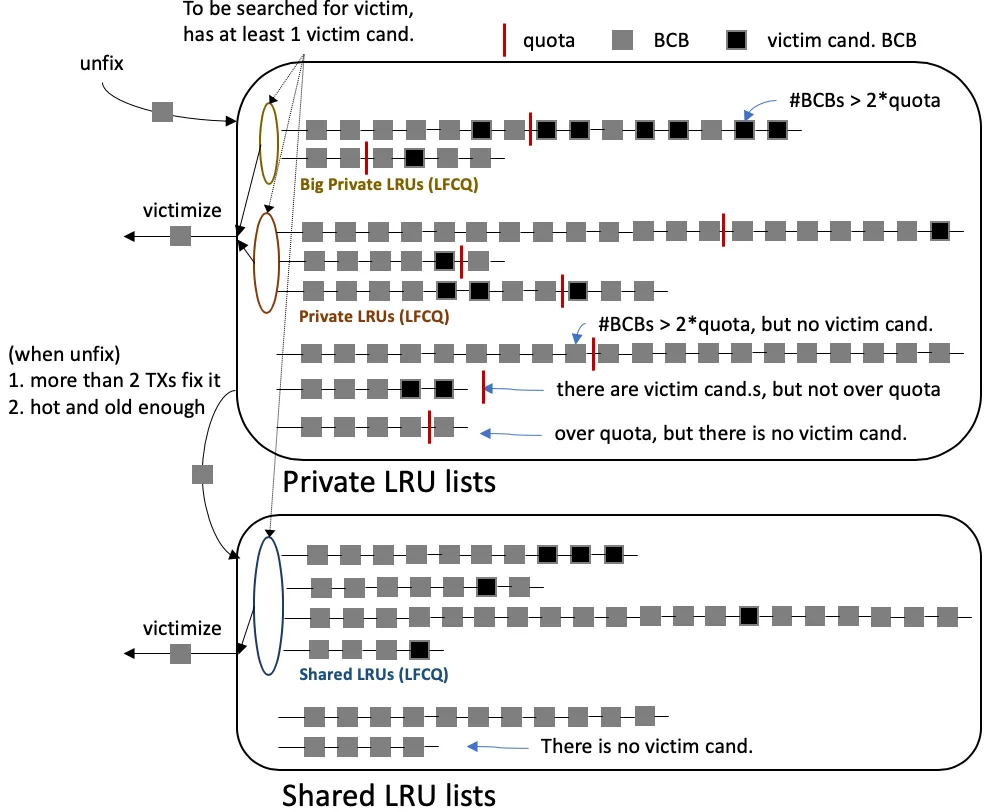
Figure 6 — Three LFCQs partition the victim search. Big Private LRUs (top) hold private lists whose BCB count exceeds 2× their quota — these are searched first because they are over-quota and likely have many candidates. Private LRUs (middle) hold private lists with at least one candidate but BCB count ≤ 2× quota. Shared LRUs (bottom) are scanned last. Each list joins the LFCQ only when it has at least one victim candidate; lists with no candidate are skipped entirely. (Source: deck Figure 9.)
// pgbuf_get_victim (sketch) — src/storage/page_buffer.cPGBUF_BCB *pgbuf_get_victim (THREAD_ENTRY *thread_p){ /* 1. Try this worker's own private LRU list first. */ /* 2. Try big-private LFCQ (#BCBs > 2 * quota). */ /* 3. Try private LFCQ. */ /* 4. Try shared LFCQ. */ /* 5. If none found → caller will sleep on direct-victim queue. */}Direct victim hand-off
Section titled “Direct victim hand-off”A thread that fails all four LFCQ steps does not retry — it sleeps on a per-thread slot until a victim is handed to it.
