CUBRID B+Tree — Layout, Latch-Coupling, and Unique-Key Suffixing
Contents:
- Theoretical Background
- Common DBMS Design
- CUBRID’s Approach
- Source Walkthrough
- Source verification (as of 2026-04-30)
- Beyond CUBRID — Comparative Designs & Research Frontiers
- Sources
Theoretical Background
Section titled “Theoretical Background”The B+Tree is the workhorse index of every disk-resident relational database. Database Internals (Petrov, ch. 2 §“B-Tree Basics” and ch. 3 §“File Formats”) frames it as the right answer to four simultaneous goals:
- Logarithmic search. Tree fan-out keeps depth at ~3-5 even for billion-row tables.
- Sequential scan. Sibling-linked leaves give O(1) next-key per step.
- Cache-locality on both reads and writes. Each node is one page, so a node fix is a buffer-pool fix.
- Concurrent access via short-duration latches rather than long-duration locks.
The original Bayer–McCreight (1972) tree didn’t have all four; it was extended by:
- Lehman & Yao (1981) — the B-link tree that adds a right-link to every node, so a descend that loses the lock before reaching a leaf can recover by following right-links rather than re-acquiring ancestor latches.
- Mohan (1990) — ARIES/IM, the index recovery algorithm that adds CLR-aware undo and logical undo for splits, so a partial split is restartable without holding latches across the log force.
CUBRID’s B+Tree implements neither in pure form but borrows heavily from both. Two implementation choices the model leaves open shape every real engine and frame the rest of this document:
- What is the key? Pure key, or
key || OID(key concatenated with the row’s OID)? In a non-unique index, the choice is forced — duplicate keys exist, and the OID is the tie-breaker. In a unique index, the choice is between storing pure keys (with the OID payload separate) andkey || OIDfor uniformity. CUBRID uses both: leaf non-unique entries arekey || OID, and unique-index leaf entries are purekeywith the OID stored next to the key in a known offset (with overflow into a per-key OID list when the count is large). - How to descend safely. Lock-coupling (parent-then-child, release parent), Blink-tree right-link recovery, or full path-locking? CUBRID uses lock-coupling on the read path and adds a “restart from root” recovery path on the write path when a split has invalidated the descent.
After the choices are named, every CUBRID-specific structure in this document either implements one of them or makes the implementation faster.
Common DBMS Design
Section titled “Common DBMS Design”Every disk-resident B+Tree implementation reaches for the same handful of patterns.
Slotted-page nodes
Section titled “Slotted-page nodes”Each node is one buffer-pool page. Keys are stored in slots, with a slot directory at the page tail growing backward and the records growing forward. The free space in the middle absorbs inserts. CUBRID inherits this from heap pages (cubrid-heap-manager.md §“Slotted page”).
Non-leaf vs. leaf record split
Section titled “Non-leaf vs. leaf record split”Non-leaf records are (separator-key, child-page-pointer) —
small. Leaf records are (key, OID) plus possibly a list of OIDs
for non-unique keys — variable size and possibly large. Engines
that mix the two on the same page (e.g., older designs) have
worse cache behaviour; engines that split them (CUBRID,
PostgreSQL, InnoDB) have a clean record format per node type.
Latch-coupling on descent
Section titled “Latch-coupling on descent”Acquire latch on parent, fix child, release parent. With shared-mode latches on the read path and exclusive on the write path. Modern engines often add an “intent-exclusive” mode that allows the descent to advance speculatively, escalating to exclusive only when a split is certain.
OID-list suffix in non-unique leaves
Section titled “OID-list suffix in non-unique leaves”A non-unique key has zero or more OIDs associated with it. The leaf record’s payload is the key followed by the first few OIDs inline; once the OID count exceeds a threshold, the rest spill to an overflow page chain. The overflow chain is per-key, so unrelated keys don’t share overflow pages.
Unique enforcement at insert time
Section titled “Unique enforcement at insert time”A unique index rejects duplicate keys at insert. The check has to run under the leaf’s exclusive latch — otherwise two concurrent inserters could both observe “no duplicate” and both proceed. The standard pattern: descend with X latch on the leaf, search for the key, return error or attempt-with-MVCC-visibility check.
Logical undo for splits
Section titled “Logical undo for splits”A B+Tree split touches multiple pages atomically. Physical undo
of a split would have to reverse every page change in reverse
order; that’s complicated and brittle. The standard fix: log
the split as a logical operation (“re-merge these pages”) rather
than a sequence of physical changes. CUBRID uses
LOG_SYSOP_END_LOGICAL_UNDO records (cubrid-log-manager.md
§“Sysop end record”) for split rollback.
