(KO) CUBRID 복구 매니저 — ARIES 세 패스 재시작
목차
학술적 배경
섹션 제목: “학술적 배경”복구 매니저는 ACID-A (원자성) 의 계약을 책임진다. 그리고 WAL과 함께 ACID-D (내구성) 의 보장을 받쳐 준다. Mohan 외의 ARIES (TODS 17.1, 1992) 는 디스크 상주 관계형 엔진이라면 거의 모두 구현하는 표준 알고리즘이다. Database Internals (Petrov) 5장 §ARIES 가 그 교과서적 설명이다. 두 자료가 공통으로 강조하는 것은 재시작 문제를 세 개의 순차 패스로 나누는 구조다.
- Analysis 패스. 가장 최근 체크포인트에서 시작해 로그의 끝까지 앞으로 걸어 간다. 이 패스가 두 가지를 다시 만들어 낸다 — dirty page 테이블 (DPT) 과 transaction 테이블 (TT). 끝에 다다르면 충돌 시점에 어떤 트랜잭션이 active 였고, 어떤 페이지가 redo가 필요할 수 있는지, 그리고 redo가 시작 되어야 하는 최소 LSA가 무엇인지가 모두 정해진다.
- Redo 패스. 그 최소 redo-LSA에서 시작해 로그를 앞으로
걸어 간다. 각 로그 레코드의 대상 페이지가 충돌 시점에 더티
였을 가능성이 있으면 페이지를 fix한 뒤 비교한다 —
page.lsa < record.lsa일 때 redo 함수를 적용한다. 이 패스가 끝나면 충돌 바로 그 순간 의 데이터베이스가 정확히 복원된다. 아직 commit되지 않은 트랜잭션의 변경까지 포함해서. - Undo 패스. loser 트랜잭션 (충돌 시점에 active 였으나 commit되지 않았던 것들) 의 LSA 사슬을 거꾸로 따라 간다. undo가 가능한 레코드마다 undo 함수를 적용하고, 그 단계마다 compensation log record (CLR) 를 발행한다. CLR을 발행하는 이유는 undo 자체가 다시 재시작 가능해야 하기 때문이다.
이 모델 위에서 모든 실제 엔진은 두 가지 구현 결정을 내려야 한다. 두 결정이 본 문서 골격을 만든다.
- 로그 단위. Physical (페이지의 바이트 단위 diff) / physiological (페이지 X의 슬롯 5에 이 바이트들) / logical (B+Tree T에 키 K, OID O를 insert). CUBRID은 데이터 측 (heap, 페이지 단위 연산) 에서는 physiological 이고, 인덱스 연산 측 (B+Tree split, unique-key 충돌) 에서는 logical 이다. 인덱스 split을 physical 로 undo 하려면 페이지 전체 상태를 기록해야 하는데, 비용이 너무 크기 때문이다.
- 체크포인트 배치. Sharp/consistent 체크포인트 (엔진을
멈추고 모든 것을 flush한 뒤 단일 체크포인트 레코드를 발행)
대 fuzzy 체크포인트 (엔진을 멈추지 않은 채 active 트랜잭션
과 dirty 페이지의 스냅샷만 잡는다.
LOG_START_CHKPT와LOG_END_CHKPT두 레코드 사이에 active 작업이 계속 흐른다). CUBRID은 fuzzy 측이다. 현대 엔진들이 거의 모두 그러하다 — consistent 체크포인트는 처리량 비용이 너무 크다.
이 두 결정의 답이 보이고 나면, 본 문서의 모든 CUBRID 구조는 그 답 중 하나를 구현하거나 그 답을 더 빠르게 만들기 위해 존재한다는 점이 분명해진다.
DBMS 공통 설계 패턴
섹션 제목: “DBMS 공통 설계 패턴”WAL + 복구를 가진 모든 엔진 — PostgreSQL, InnoDB, Oracle, SQL Server, CUBRID — 은 ARIES 위에 비슷한 어휘를 얹는다. 이 어휘는 1992년 ARIES 논문에 등장하지 않는다. 교과서와 소스 사이를 잇는 공학적 어휘다.
Record-type 별 복구 디스패치
섹션 제목: “Record-type 별 복구 디스패치”각 로그 레코드는 LOG_RCVINDEX (또는 그에 해당하는 enum) 를 들고
다닌다. 이 enum이 record kind 별 함수 테이블의 인덱스다. 한
엔트리는 (undofun, redofun) 쌍과 디버그 dump 함수로 구성된다.