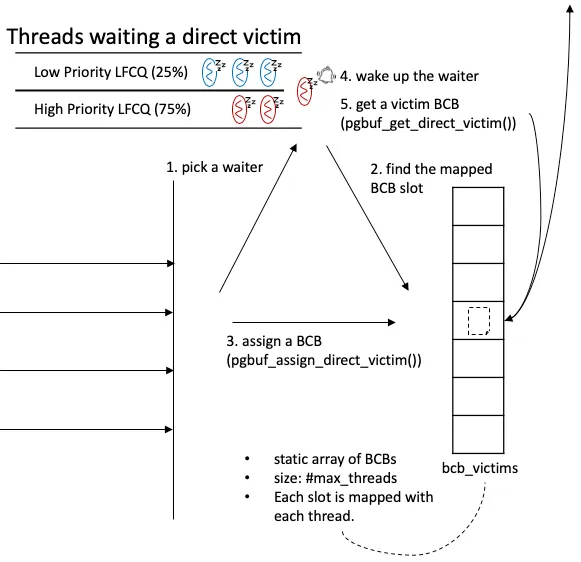
Figure 3 — Two priority LFCQs of waiting threads (High and Low,
75 / 25 weight in selection). When a producer (any of the three
flushing daemons, a normal flush completion, or maintenance work)
finds a now-victimizable BCB, it picks one waiter, finds that
waiter’s slot in the static bcb_victims[] array, writes the BCB
into that slot, and wakes the waiter. The waiter, when scheduled,
reads its own slot and proceeds. If between assign and get the BCB
gets re-fixed, the get path observes
PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG and returns to sleep.
(Source: deck Figure 13.)
The high-priority queue is reserved for vacuum workers and for threads that previously had a direct victim invalidated. The producers are:
- Page Flush Daemon (
class pgbuf_page_flush_daemon_task) — flushes dirty BCBs; if it incidentally encounters a victimizable BCB, it hands off. - Page Post-Flush Daemon (
pgbuf_page_post_flush_execute) — post-processes flushed pages; hands off if the just-flushed BCB is victimizable. Registered as acubthread::entry_callable_taskrather than a dedicated task class. - Page Maintenance Daemon (
pgbuf_page_maintenance_execute) — adjusts quotas and explicitly searches for direct victims. Same callable-task registration pattern.
Zones — five-state classification
Section titled “Zones — five-state classification”Every BCB lives in exactly one of five zones at any moment:
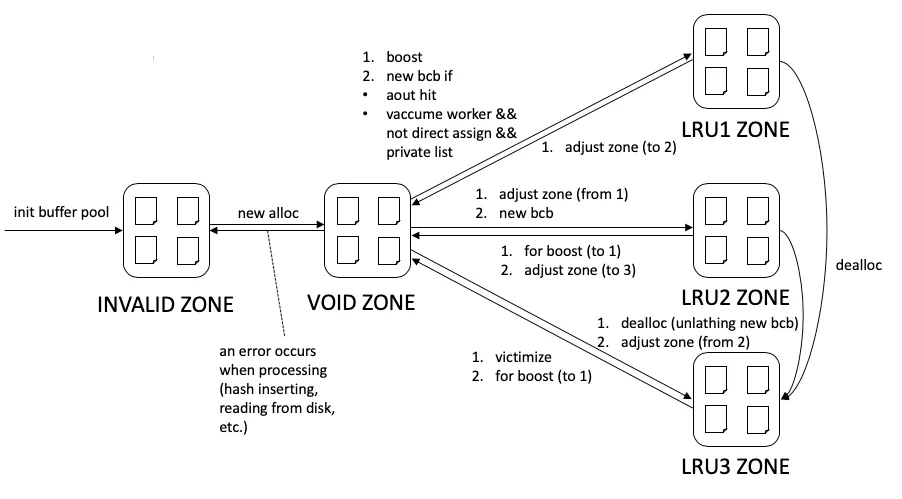
Figure 4 — Zone transitions. INVALID is the initial pool; VOID is the transient state during allocation/movement; LRU 1 / 2 / 3 are the active LRU zones. New BCBs are claimed out of INVALID into VOID; after fix+unfix they land in LRU 2 (or LRU 1 for vacuum workers / aout-hit boost). On error during alloc the BCB falls back to INVALID. Deallocation pushes a BCB straight into LRU 3 (waiting to be flushed and reused), regardless of where it currently is. (Source: deck Figure 10.)
The flags.zone field carries this state. Note that zones map
directly to data structures: INVALID = on the invalid list; VOID =
on no list; LRU 1/2/3 = on a specific LRU list, in the corresponding
zone region.