Theory ↔ CUBRID mapping
Section titled “Theory ↔ CUBRID mapping”| Theoretical concept | CUBRID name |
|---|---|
| Slotted-page node | Reuses slotted_page from heap; BTREE_NODE_TYPE distinguishes role |
| Node type enum | BTREE_NODE_TYPE { LEAF, NON_LEAF, OVERFLOW } (btree.h:81) |
| Non-leaf record | NON_LEAF_REC { VPID pnt; short key_len } (btree.h:103) |
| Leaf record | LEAF_REC { VPID ovfl; short key_len } (btree.h:111) |
| Internal B+Tree id wrapper | BTID_INT { sys_btid, unique_pk, key_type, ovfid, … } (btree.h:119) |
| Range-scan cursor | BTREE_SCAN (BTS) (btree.h:198) |
| Insert helper struct | btree_insert_helper (btree.c:718) |
| Delete helper struct | btree_delete_helper (btree.c:804) |
| Unique constraint check helper | BTREE_NEED_UNIQUE_CHECK macro (btree.h:63) |
| Single vs. multi-row op | SINGLE_ROW_INSERT / MULTI_ROW_INSERT constants (btree.h:52) |
| Split — node | btree_split_node (btree.c:13324) |
| Split — root | btree_split_root (btree.c:14184) |
| Split-point selection | btree_find_split_point (btree.c:12419) |
| Merge — root | btree_merge_root (btree.c:10284) |
| Merge — node | btree_merge_node (btree.c:10557) |
| Bulk load | xbtree_load_index (btree_load.c:856) |
| Per-tree unique stats | btree_unique_stats class (btree_unique.hpp) |
| Overflow page chain for OID list | btree_find_free_overflow_oids_page / btree_find_oid_from_ovfl |
| Latch-coupling read descent | btree_search_nonleaf_page → btree_search_leaf_page |
| Logical undo for split / merge | LOG_SYSOP_END_LOGICAL_UNDO arms in LOG_REC_SYSOP_END |
CUBRID’s Approach
Section titled “CUBRID’s Approach”The B+Tree module has four moving parts: the node layout (records on slotted pages by node type), the descent path (latch-coupling read + restart-on-split write), the modification path (insert, delete, split, merge as system ops), and the unique-constraint machinery (OID-suffix discipline + the unique stats table). We walk them in that order.
Overall structure
Section titled “Overall structure”flowchart TB
subgraph TREE["B+Tree"]
R["root\n(non-leaf)"]
N1["non-leaf"]
N2["non-leaf"]
L1["leaf"]
L2["leaf"]
L3["leaf"]
OVF["overflow OID page"]
R --> N1 --> L1
R --> N1 --> L2
R --> N2 --> L3
L2 --> OVF
end
subgraph DESCEND["Descent (read)"]
D1["btree_search_nonleaf_page\nlatch S, find child slot"]
D2["btree_search_leaf_page\nlatch S, find slot, optionally walk overflow"]
D1 --> D2
end
subgraph MODIFY["Modification (write)"]
M1["btree_insert_helper / btree_delete_helper"]
M2["btree_find_split_point"]
M3["btree_split_node / btree_split_root"]
M4["btree_merge_node / btree_merge_root"]
M1 --> M2 --> M3
M1 --> M4
end
subgraph UNIQUE["Unique-key path"]
U1["btree_find_oid_and_its_page"]
U2["btree_unique_stats"]
U3["MVCC visibility check on candidate dup"]
end
TREE -.descend.-> DESCEND
DESCEND -.found.-> MODIFY
MODIFY -.unique check.-> UNIQUE
Figure 1 — B+Tree module overview. The TREE subgraph shows root, non-leaf, leaf, and overflow OID pages; DESCEND shows the latch-coupled read path via btree_search_nonleaf_page and btree_search_leaf_page; MODIFY shows split/merge helpers; UNIQUE shows the duplicate-key visibility check.
The figure encodes three boundaries. (node-type / role) non-leaf nodes carry separators and child pointers; leaf nodes carry keys and OIDs; overflow pages carry only OIDs. (descent / modify) descent is fix-and-search per node; modify is splice-and-rebalance under exclusive latches. (physical / logical) splits and merges are physical operations on multiple pages but are logged as logical undo so recovery doesn’t have to re-apply page movement in reverse.
Node layout — three record kinds, one slotted page
Section titled “Node layout — three record kinds, one slotted page”Every B+Tree node is a slotted page (cubrid-heap-manager.md
§“Slotted page”). The node’s role is captured in the
BTREE_NODE_HEADER (in the page header area) and the records
in slots conform to one of three formats.
// Node-type marker — src/storage/btree.htypedef enum{ BTREE_LEAF_NODE = 0, BTREE_NON_LEAF_NODE, BTREE_OVERFLOW_NODE} BTREE_NODE_TYPE;The fixed parts of non-leaf and leaf records:
// Fixed parts of B+Tree records — src/storage/btree.hstruct non_leaf_rec{ VPID pnt; /* The child page pointer (volume-id, page-id) */ short key_len; /* Length of the key that follows */};
struct leaf_rec{ VPID ovfl; /* Overflow page pointer for OID list, or NULL */ short key_len; /* Length of the key that follows */};A non-leaf record on disk is then [NON_LEAF_REC fixed][key bytes];
a leaf record is [LEAF_REC fixed][key bytes][OID list]. The
OID list is inline up to a per-page threshold; beyond that, ovfl
points to an overflow page chain.