새 record kind를 추가하는 의식이 세 단계로 정해져 있다 — enum
값을 추가, redo와 undo 함수를 작성, 표에 등록. 이 의식은 엔진을
가로질러 동일하다. PostgreSQL의 RmgrTable[].rm_redo, InnoDB의
recv_parse_or_apply_log_rec_body, CUBRID의 RV_fun[] 이 모두
같은 자리를 차지한다.
Analysis 시점에 재구성되는 dirty page 테이블
섹션 제목: “Analysis 시점에 재구성되는 dirty page 테이블”analysis 시점에 엔진은 디스크 페이지의 내용을 신뢰할 수 없다. 어떤 더티 페이지는 디스크에 닿았고, 어떤 더티 페이지는 닿지 않았기 때문이다. dirty page 테이블이 redo 측에 알려주는 것이 바로 그 차이다 — 이 페이지는 디스크에 못 갔을 가능성이 있다. CUBRID은 이전 체크포인트의 DPT를 기반으로 하고, 그 체크포인트 이후 페이지를 더티로 만든 모든 로그 레코드를 더해 DPT를 다시 만든다.
Loose-end 부가 정보를 가진 transaction table
섹션 제목: “Loose-end 부가 정보를 가진 transaction table”analysis는 transaction 테이블도 다시 만든다 — 로그 범위 안에 보인 모든 TRANID를, 충돌 시점의 상태가 무엇이었는지가 들어 간다. active 트랜잭션은 loser 가 되어 undo된다. postpone 이 남은 committed 트랜잭션은 postpone replay로 마무리된다. 2PC prepared 트랜잭션은 in-doubt 상태로 남고, 재시작 후에도 살아 있으면서 coordinator의 최종 결정을 기다린다.
Compensation log record (CLR)
섹션 제목: “Compensation log record (CLR)”undo가 적용되면 CLR이 발행된다. CLR은 redo-only 다. 그 forward-LSA 는 자기 undo 대상의 직전 레코드를 가리킨다. 따라서 undo 도중 다시 충돌이 일어나도, 부분적으로 적용된 undo가 다음 redo 패스 에서 forward-redo로 다시 적용되며 이어서 진행된다. CLR이 들고 다니는 undo-next 포인터는 사슬을 따라 걸어 가는 자가 이미 undo된 레코드를 건너 뛰는 데 쓰인다.
Fuzzy 체크포인트와 두 개의 로그 레코드
섹션 제목: “Fuzzy 체크포인트와 두 개의 로그 레코드”fuzzy 체크포인트는 두 레코드를 발행한다. LOG_START_CHKPT (복구
analysis가 시작점으로 삼는 LSA) 와 LOG_END_CHKPT (active
트랜잭션 스냅샷, dirty page 테이블, active top-op 들을 담음).
두 레코드 사이에 엔진은 평소처럼 트래픽을 처리한다. analysis가
이 윈도우 안의 in-flight 레코드를 처리하는 방식은 단순하다 —
체크포인트 이후 레코드와 동일하게 다룬다.
Parallel redo
섹션 제목: “Parallel redo”ARIES의 redo 패스는 단일 페이지에 대해서는 순차여야 한다 (LSN 순서가 지켜져야 한다). 그러나 페이지를 가로지르는 redo는 자명 하게 병렬이다. 현대 엔진들 (PostgreSQL 15+, InnoDB, CUBRID) 은 worker 풀을 두고, 로그 레코드를 대상 VPID로 묶어 각 묶음을 별도 worker에 보낸다. ARIES 이후 재시작 속도를 가장 크게 끌어 올린 단일 변경이 이 병렬화다.