BCB flags — packed state word
Section titled “BCB flags — packed state word”The flags field packs three pieces of state into one 32-bit word:
+-------------+----------+--------+--------------------+ | BCB_FLAGS | unused | ZONE | LRU_INDEX (16) | | (7) | (5) | (4) | | +-------------+----------+--------+--------------------+The BCB-specific flags occupy the high 7 bits of the word — but
the seven #defined masks are not contiguous: bits 31..25 are
assigned (DIRTY 0x80000000, FLUSHING 0x40000000, VICTIM_DIRECT
0x20000000, INVALIDATE_DIRECT_VICTIM 0x10000000, MOVE_TO_LRU_BOTTOM
0x08000000, TO_VACUUM 0x04000000, ASYNC_FLUSH_REQ 0x02000000) and
bit 0x01000000 is reserved/unused inside the flag region. The list:
PGBUF_BCB_DIRTY_FLAG— modified since last flush. Set on every page-update operation. Cleared at flush start (re-set if flush fails) or at invalidate.PGBUF_BCB_FLUSHING_TO_DISK_FLAG— flush in progress. Producers of direct victims clear it when handing off.PGBUF_BCB_ASYNC_FLUSH_REQ— flush wanted, but the BCB is held with a write latch. The fixer is asked to flush on unfix.PGBUF_BCB_VICTIM_DIRECT_FLAG— handed to a waiting thread.PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG— was handed off but re-fixed in the meantime; the waiter must put it back.PGBUF_BCB_MOVE_TO_LRU_BOTTOM_FLAG— set on dealloc; tells the unfix path to skip the normal LRU promotion logic and drop the BCB into LRU 3 directly.PGBUF_BCB_TO_VACUUM_FLAG— page is queued for vacuum inspection. Producer:pgbuf_notify_vacuum_follows(page_buffer.c:15579) sets the bit on a page about to be visited by vacuum. Consumer:pgbuf_bcb_is_to_vacuum(page_buffer.c:15591) reads it. The bit is also part ofPGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK(line 258), so a BCB flagged for vacuum is excluded from victim search. Cleared viapgbuf_bcb_update_flagsinpgbuf_unfixpaths and in the vacuum-drivenpgbuf_fix_if_not_deallocatedflow (lines 2454, 8395).
BCB latch — custom user-level R/W lock
Section titled “BCB latch — custom user-level R/W lock”Every fix takes a latch on the BCB. The header declares five
PGBUF_LATCH_MODE values — PGBUF_NO_LATCH, PGBUF_LATCH_READ,
PGBUF_LATCH_WRITE, PGBUF_LATCH_FLUSH, and PGBUF_LATCH_INVALID
(sentinel; never observed on a real fix). Only the first four name
real states; FLUSH is condition-variable-shaped — a thread waits on
it for an in-progress flush to complete, rather than holding a real
latch.
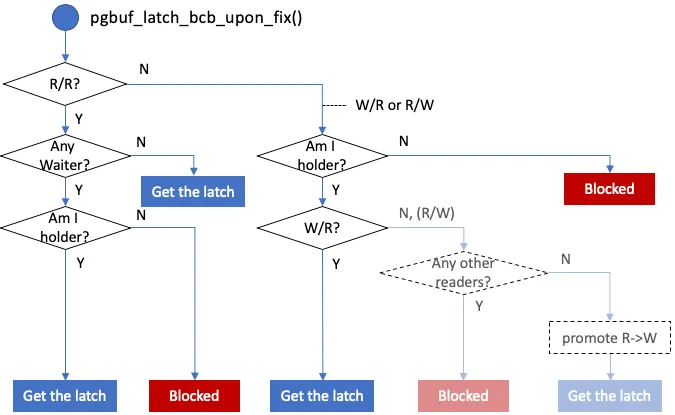
Figure 5 — pgbuf_latch_bcb_upon_fix decision tree. R/R is
compatible by default, but if any thread is already waiting (e.g.,
a write request) the new R yields and blocks to prevent
starvation. W/R and R/W block by default; a thread that already
holds the latch can pass W→R because it already holds the stronger
latch. The R→W upgrade in-place was deprecated (CUBRIDSUS-10294)
and re-added later as a separate pgbuf_promote_read_latch call
(CUBRIDSUS-15376). (Source: deck Figure 15.)
The waiter list lives in BCB.next_wait_thrd. On unlatch,
pgbuf_wakeup_read_writer walks the list:
- The first FLUSH waiter is skipped (handled by
pgbuf_wake_flush_waiters). - The first NO_LATCH waiter (a timed-out one) is cleaned up.
- The first READ waiter triggers waking all consecutive READ waiters — readers can run in parallel.
- The first WRITE waiter wakes only itself — writers run alone.
Holders are tracked per-thread in a PGBUF_HOLDER list so a
thread can ask “do I already hold this BCB?” in O(local).