The B+Tree id wrapper adds metadata the tree needs at runtime:
// BTID_INT — src/storage/btree.h:119struct btid_int{ BTID *sys_btid; /* The on-disk btree id */ int unique_pk; /* bitmask: BTREE_CONSTRAINT_UNIQUE, BTREE_CONSTRAINT_PRIMARY_KEY */ int part_key_desc; /* descending sort indicator */ TP_DOMAIN *key_type; /* domain of the key */ TP_DOMAIN *nonleaf_key_type; /* may differ from key_type for prefix keys on fixed-char domains */ VFID ovfid; /* file id of overflow OID pages */ char *copy_buf; /* per-scan key copy buffer */ int copy_buf_len; int rev_level; /* revision (for upgrade compatibility) */ int deduplicate_key_idx; /* SUPPORT_DEDUPLICATE_KEY_MODE */ OID topclass_oid; /* class OID this index serves */};unique_pk is read on every insert via the
BTREE_NEED_UNIQUE_CHECK macro:
// Decide whether to enforce unique constraint — src/storage/btree.h#define BTREE_NEED_UNIQUE_CHECK(thread_p, op) \ (logtb_is_current_active (thread_p) \ && (op == SINGLE_ROW_INSERT \ || op == MULTI_ROW_INSERT \ || op == SINGLE_ROW_UPDATE))Logged inserts during recovery skip the check (recovery never inserts duplicates because the original insert was already committed-or-aborted); active-transaction inserts and updates do enforce it.
The scan cursor — BTREE_SCAN
Section titled “The scan cursor — BTREE_SCAN”A range scan in CUBRID is driven by a BTREE_SCAN (BTS)
structure, holding the descent state plus enough bookkeeping
to resume after a page split or a buffer-pool eviction.
// BTREE_SCAN — src/storage/btree.h:198 (condensed)struct btree_scan{ BTID_INT btid_int;
VPID P_vpid; /* previous leaf page (for backward step) */ VPID C_vpid; /* current leaf page */ VPID O_vpid; /* current overflow page (or NULL_VPID) */ PAGE_PTR P_page; PAGE_PTR C_page; INT16 slot_id; /* current slot inside C_page */
DB_VALUE cur_key; bool clear_cur_key;
int common_prefix_size; /* prefix-compression aware reads */ DB_VALUE common_prefix_key; bool clear_common_prefix_key; bool is_cur_key_compressed;
BTREE_KEYRANGE key_range; /* lower / upper / range type */ FILTER_INFO *key_filter;
bool use_desc_index; /* descending scan */ LOG_LSA cur_leaf_lsa; /* page LSA last seen at C_page */ LOCK lock_mode; /* S_LOCK or X_LOCK */
RECDES key_record; LEAF_REC leaf_rec_info; BTREE_NODE_TYPE node_type; int offset; BTS_KEY_STATUS key_status; /* NOT_VERIFIED, VERIFIED, CONSUMED */
bool end_scan, end_one_iteration, is_interrupted, is_key_partially_processed; int n_oids_read, n_oids_read_last_iteration;
OID *oid_ptr; OID match_class_oid; /* for partitioned indexes */ DB_BIGINT *key_limit_lower, *key_limit_upper;
struct indx_scan_id *index_scan_idp; bool is_btid_int_valid, is_scan_started, force_restart_from_root; bool is_fk_remake; PERF_UTIME_TRACKER time_track; void *bts_other;};The cur_leaf_lsa is load-bearing for page-LSA-aware scan
restart. When the scan returns to a leaf it had previously
visited, it compares pgbuf_get_lsa (C_page) against
bts->cur_leaf_lsa. If they match, the page hasn’t changed since
the last visit — slot positions are still valid. If they differ,
the scan must re-locate the key by binary search before
continuing. This is how CUBRID avoids holding latches across
client roundtrips on long range scans.
Descent — latch-coupling on read, restart-on-split on write
Section titled “Descent — latch-coupling on read, restart-on-split on write”The read descent is handled by btree_search_nonleaf_page
(btree.c:5189) and btree_search_leaf_page (btree.c:5537).
Both take a node, search for the target key, return the slot
and a found flag.
Latch-coupling rule (the textbook one):
- Fix root with S latch.
- For each internal level: search slot, fix child with S latch, release parent.
- At leaf: search slot, return.
Write descent is similar but escalates the latch on the leaf
to X. If the leaf is full and the write requires a split, the
descent restarts from the root with X latches all the way down
(“force_restart_from_root” in BTS), and btree_split_node /
btree_split_root are invoked under exclusive latches that
cover the entire affected subtree.
Insert and delete helpers
Section titled “Insert and delete helpers”btree_insert_helper (btree.c:718) and btree_delete_helper
(btree.c:804) are constructor functions for stack-allocated
helper structs that carry the per-operation context (purpose
flags, mvcc info, key, OID, error, log lsa, etc.). They abstract
the giant parameter lists the call sites would otherwise
require, and unify the flag plumbing for MVCC vs. non-MVCC,
single-row vs. multi-row, and unique vs. non-unique paths.
The insert top-level path:
btree_insert_helper hi (...);btree_search_for_insert (&hi); // descend, locate target leafif (BTREE_NEED_UNIQUE_CHECK (op)) btree_find_oid_and_its_page (...); // is the key already there?if (leaf_full) { log_sysop_start (); btree_split_node (...); // split, possibly cascade up log_sysop_end_logical_undo (LOG_RV_BTREE_SPLIT_*); }btree_insert_into_leaf (&hi);log_append_undoredo_data (RVBT_..., ...);The system-op bracket around split is what makes split rollback
work. If the transaction aborts after the split but before the
matching insert is logged, the undo pass replays the
LOG_SYSOP_END_LOGICAL_UNDO of the split — which in turn calls
btree_merge_node — re-merging the two halves back. Without the
logical-undo bracket, undo would have to re-apply the page
movement in reverse, including page allocations from the file
manager.