이론 ↔ CUBRID 명칭 매핑
섹션 제목: “이론 ↔ CUBRID 명칭 매핑”| 이론적 개념 | CUBRID 명칭 |
|---|---|
| ARIES analysis 패스 | log_recovery_analysis (log_recovery.c) |
| ARIES redo 패스 | log_recovery_redo (log_recovery.c) |
| ARIES undo 패스 | log_recovery_undo (log_recovery.c) |
| Per-record analysis 디스패치 | log_rv_analysis_record (log_recovery.c) |
| Per-record redo 디스패치 | log_rv_redo_record_sync<T> 템플릿 (log_recovery_redo.hpp) |
| Per-record undo 디스패치 | log_rv_undo_record (log_recovery.c) |
| 복구 함수 테이블 | RV_fun[] (recovery.h) — 각 entry: { recv_index, recv_string, undofun, redofun, dump_* } |
| 복구 인덱스 enum | LOG_RCVINDEX — RVDK / RVFL / RVHF / RVOVF / RVEH / RVBT prefix 가족 |
| 복구 인자 struct | LOG_RCV { mvcc_id, pgptr, offset, length, data, reference_lsa } (recovery.h) |
| Compensation log record | LOG_COMPENSATE (record type) → LOG_REC_COMPENSATE (log_record.hpp) |
| Compensation 함수 arm | log_rv_get_fun<LOG_REC_COMPENSATE> 가 RV_fun[rcvindex].undofun 을 반환 (redo가 아님에 주의) |
| Fuzzy 체크포인트 시작 | LOG_START_CHKPT 로그 레코드 |
| Fuzzy 체크포인트 끝 | LOG_END_CHKPT → LOG_REC_CHKPT { redo_lsa, ntrans, ntops } (log_record.hpp) |
| 체크포인트 내 active-tran 스냅샷 | LOG_INFO_CHKPT_TRANS (log_record.hpp) |
| 체크포인트 내 active-sysop 스냅샷 | LOG_INFO_CHKPT_SYSOP (log_record.hpp) |
| 체크포인트 발행 | logpb_checkpoint (log_page_buffer.c) |
| 복구 phase enum | LOG_RECVPHASE { LOG_RESTARTED, ANALYSIS, REDO, UNDO, FINISH_2PC } (log_impl.h) |
| 복구 시점 TDES 부가 정보 | LOG_RCV_TDES { sysop_start_postpone_lsa, tran_start_postpone_lsa, atomic_sysop_start_lsa, … } |
| Parallel redo coordinator | log_recovery_redo_parallel.{cpp,hpp} — VPID별 작업 큐 |
| 재시작 진입점 | log_recovery 선언 위치는 log_recovery.h:37 |
CUBRID의 구현
섹션 제목: “CUBRID의 구현”복구 매니저에는 네 개의 이동 부품이 있다. 세 패스를 구동하는
진입 orchestrator, (record-type, RCVINDEX) 를 함수 호출로
변환하는 per-record 디스패치 템플릿, analysis 패스가 다시
시작점으로 삼는 경계 레코드를 쓰는 체크포인트 발행기, 그리고
현대 코드 경로에서 페이지 간 I/O를 겹치는 parallel-redo
coordinator. 이 순서로 본다.
전체 구조
섹션 제목: “전체 구조”flowchart TB
RST["log_recovery (entry)"]
subgraph PHASES["세 패스"]
AN["Analysis pass\nlog_recovery_analysis"]
RD["Redo pass\nlog_recovery_redo"]
UN["Undo pass\nlog_recovery_undo"]
FP["Postpone pass\nlog_recovery_finish_all_postpone"]
end
subgraph DISP["Per-record 디스패치"]
RA["log_rv_analysis_record\n→ DPT, TT 갱신"]
RR["log_rv_redo_record_sync<T>\n→ RV_fun[idx].redofun"]
RU["log_rv_undo_record\n→ RV_fun[idx].undofun + CLR 발행"]
end
subgraph TBL["RV_fun[] 디스패치 테이블"]
F1["RVDK_∗ — disk manager"]
F2["RVFL_∗ — file manager"]
F3["RVHF_∗ — heap manager"]
F4["RVBT_∗ — btree"]
F5["RVEH_∗ — extensible hash"]
F6["..."]
end
RST --> AN --> RD --> FP --> UN
AN --> RA
RD --> RR
UN --> RU
RR --> TBL
RU --> TBL
그림 3 — log_recovery 진입점에서 Analysis → Redo → Postpone → Undo 네 패스가 순서대로 실행되고, 각 패스가 RV_fun[] 디스패치 테이블을 통해 서브시스템별 콜백으로 흐르는 전체 구조도. postpone 패스가 redo와 undo 사이에 위치하는 이유는 commit된 트랜잭션의 지연 동작을 loser undo보다 먼저 완료해야 하기 때문이다.