PGBUF lock — VPID-level allocation lock
Section titled “PGBUF lock — VPID-level allocation lock”When a fix misses the page table and allocates a fresh BCB, two threads racing on the same VPID would both try to allocate. The PGBUF lock is taken on the VPID before allocation, released once the BCB is in the table:
flowchart LR T1["Thread A:\nfix VPID 100"] --> H1["page table miss"] H1 --> L1["pgbuf_lock_page(VPID 100)"] L1 --> A1["allocate BCB,\nread from disk,\ninsert into page table"] A1 --> U1["pgbuf_unlock_page(VPID 100)"] T2["Thread B:\nfix VPID 100\n(starts later)"] --> H2["page table miss"] H2 --> L2["pgbuf_lock_page(VPID 100)\n→ blocks behind A"] L2 -. "wakes after U1" .-> RT["retry → page table hit"] RT --> DONE["normal hash-hit path"]
Figure 10 — PGBUF lock serialising two threads racing to fix the same VPID. Thread B blocks on pgbuf_lock_page until Thread A inserts the BCB, then retakes the normal hash-hit path.
The lock chain hangs off the same hash bucket as the BCB chain. Once the loser-thread wakes, it observes the BCB now in the table and proceeds via the regular hash-hit path.
Ordered fix — multi-page deadlock avoidance
Section titled “Ordered fix — multi-page deadlock avoidance”A heap operation that touches multiple pages (e.g.,
REC_RELOCATION + REC_NEWHOME across two heap pages, or a
REC_BIGONE + overflow page) must take latches on all of them.
Different operations could pick up the same pages in different
orders, deadlocking each other. CUBRID’s answer is ordered
fix: each page has a numerical rank, and pages are always
fixed in ascending rank order.
// PGBUF_ORDERED_RANK — src/storage/page_buffer.htypedef enum{ PGBUF_ORDERED_HEAP_HDR = 0, /* heap header pages first */ PGBUF_ORDERED_HEAP_NORMAL, /* then regular heap pages */ PGBUF_ORDERED_HEAP_OVERFLOW, /* then overflow pages */ PGBUF_ORDERED_RANK_UNDEFINED,} PGBUF_ORDERED_RANK;
// PGBUF_WATCHER — page latch handle that supports ordered fixstruct pgbuf_watcher{ PAGE_PTR pgptr; PGBUF_WATCHER *next; PGBUF_WATCHER *prev; PGBUF_ORDERED_GROUP group_id; /* VPID of group (HEAP header) */ unsigned latch_mode:7; unsigned page_was_unfixed:1; /* refix happened? */ unsigned initial_rank:4; unsigned curr_rank:4; /* (debug fields elided) */};pgbuf_ordered_fix checks whether the requested rank is greater
than the rank of any currently-held watcher; if not, it unfixes
out-of-order pages, sorts the resulting set, and re-fixes in rank
order. page_was_unfixed = true lets the caller detect that the
page state may have changed during the unfix.
Background daemons
Section titled “Background daemons”In server mode, three daemon threads run alongside foreground workers:
| Daemon | Period | Job |
|---|---|---|
| Page Flush Daemon | adaptive | Flush dirty pages; hand off if victimizable |
| Page Post-Flush Daemon | event-driven | Post-process flushed pages; hand off if victimizable |
| Page Maintenance Daemon | 100 ms | Adjust private-LRU quotas; search for direct victims |
The flush daemon’s flush rate adapts via
pgbuf_flush_control_from_dirty_ratio — higher dirty ratio →
faster flush. Two boolean knobs gate its activity:
pgbuf_keep_victim_flush_thread_running and
pgbuf_assign_flushed_pages.
Double Write Buffer (DWB) — torn-page protection
Section titled “Double Write Buffer (DWB) — torn-page protection”A torn write occurs when a database page is larger than the OS disk-block size (e.g., DB 16 K vs OS 4 K) and a crash happens mid-write. The DB page on disk would be a half-old-half-new Frankenstein; recovery cannot reconstruct it from the WAL because the WAL records assume a coherent old state.
The DWB writes each page first to a sequential, fixed-location double-write buffer on disk, then writes it to the actual page location. On crash recovery:
- For each DB page whose checksum is corrupt, look up the DWB.
- If a clean copy of that VPID exists in the DWB, restore from it.
- Replay WAL on top of the restored page.
CUBRID’s DWB lives in src/storage/double_write_buffer.{hpp,cpp}
(≈ 4 200 LOC). The page buffer’s flush path consults the DWB
before reading from disk during fix:
// fix path on page-table miss → claim BCB// if (fetch_mode != NEW_PAGE)// // first try DWB// if (DWB has VPID)// read from DWB into the BCB's iopage_buffer// else// read from storageThis means a DWB hit eliminates one disk read on a cache miss.