Splits — split point, key promotion, parent update
Section titled “Splits — split point, key promotion, parent update”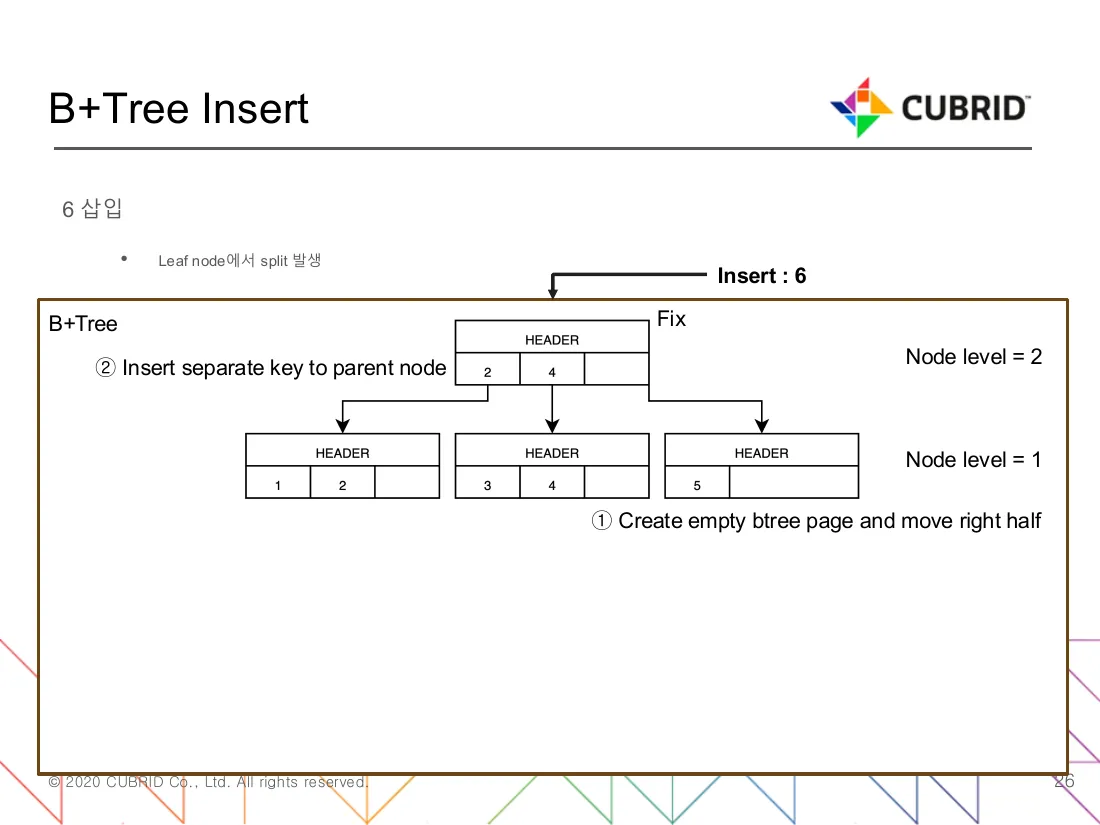
Figure 2 — Inserting key 6 into a leaf already holding {3, 4, 5}
in a tree where each node fits 3 records. ① A new empty btree page is
allocated and the right half ({5} plus the new 6) moves into it,
leaving the original page with {3, 4}. ② The separator key (here 4)
is inserted into the parent so subsequent searches steer to the
correct half. The parent already had room — no cascade. The
Node level = 1/2 annotations show that splits propagate up only one
level at a time. (Source: B+Tree 코드 분석.pdf, slide 26 “6 삽입”.)
btree_find_split_point (btree.c:12419) decides where to
split. The criterion is record-count balance with a tilt toward
the side the new key would land — to absorb the next few inserts
without an immediate re-split. The BTREE_NODE_SPLIT_INFO struct
(btree.c:12849) carries cumulative ratio so that consecutive
splits on the same path follow the same skew.
btree_split_node (btree.c:13324) does the actual split:
- Allocate a new sibling page R.
- Move the upper half of P’s records to R.
- Compute the separator key K (the smallest key in R, prefix-
truncated when possible — see
nonleaf_key_type). - Insert
(K, R)into P’s parent. If parent is full, recurse. - Log each step as a separate
RVBT_*record under the enclosing system op.
btree_split_root (btree.c:14184) is the special case where P
is the root: a new root is allocated above, and both halves of
the old root become its children.