이 그림이 보여 주는 두 가지 결정이 있다. 첫째, 패스 순서.
analysis → redo → finish-postpone → undo. postpone 패스가 redo
와 undo 사이에 들어가는 데는 이유가 있다 — postpone은 commit
된 트랜잭션의 deferred 동작이다. 그래서 충돌 직전 상태가 redo로
복원된 다음에야 replay할 수 있고, 동시에 loser 트랜잭션의 undo
보다 먼저 끝나야 한다. 그렇지 않으면 undo가 postpone이 의지
하던 상태를 도로 되돌려 버릴 수 있다. 둘째, 디스패치
모양. 모든 record type은 세 콜백 (analysis-update, redo-apply,
undo-apply) 중 하나로 흐른다. 그리고 각 콜백은 글로벌 RV_fun[]
테이블을 참조하기도 하고 그렇지 않기도 한다. ARIES가 logical
이라 부르는 레코드들 — 체크포인트 시작/끝, system-op end,
savepoint — 은 함수 테이블 hop 없이 analysis 루틴 안에서 inline
처리된다. 그 의미론이 고정되어 있기 때문이다.
재시작 orchestrator
섹션 제목: “재시작 orchestrator”진입점은 log_recovery (log_recovery.h:37 에 선언, 본문은
log_recovery.c) 다. log_manager.c 의 log_initialize 가
active log 헤더에서 is_shutdown == false 를 보면 이 함수를
호출한다.
// log_recovery — src/transaction/log_recovery.c (sketch)voidlog_recovery (THREAD_ENTRY *thread_p, int ismedia_crash, time_t *stopat){ LOG_LSA start_lsa = log_Gl.hdr.chkpt_lsa; /* most-recent checkpoint */ LOG_LSA start_redolsa = NULL_LSA; LOG_LSA end_redo_lsa = NULL_LSA;
log_Gl.rcv_phase = LOG_RECOVERY_ANALYSIS_PHASE; log_recovery_analysis (thread_p, &start_lsa, &start_redolsa, &end_redo_lsa, ismedia_crash, stopat, /* etc. */);
log_Gl.rcv_phase = LOG_RECOVERY_REDO_PHASE; log_recovery_redo (thread_p, &start_redolsa, &end_redo_lsa);
log_recovery_finish_all_postpone (thread_p);
log_Gl.rcv_phase = LOG_RECOVERY_UNDO_PHASE; log_recovery_undo (thread_p);
log_Gl.rcv_phase = LOG_RESTARTED;}log_Gl.rcv_phase (log_impl.h) 는 글로벌 복구 단계 enum이다.
다른 모듈들이 재시작 동안 자기 동작을 결정할 때 이 값을 읽는다.
가령 buffer manager는 redo 중에 dirty 추적 검사를 건너뛴다.
dirty 비트가 그 시점에는 아직 의미를 가지지 않기 때문이다.
Analysis 패스 — DPT와 TT 다시 만들기
섹션 제목: “Analysis 패스 — DPT와 TT 다시 만들기”log_recovery_analysis (log_recovery.c:2587) 는 chkpt_lsa
에서 시작해 매 레코드의 헤더를 읽으며 앞으로 걷는다. 두 가지를
유지한다.
- transaction 테이블 — TRANID로 색인된다. 트랜잭션마다
head_lsa,tail_lsa, 현재 상태, 그리고LOG_RCV_TDES부가 정보 (예 —analysis_last_aborted_sysop_lsa. 이는 nested system op이 abort되었지만 그 종료 레코드가 다음 system op의 시작 레코드보다 앞선 경우를 위한 부가 정보다) 를 기록한다. - dirty page 테이블 — VPID로 색인된다. 체크포인트 이후 처음 으로 더티가 된 시점의 LSA를 페이지마다 기록한다.
per-record 디스패처가 log_rv_analysis_record
(log_recovery.c:2378) 다. 본문은 LOG_RECTYPE 에 대한 switch
이며, record kind에 따라 DPT와 TT를 갱신한다. 주요 arm을 보면
다음과 같다.
// log_rv_analysis_record — switch arms (sketch from log_recovery.c)switch (log_type) { case LOG_UNDOREDO_DATA: case LOG_MVCC_UNDOREDO_DATA: /* TT: extend tran's tail_lsa, mark TRAN_ACTIVE. DPT: add (vpid, this_lsa) if not present. */ break;
case LOG_COMMIT: /* TT: state = TRAN_UNACTIVE_COMMITTED. */ break;
case LOG_ABORT: /* TT: state = TRAN_UNACTIVE_ABORTED. */ break;
case LOG_SYSOP_END: /* Open sysop bracket closes; LOG_RCV_TDES bookkeeping for logical-undo / logical-compensate / logical-run-postpone arms. */ break;
case LOG_2PC_PREPARE: /* TT: state = TRAN_UNACTIVE_2PC_PREPARE. At end of analysis, this tran is in-doubt — keep, not loser. */ break; case LOG_END_CHKPT: /* If this is a *new* checkpoint within the analysis window, merge its DPT/TT into ours. */ break; case LOG_END_OF_LOG: /* Stop. */ break; // ... condensed ... }analysis가 끝나면 모든 TRANID는 네 분류 중 하나에 들어간다 —
committed, aborted, loser, in-doubt. DPT의 가장 작은 LSA가
start_redolsa 가 된다. 그 이전에는 어떤 페이지도 더티가 아니
었으니, redo 패스가 그 이전을 건드릴 필요가 없다는 점이 보장
된다.