Source Walkthrough
Section titled “Source Walkthrough”Anchor on symbol names, not line numbers. The CUBRID source moves; a function name (or struct/enum tag) is the stable handle. Use
git grep -n '<symbol>' src/storage/to locate the current position.
Type definitions (src/storage/page_buffer.{h,c})
Section titled “Type definitions (src/storage/page_buffer.{h,c})”struct pgbuf_bcb(inpage_buffer.c) — buffer control block.struct pgbuf_iopage_buffer(inpage_buffer.c) — page-byte carrier; embeds aFILEIO_PAGE.struct pgbuf_buffer_hash(inpage_buffer.c) — page-table bucket: BCB chain + PGBUF lock chain + bucket mutex.struct pgbuf_buffer_lock(inpage_buffer.c) — VPID-level lock used during BCB allocation.struct pgbuf_holder(inpage_buffer.c) — per-thread record of a held latch.struct pgbuf_lru_list(inpage_buffer.c) — one LRU list.struct pgbuf_pool(pgbuf_Pool, inpage_buffer.c) — global buffer manager state.enum PAGE_FETCH_MODE(inpage_buffer.h) — 7 modes (OLD_PAGE / NEW_PAGE / OLD_PAGE_IF_IN_BUFFER / OLD_PAGE_PREVENT_DEALLOC / OLD_PAGE_DEALLOCATED / OLD_PAGE_MAYBE_DEALLOCATED / RECOVERY_PAGE).enum PGBUF_LATCH_MODE(inpage_buffer.h) — 5 modes.enum PGBUF_LATCH_CONDITION(inpage_buffer.h) — UNCONDITIONAL / CONDITIONAL.enum PGBUF_PROMOTE_CONDITION(inpage_buffer.h) — ONLY_READER / SHARED_READER (R→W promotion).enum PGBUF_ORDERED_RANK(inpage_buffer.h) — 4 ranks for ordered fix.struct pgbuf_watcher(inpage_buffer.h) — handle for ordered fix.
Lifecycle (src/storage/page_buffer.c)
Section titled “Lifecycle (src/storage/page_buffer.c)”pgbuf_initialize— module init.pgbuf_finalize— module teardown.pgbuf_daemons_init/pgbuf_daemons_destroy— spin up / tear down the three flush daemons.pgbuf_thread_variables_init— per-worker init (private LRU index assignment).
Fix / unfix (src/storage/page_buffer.c)
Section titled “Fix / unfix (src/storage/page_buffer.c)”pgbuf_fix(debug + release variants) — public entry.pgbuf_fix_with_retry— retry wrapper on transient failure.pgbuf_simple_fix/pgbuf_simple_unfix— minimal path for temporary files.pgbuf_ordered_fix/pgbuf_ordered_unfix— multi-page deadlock-free fix withPGBUF_WATCHER.pgbuf_promote_read_latch— R → W upgrade.pgbuf_unfix/pgbuf_unfix_all.pgbuf_fix_if_not_deallocated— deallocation-aware variant.
BCB allocation (src/storage/page_buffer.c)
Section titled “BCB allocation (src/storage/page_buffer.c)”pgbuf_claim_bcb_for_fix— outer allocate-and-bind loop.pgbuf_allocate_bcb— allocate (invalid → victim → direct-victim sleep).pgbuf_get_bcb_from_invalid_list.pgbuf_get_victim— LFCQ scan.pgbuf_assign_direct_victim/pgbuf_get_direct_victim.
LRU + zones (src/storage/page_buffer.c)
Section titled “LRU + zones (src/storage/page_buffer.c)”pgbuf_lru_add_bcb_to_top/_to_middle/_to_bottom.pgbuf_move_bcb_to_bottom_lru.pgbuf_lru_boost_bcb— promote to LRU 1.pgbuf_lru_adjust_zones— rebalance after threshold change.pgbuf_should_move_private_to_shared.pgbuf_adjust_quotas— Page Maintenance Daemon’s per-100ms job.PGBUF_IS_BCB_OLD_ENOUGH— boost gate.
Page table + PGBUF lock (src/storage/page_buffer.c)
Section titled “Page table + PGBUF lock (src/storage/page_buffer.c)”pgbuf_hash_func_mix— VPID hash.pgbuf_hash_chain_lookup— bucket walk.pgbuf_lock_page/pgbuf_unlock_page— VPID-level alloc lock.