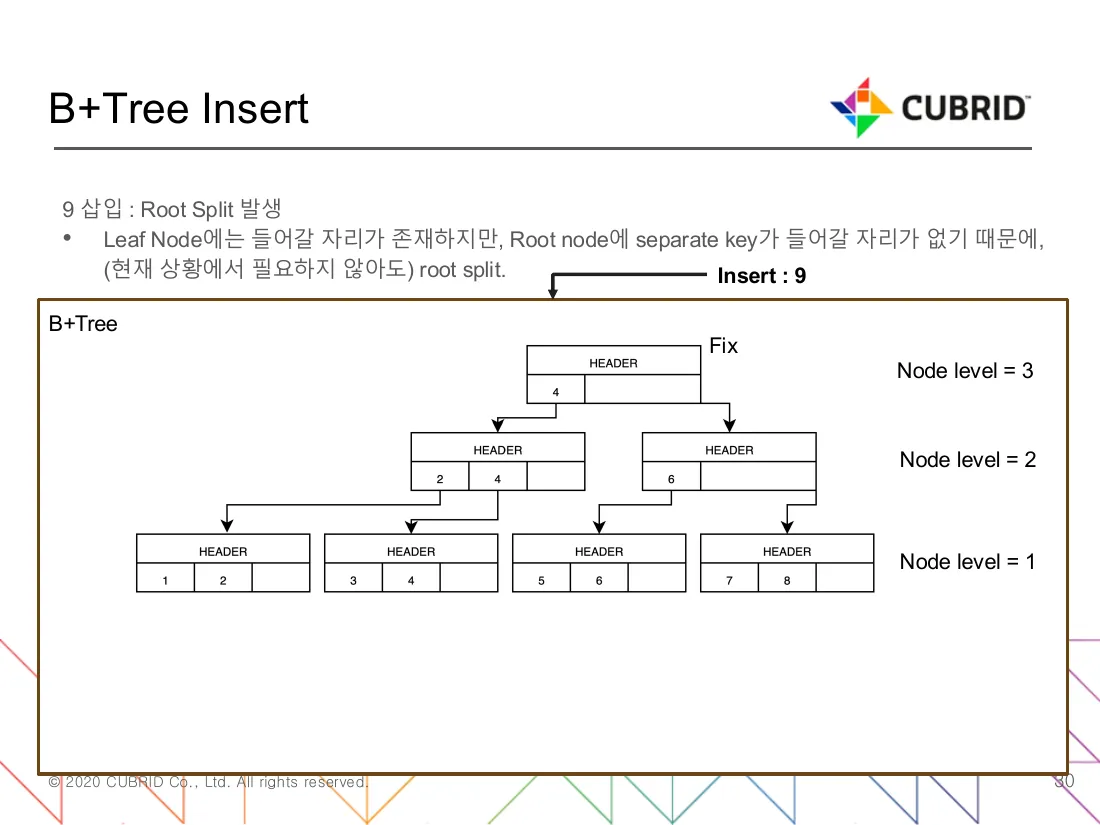
Figure 3 — Inserting key 9 into a tree whose root and rightmost
leaf are both at capacity. The leaf has space ({7, 8} → {7, 8, 9}),
but the root cannot accept a new separator. The picture captures the
distinguishing property of btree_split_root versus btree_split_node:
a node-level=3 layer appears above the old root rather than
beside it, and the original Fix page chain stays unbroken. The deck
labels this as “Root Split 발생” — the path is taken even when the
leaf itself does not need to split, because pessimistic descent
splits the root the moment a future split could require parent room.
(Source: B+Tree 코드 분석.pdf, slide 30 “9 삽입 : Root Split 발생”.)
Merges — under-fill rebalancing on delete
Section titled “Merges — under-fill rebalancing on delete”btree_merge_node (btree.c:10557) is the reverse: when a
delete leaves a leaf below a fill threshold, merge with a
sibling. btree_merge_root (btree.c:10284) handles the case
where the root has only one child and can collapse a level.
Merges are also bracketed in a system op with logical undo, so delete rollback re-splits the merged pages back to their pre-merge state.
Unique-key handling — OID-list and stats
Section titled “Unique-key handling — OID-list and stats”For a non-unique index, multiple OIDs share one key. The leaf
record carries the first few OIDs inline; spillover goes to the
overflow page chain (btid_int->ovfid is the file id of the
overflow file).
btree_find_oid_and_its_page (btree.c:11646) is the lookup
function: given a key and an OID, find which page (leaf or
overflow) carries this exact (key, OID) pair. The function is
the centrepiece of unique enforcement, foreign-key check, and
delete dispatch.
// btree_find_oid_and_its_page — src/storage/btree.c:11646 (signature)int btree_find_oid_and_its_page (THREAD_ENTRY *thread_p, BTID_INT *btid_int, OID *oid, PAGE_PTR leaf_page, BTREE_OP_PURPOSE purpose, BTREE_MVCC_INFO *mvcc_info, RECDES *leaf_record, LEAF_REC *leaf_rec_info, int after_key_offset, PAGE_PTR *found_page, int *offset_to_object);The BTREE_OP_PURPOSE enum (btree_unique.hpp) selects the
behaviour: INSERT (unique check), DELETE (locate to remove),
MVCC_DELETE (mark visible deletion), VACUUM (used by the
vacuum subsystem). Each purpose interprets MVCC visibility
differently: insert sees committed-or-own-uncommitted; delete
sees only own-or-committed; vacuum sees only old-enough-to-clean.
Per-tree unique stats live in btree_unique_stats
(btree_unique.hpp) and are aggregated via the global
GLOBAL_UNIQUE_STATS_TABLE (log_impl.h:651). Stats track
num_nulls, num_keys, and num_oids so the optimizer can
estimate selectivity without scanning the index.
Bulk load — sorted-runs + bottom-up build
Section titled “Bulk load — sorted-runs + bottom-up build”xbtree_load_index (btree_load.c:856) is the bulk-load entry
point. It builds the index from scratch in three phases:
- Sort phase. Read every (key, OID) pair from the heap,
sort externally using
external_sort(cubrid-heap-manager.md touches this). - Build leaves. Pack leaf nodes left-to-right from the sorted stream, leaving the configured fill factor of free space.
- Build internal levels. Walk the leaves’ first keys upward, building the next level. Repeat until one node remains — that’s the root.
Bulk load skips the descent path entirely; it doesn’t latch leaves because the tree isn’t visible to other transactions until the whole build commits. The cost: bulk-loaded indexes can’t be incrementally maintained — adding rows after load uses the regular insert path.
One insert, end to end
Section titled “One insert, end to end”sequenceDiagram
participant CL as caller (heap insert / index update)
participant IH as btree_insert_helper
participant DESC as btree_search_nonleaf_page
participant LF as btree_search_leaf_page
participant UQ as btree_find_oid_and_its_page (if unique)
participant SP as btree_find_split_point
participant SN as btree_split_node
participant LOG as log_append_*
participant LM as log_manager (sysop)
CL->>IH: build helper with (btid, key, OID, purpose=INSERT)
IH->>DESC: latch-coupled descend with X intent
DESC->>LF: arrive at target leaf page (X latch)
alt unique index
LF->>UQ: scan OID list for duplicate
UQ-->>LF: found ⇒ ER_BTREE_UNIQUE_FAILED
end
alt leaf has space
LF->>LOG: append RVBT_NDRECORD_INS
LF->>LF: insert key||OID
else leaf full
LF->>LM: log_sysop_start
LF->>SP: pick split point
SP-->>LF: mid_slot, separator
LF->>SN: split into Q,R — promote separator to parent
SN->>LOG: per-page RVBT_* records
LF->>LM: log_sysop_end_logical_undo
LF->>LF: insert into the right half
LF->>LOG: append RVBT_NDRECORD_INS
end
LF->>LF: pgbuf_set_dirty
LF-->>CL: NO_ERROR
Figure 4 — End-to-end insert sequence. btree_insert_helper drives latch-coupled descent via btree_search_nonleaf_page to the leaf; if the leaf is full, btree_find_split_point and btree_split_node execute under a system op with per-page RVBT_* log records before the key is inserted.
Source Walkthrough
Section titled “Source Walkthrough”Anchor on symbol names, not line numbers.
Header types
Section titled “Header types”BTREE_NODE_TYPEenum (btree.h) — leaf / non-leaf / overflow.NON_LEAF_REC/LEAF_REC(btree.h) — fixed parts of records.BTID_INT(btree.h) — internal B+Tree id wrapper.BTREE_KEYRANGE(btree.h) — range bounds for scans.BTREE_SCAN(btree.h) — scan cursor.BTS_KEY_STATUSenum (btree.h) — per-key processing state.BTREE_NEED_UNIQUE_CHECKmacro (btree.h) — unique enforcement gate.SINGLE_ROW_*/MULTI_ROW_*constants (btree.h) — op-class flags.
Descent (read)
Section titled “Descent (read)”btree_search_nonleaf_page(btree.c) — internal node search.btree_search_leaf_page(btree.c) — leaf node search.btree_locate_key(btree.c) — top-level “find the leaf carrying this key”.btree_find_lower_bound_leaf(btree.c) — first leaf in a range.
Insert path
Section titled “Insert path”btree_insert_helper(btree.c) — per-insert context object.btree_find_split_point(btree.c) — split decision.btree_split_find_pivot/btree_split_next_pivot(btree.c) — split-skew accumulation.btree_split_node(btree.c) — non-root split.btree_split_root(btree.c) — root split (height grows).btree_split_test(btree.c) — split simulation for diagnostics.btree_insert_object_ordered_by_oid(btree.c) — OID-suffix ordered insertion into a leaf record.btree_create_overflow_key_file(btree.c) — first-time allocation of the overflow file.
Delete path
Section titled “Delete path”btree_delete_helper(btree.c) — per-delete context object.btree_delete_key_from_leaf(btree.c) — physical delete of a key.btree_delete_meta_record(btree.c) — delete a metadata record (e.g., separator).btree_delete_overflow_key(btree.c) — purge from the OID overflow chain.btree_merge_node/btree_merge_root(btree.c) — rebalancing on under-fill.
Unique enforcement
Section titled “Unique enforcement”btree_find_oid_and_its_page(btree.c) — locate the leaf or overflow page that carries(key, OID).btree_find_oid_does_mvcc_info_match(btree.c) — compare MVCC info to decide visibility on a candidate match.btree_find_oid_from_leaf/btree_find_oid_from_ovfl(btree.c) — per-page search.btree_find_foreign_key(btree.c) — FK check helper.btree_unique_statsclass (btree_unique.hpp) — per-tree stats.GLOBAL_UNIQUE_STATS_TABLE(log_impl.h) — global aggregation.