BCB latch (src/storage/page_buffer.c)
Section titled “BCB latch (src/storage/page_buffer.c)”pgbuf_latch_bcb_upon_fix— compatibility decision.pgbuf_block_bcb— register as waiter and sleep.pgbuf_wakeup_read_writer— wake waiters on unlatch.pgbuf_wake_flush_waiters— wake FLUSH waiters on flush done.pgbuf_promote_read_latch_release/_debug— R → W promotion.
Flush + DWB (src/storage/page_buffer.c,
Section titled “Flush + DWB (src/storage/page_buffer.c,”src/storage/double_write_buffer.cpp)
pgbuf_flush/pgbuf_flush_with_wal— single-BCB flush.pgbuf_flush_victim_candidates— Page Flush Daemon body.pgbuf_flush_checkpoint— checkpoint flush.pgbuf_flush_all/_unfixed/_unfixed_and_set_lsa_as_null.pgbuf_bcb_flush_with_wal— flag manipulation around flush.dwb_*— double write buffer entry / lookup / recovery.
Daemons (src/storage/page_buffer.c, server mode only)
Section titled “Daemons (src/storage/page_buffer.c, server mode only)”class pgbuf_page_flush_daemon_task— Page Flush Daemon body (only daemon implemented as a dedicated task class).pgbuf_page_post_flush_execute— Page Post-Flush Daemon’s callable; registered viacubthread::entry_callable_task.pgbuf_page_maintenance_execute— Page Maintenance Daemon’s callable; registered the same way.pgbuf_page_flush_daemon_init/pgbuf_page_post_flush_daemon_init/pgbuf_page_maintenance_daemon_init— daemon spin-up.pgbuf_keep_victim_flush_thread_running.pgbuf_assign_flushed_pages.pgbuf_direct_victims_maintenance.
Position hints as of this revision
Section titled “Position hints as of this revision”| Symbol | File | Line |
|---|---|---|
enum PAGE_FETCH_MODE | page_buffer.h | 172 |
enum PGBUF_LATCH_MODE | page_buffer.h | 190 |
enum PGBUF_ORDERED_RANK | page_buffer.h | 222 |
struct pgbuf_watcher | page_buffer.h | 234 |
PGBUF_FIX_COUNT_THRESHOLD | page_buffer.c | 106 |
PGBUF_BCB_DIRTY_FLAG | page_buffer.c | 224 |
PGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK | page_buffer.c | 258 |
PGBUF_HASH_SIZE | page_buffer.c | 296 |
pgbuf_initialize | page_buffer.c | 1518 |
pgbuf_fix_release | page_buffer.c | 2041 |
pgbuf_latch_bcb_upon_fix | page_buffer.c | 6073 |
pgbuf_lock_page | page_buffer.c | 7718 |
pgbuf_claim_bcb_for_fix | page_buffer.c | 8133 |
pgbuf_get_victim | page_buffer.c | 8805 |
pgbuf_adjust_quotas | page_buffer.c | 13639 |
pgbuf_assign_direct_victim | page_buffer.c | 14809 |
pgbuf_page_maintenance_execute | page_buffer.c | 16375 |
class pgbuf_page_flush_daemon_task | page_buffer.c | 16396 |
pgbuf_page_post_flush_execute | page_buffer.c | 16450 |
page_buffer.c is ≈ 17 000 lines; symbol-level git grep is the
recommended lookup mode.
Source verification (as of 2026-04-29)
Section titled “Source verification (as of 2026-04-29)”Each entry is a fact about the current source — readable without the original analysis materials. The trailing note shows how it was checked and, where relevant, historical drift or limits of verification. Open questions follow as the curator’s recorded gaps; future readers should treat them as starting points, not as known bugs.