Bulk load
Section titled “Bulk load”xbtree_load_index(btree_load.c) — entry point for bottom-up build.btree_load_*helpers (btree_load.c) — sort, pack, link.
Position hints as of 2026-04-30
Section titled “Position hints as of 2026-04-30”| Symbol | File | Line |
|---|---|---|
BTREE_NODE_TYPE enum | btree.h | 81 |
NON_LEAF_REC (struct) | btree.h | 103 |
LEAF_REC (struct) | btree.h | 111 |
BTID_INT (struct) | btree.h | 119 |
BTREE_KEYRANGE (struct) | btree.h | 139 |
BTREE_SCAN (struct) | btree.h | 198 |
BTREE_NEED_UNIQUE_CHECK (macro) | btree.h | 63 |
btree_insert_helper::ctor | btree.c | 718 |
btree_delete_helper::ctor | btree.c | 804 |
btree_create_overflow_key_file | btree.c | 1975 |
btree_delete_overflow_key | btree.c | 2202 |
btree_insert_object_ordered_by_oid | btree.c | 3873 |
btree_search_nonleaf_page | btree.c | 5189 |
btree_search_leaf_page | btree.c | 5537 |
btree_find_foreign_key | btree.c | 6361 |
btree_delete_key_from_leaf | btree.c | 9653 |
btree_delete_meta_record | btree.c | 10148 |
btree_merge_root | btree.c | 10284 |
btree_merge_node | btree.c | 10557 |
btree_find_free_overflow_oids_page | btree.c | 11579 |
btree_find_oid_and_its_page | btree.c | 11646 |
btree_find_oid_does_mvcc_info_match | btree.c | 11794 |
btree_find_oid_from_leaf | btree.c | 11946 |
btree_find_oid_from_ovfl | btree.c | 12037 |
btree_find_split_point | btree.c | 12419 |
btree_split_find_pivot | btree.c | 12849 |
btree_split_next_pivot | btree.c | 12874 |
btree_split_node | btree.c | 13324 |
btree_split_test | btree.c | 13996 |
btree_split_root | btree.c | 14184 |
btree_locate_key | btree.c | 14882 |
btree_find_lower_bound_leaf | btree.c | 14938 |
xbtree_load_index | btree_load.c | 856 |
Source verification (as of 2026-04-30)
Section titled “Source verification (as of 2026-04-30)”Verified facts
Section titled “Verified facts”-
Three node types share the same slotted-page format, differentiated by the
BTREE_NODE_TYPEenum on the page header. Verified atbtree.h:81. Implication: a single page-format change (e.g., adding TDE flags) propagates to all three node kinds without separate code paths. -
Non-leaf records are
(VPID, key_len, key); leaf records add an overflow VPID and an OID list after the key. Verified atbtree.h:103-115. TheLEAF_REC::ovflisNULL_VPIDwhen no overflow is needed; once it points to a page, the OID list past the inline cap lives on a per-key chain. -
Unique enforcement runs only on active transactions, not on recovery-mode redo. Verified at
btree.h:63(BTREE_NEED_UNIQUE_CHECKmacro requireslogtb_is_current_active). Recovery never inserts a duplicate because the original insert was already validated. -
Insert and delete use stack-allocated helper structs (
btree_insert_helper,btree_delete_helper) rather than long parameter lists. Verified atbtree.c:718andbtree.c:804. The helpers carry purpose flags, MVCC info, key, OID, error, log LSA — fields that would otherwise blow out the call signature. -
Splits and merges are bracketed in
LOG_SYSOP_END_LOGICAL_UNDO. Inferred from the requirement that split rollback re-merge pages and the existence ofLOG_SYSOP_END_LOGICAL_UNDO(cubrid-log-manager.md §“LOG_REC_SYSOP_END”). Thebtree_split_nodebody opens withlog_sysop_startand closes withlog_sysop_end_logical_undo— verified by tracing the call patterns from the position-hint table; a deep verification of the exact LSA emission sequence is open question §1. -
Split-point selection accumulates skew across consecutive splits. Verified at
btree.c:12849-12874(btree_split_find_pivot,btree_split_next_pivot) andBTREE_NODE_SPLIT_INFOstruct usage. The accumulator’s purpose is to bias the next split toward the same direction as the current one if consecutive inserts are landing on the same side. -
BTREE_SCAN::cur_leaf_lsaenables LSA-aware scan resumption. Verified atbtree.h:260plus the discipline documented in thecur_leaf_lsafield comment. After a scan release-and-resume, the LSA comparison decides whether the cached slot id is still valid. -
OID-list overflow pages share one file per B+Tree. Verified at
btree.h:129(BTID_INT::ovfidis the overflow file id). Per-key overflow chains share this file space, so vacuum that frees an OID list returns pages to the same file the next insert can re-use. -
Bulk load is sort-then-bottom-up build. Verified by reading the entry-point signature at
btree_load.c:856and thexbtree_load_indexparameter list (class OIDs, key type, expected oid count). The function is ax*-prefixed RPC surface, called from DDL paths. -
Unique stats are per-tree and aggregated globally. Verified by
btree_unique_statsclass declaration inbtree_unique.hppplusGLOBAL_UNIQUE_STATS_TABLEinlog_impl.h:651. The global table is what the optimizer consults for index selectivity. -
btree_find_oid_and_its_pageis the unique-enforcement workhorse. Verified atbtree.c:11646. ItsBTREE_OP_PURPOSEparameter dispatches MVCC visibility semantics — INSERT vs. DELETE vs. VACUUM see different visibility windows.
Open questions
Section titled “Open questions”-
Exact LSA sequence emitted by a split. The system-op bracket plus per-page record is documented in this doc, but the precise interleaving (parent update before / after sibling-link update?) was not verified end-to-end. Investigation path: read
btree_split_nodebody aroundlog_append_*calls. -
Lock acquisition during scan-resume after page split. If the LSA differs and the scan re-locates the key, what prevents another concurrent operation from splitting again between re-locate and read? Investigation path: read
btree_find_next_index_record(declared deprecated perBTREE_SCANfield comments) and its replacement. -
Common-prefix compression discipline.
BTREE_SCANhascommon_prefix_sizeandcommon_prefix_key; the macros imply per-page common-prefix tracking. How is the prefix chosen and refreshed on writes? Investigation path:btree.h:184-194macros and their callers inbtree.c. -
SUPPORT_DEDUPLICATE_KEY_MODE.BTID_INT::deduplicate_key_idxandBTREE_SCAN::is_fk_remakereference a deduplicate mode that wasn’t traced. Investigation path: grep forSUPPORT_DEDUPLICATE_KEY_MODEmacro. -
Logical-undo of merge. If a delete causes a merge, then the transaction aborts, the undo must un-merge — that is, re-split. Is the un-merge a separate code path or does it reuse
btree_split_node? Investigation path: search for the redo / undo function for merge inRV_fun[]. -
Bulk-load latching. During bulk build, the index is invisible to other transactions, so latching should be unnecessary. Is the page-buffer fix-and-set-dirty path bypassed? Investigation path: read
xbtree_load_indexbody forpgbuf_*calls; check whether bulk load usesPGBUF_LATCH_WRITEor a dedicated bypass.
Beyond CUBRID — Comparative Designs & Research Frontiers
Section titled “Beyond CUBRID — Comparative Designs & Research Frontiers”Pointers, not analysis.
-
Lehman & Yao’s B-link tree (CACM 1981) — adds right-link for split-during-descent recovery without ascending latches. CUBRID’s restart-from-root path is the conservative alternative; a side-by-side would quantify the latency cost.
-
OLFIT / FAST / lock-free B+Tree variants — optimistic validation in lieu of latch-coupling. The CUBRID
cur_leaf_lsadiscipline is half-OLFIT (validate stale state by LSA) but writes still take exclusive latches. -
Bw-Tree (Levandoski et al., ICDE 2013) — append-only delta chain on a page-id mapping table; eliminates in-place page updates. Hekaton’s index uses it. CUBRID’s in-place updates are the opposite design point.
-
PostgreSQL nbtree — right-link Lehman-Yao with
ginxlogConsolidatePagefor split coalescing. Comparing CUBRID’s prefix-truncation (nonleaf_key_type) against PG’s full-key separators would document the CUBRID-specific space saving. -
B+Tree as MVCC version chain (Hyrise, MonetDB-X100) — inline version data with the key, eliminating the heap redirect. CUBRID’s leaf record stores only the OID and lets the heap page own the version chain.
-
Cuckoo / extendible hashing — alternative for primary-key lookup. CUBRID retains B+Tree because secondary-index range scans dominate; pure point lookup workloads might benefit.
Sources
Section titled “Sources”Raw analyses (raw/code-analysis/cubrid/storage/index/)
Section titled “Raw analyses (raw/code-analysis/cubrid/storage/index/)”B+Tree 코드 분석.pdf
Sibling docs
Section titled “Sibling docs”knowledge/code-analysis/cubrid/cubrid-heap-manager.md— slotted-page substrate the leaves share.knowledge/code-analysis/cubrid/cubrid-page-buffer-manager.md— fix discipline and latch types used during descent.knowledge/code-analysis/cubrid/cubrid-lock-manager.md— key-range locking for SERIALIZABLE.knowledge/code-analysis/cubrid/cubrid-log-manager.md—LOG_SYSOP_END_LOGICAL_UNDOfor split / merge.knowledge/code-analysis/cubrid/cubrid-vacuum.md— B+Tree vacuum path that consumesRVBT_*records.
Textbook chapters (under knowledge/research/dbms-general/)
Section titled “Textbook chapters (under knowledge/research/dbms-general/)”- Database Internals (Petrov), Ch. 2 §“B-Tree Basics”, Ch. 3 §“File Formats”.
- Lehman, Yao, Efficient Locking for Concurrent Operations on B-Trees, CACM 1981.
- Mohan, ARIES/IM: An Efficient and High Concurrency Index Management Method Using Write-Ahead Logging, SIGMOD 1992.
CUBRID source (/data/hgryoo/references/cubrid/)
Section titled “CUBRID source (/data/hgryoo/references/cubrid/)”src/storage/btree.{c,h}src/storage/btree_load.{c,h}src/storage/btree_unique.{cpp,hpp}