Verified facts
Section titled “Verified facts”-
The page-table hash has 2²⁰ = 1 048 576 buckets, fixed at server start. Verified in
pgbuf_initialize/pgbuf_initialize_buffer_hash_tableon 2026-04-29. Each bucket carries its ownhash_mutex, BCB chain, and PGBUF-lock chain. Hard-coded — not a runtime parameter. -
There is one PGBUF lock chain per hash bucket, not per VPID. Verified by reading
pgbuf_lock_page/pgbuf_unlock_pageon 2026-04-29. The lock object lives in the bucket structure and protects the BCB allocation race on a per-bucket basis. -
LRU has exactly three zones (top / middle / bottom = LRU 1 / 2 / 3) with default 5 % thresholds. Verified in
page_buffer.czone constants on 2026-04-29. Only LRU 3 BCBs are evictable; LRU 1 / 2 are protected. -
The four exclusion conditions for victim candidacy. A BCB is not a candidate if it is being flushed (
PGBUF_BCB_FLUSHING_TO_DISK_FLAG), dirty (PGBUF_BCB_DIRTY_FLAG), already a direct victim (PGBUF_BCB_VICTIM_DIRECT_FLAG), or invalidated as a direct victim (PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG). Combined asPGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK. Verified on 2026-04-29. -
Direct-victim selection uses two priority queues with 75 / 25 weight. A BCB producer picks from the High-priority LFCQ with 3× the probability of the Low-priority LFCQ. Verified by reading
pgbuf_assign_direct_victimon 2026-04-29. High priority is reserved for vacuum workers and previously-invalidated retries. -
Three background daemons in server mode. Page Flush, Page Post-Flush, Page Maintenance — declared in
pgbuf_daemons_init. Verified on 2026-04-29. -
Quota adjustment cadence is 100 ms. Page Maintenance Daemon’s
pgbuf_adjust_quotasruns every 100 ms. Verified by reading the daemon task on 2026-04-29. Quotas are smoothed against history (interpolation); raw activity per interval is not used directly. -
old enoughfor boost = at least half of LRU 2 has been pushed past the BCB. Implemented inPGBUF_IS_BCB_OLD_ENOUGHmacro. Verified on 2026-04-29. Prevents short-lived BCBs from immediately boosting to LRU 1 on a single fix-unfix. -
Private-to-shared migration triggers. Either (a) the BCB is hot (fix count ≥ 64) AND old enough, OR (b) the BCB was unfixed by a thread other than the one that fixed it. Verified in
pgbuf_should_move_private_to_sharedon 2026-04-29. -
R → W in-place upgrade was deprecated and re-added separately. The original behavior of automatically upgrading a held read latch to write in
pgbuf_latch_bcb_upon_fixwas removed by CUBRIDSUS-10294. The functionality re-appeared as an explicitpgbuf_promote_read_latchcall (CUBRIDSUS-15376). The decision tree now asserts that the in-place upgrade path is unreachable. Verified by reading the BCB latch decision logic on 2026-04-29. -
DWB is consulted before disk reads on page-table miss. Verified in the BCB-claim path (
pgbuf_claim_bcb_for_fix→pgbuf_read_page→ DWB lookup) on 2026-04-29. A DWB hit saves a disk read; a DWB miss falls through to the volume read.
Open questions
Section titled “Open questions”-
What isResolved 2026-05-01. Producer isPGBUF_BCB_TO_VACUUM_FLAG?pgbuf_notify_vacuum_follows(page_buffer.c:15579); consumer ispgbuf_bcb_is_to_vacuum(page_buffer.c:15591). The flag participates inPGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK(line 258), so a BCB queued for vacuum cannot be picked as a victim. Cleared on unfix paths viapgbuf_bcb_update_flags(lines 2454, 8395). Open follow-up: full enumeration of who callspgbuf_notify_vacuum_follows(heap / vacuum subsystem) — out of scope for the page-buffer doc. -
Why is the page-table size hard-coded at 2²⁰? The hash size is fixed regardless of
pb_buffer_capacityparameter. Workloads with very large buffer pools could see chain lengths grow. Investigation: instrument bucket-chain length under a memory-large workload; check whether it should scale with buffer-pool capacity. -
OLD_PAGE_PREVENT_DEALLOC/OLD_PAGE_DEALLOCATED/OLD_PAGE_MAYBE_DEALLOCATEDare documented as TBU. The header lists them as PAGE_FETCH_MODE values but the deck does not describe their semantics. Investigation: read the call sites of each variant to derive the semantics from usage. -
Why does
PGBUF_BCB_FLUSHING_TO_DISK_FLAGget cleared at direct-victim assign? The deck explicitly notes “왜 끄는지는 모르겠음. 플러시를 중지시키는 것도 아니고” — clearing at assign does not actually cancel the flush. Investigation: trace what the flag’s clear-on-assign actually affects (probably some consumer’s view of “is this BCB still a flush target?”). -
Direct-victim slot starvation. If a thread is invalidated repeatedly (assign → re-fix → invalidate), it stays in the high-priority queue. Could a pathological workload starve other high-priority waiters? Investigation: instrument re-queue counts under high contention.
-
How does the flush daemon’s adaptive rate (
pgbuf_flush_control_from_dirty_ratio) actually behave under bursty workloads? The deck mentions the dirty-ratio knob but does not describe the smoothing. Investigation: read the body of the function and trace the inputs. -
Interaction with TDE (Transparent Data Encryption). The header declares
pgbuf_set_tde_algorithmand the BCB stores per-page TDE state, but the deck does not cover encryption. Investigation: trace the encrypt / decrypt boundary in the flush and read paths.
Beyond CUBRID — Comparative Designs & Research Frontiers
Section titled “Beyond CUBRID — Comparative Designs & Research Frontiers”Pointers, not analysis. Each bullet is a starting handle for a follow-up doc; depth here is intentionally shallow.
- PostgreSQL clock-sweep + buffer partitions. PostgreSQL uses
a clock algorithm (not LRU) over an array of
BufferDescs, withBufFreelistLockandBufMappingLockpartitioned by hash. No per-worker LRUs. Comparison would clarify whether CUBRID’s private-LRU complexity is justified by its target workload, or whether it is excess sophistication for shared-cache patterns. - MySQL InnoDB midpoint LRU + adaptive flushing. InnoDB’s LRU
has a midpoint at 3/8 from the head; new pages enter at the
midpoint, not the head, to resist scan flooding. Adaptive
flushing pages out based on
innodb_io_capacityand redo-log lag. Maps to CUBRID’s three-zone LRU + dirty-ratio flush control. A side-by-side write-up would help. - Oracle multi-pool buffer caches. Oracle exposes KEEP, RECYCLE, and DEFAULT pools so DBAs can pin hot tables in KEEP and route scans through RECYCLE. CUBRID has no such partitioning; private LRUs play a related but worker-driven role. Worth comparing the trade-offs (DBA control vs adaptive).
- HyPer / Hekaton — no buffer pool at all. In-memory engines skip the buffer manager entirely. The relevant comparison is the cost we pay to be disk-resident, measured against engines that pay none.
- WriteUnboundedWriteAheadLog (WBL) and SSDs. Recent research on persistent memory and SSD-aware page management questions the 16K page assumption; CUBRID’s DWB (in particular) is a torn-page defense built for HDDs and its cost/benefit on modern NVMe is worth re-evaluating.
- Lock-free buffer managers. Sadoghi et al. LeanStore
(ICDE 2018), Hekaton (VLDB 2013) skip OS mutexes entirely on
the hot path. CUBRID’s BCB latch is custom but still uses
per-BCB
pthread_mutex_tfor state changes. A comparison would clarify the achievable latency floor. - Recent paper trail. Mohan et al., ARIES (TODS 92) — the WAL/buffer protocol; Stoica & Ailamaki, Enabling Efficient OS Paging for Main-Memory OLTP Databases (DaMoN 13) — buffer/OS interactions; the OOS feature design doc on this knowledge base for the latest CUBRID buffer-related changes.
The intent of this section is to seed next documents, not to analyze. Each bullet should become its own curated note when its turn comes.
Sources
Section titled “Sources”Raw analyses (under raw/code-analysis/cubrid/storage/buffer_manager/)
Section titled “Raw analyses (under raw/code-analysis/cubrid/storage/buffer_manager/)”CodeAnal_BM.docx— primary text, 9 sections covering BCB, fix/unfix, page table, invalid list, LRU lists with private/ shared and LFCQ, zones, direct victim, BCB flags, and BCB latch- PGBUF lock. The 18 figures embedded in this DOCX are the source of all six images embedded in the present document.
CodeAnal_BM_pt_1.pdf— PDF render of the same content.DesignDoc-PageBuffer_page_quota.pdf— design notes on the private-LRU quota system (pgbuf_adjust_quotasrationale).
Notion (CUBRID DEV WIKI)
Section titled “Notion (CUBRID DEV WIKI)”- Storage – Concurrency 코드 분석 — module-level positioning that places Page Buffer underneath everything else (heap, index, catalog all flow through the page buffer for I/O).
Textbook chapters (under knowledge/research/dbms-general/)
Section titled “Textbook chapters (under knowledge/research/dbms-general/)”- Database System Concepts (Silberschatz, Korth, Sudarshan, 6th ed.), Ch. 13 “Storage and File Structure” — buffer manager, page replacement.
- Database Internals (Petrov), Ch. 4 “Implementing B-Trees” and Ch. 5 “Transaction Processing and Recovery” — buffer/log interaction.
- Mohan et al., ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging (TODS 1992) — WAL ordering invariant for the buffer manager.
CUBRID source (under /data/hgryoo/references/cubrid/)
Section titled “CUBRID source (under /data/hgryoo/references/cubrid/)”src/storage/page_buffer.hsrc/storage/page_buffer.csrc/storage/double_write_buffer.hppsrc/storage/double_write_buffer.cpp