Redo 패스 — 템플릿을 통한 현대 디스패치
섹션 제목: “Redo 패스 — 템플릿을 통한 현대 디스패치”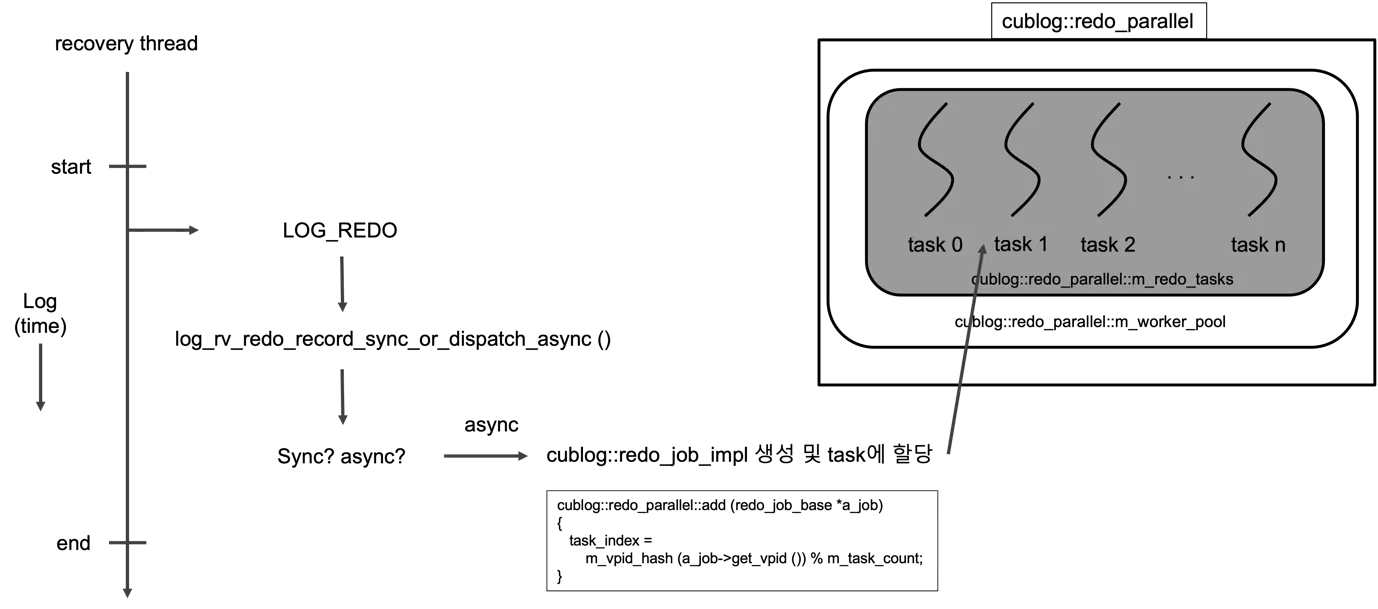
그림 1 — 왼쪽 타임라인의 recovery 스레드 한 개가 LSA 순서대로
LOG_REDO 레코드를 읽는다. 레코드마다
log_rv_redo_record_sync_or_dispatch_async 를 호출한다는 점이
출발점이다. 해당 recovery 함수가 sync 전용이면 그 자리에서 곧바로
적용한다. 그렇지 않으면 cublog::redo_job_impl 객체를 만들어
cublog::redo_parallel 에 넣는다. redo_parallel 은 VPID 를 해시해
서 m_redo_tasks 워커 스레드 가운데 하나로 보낸다. 이 해시 분배가
페이지별 락 없이도 병렬 redo 의 정합성을 지키는 핵심이다. 즉 같은
페이지를 건드리는 레코드는 항상 같은 워커로 떨어지므로, 페이지별
LSA 단조성은 깨지지 않으면서 서로 다른 페이지의 작업은 자유롭게
겹친다. (출처: recovery manager_v0.2.docx, redo 디스패치 그림.)
redo 패스는 start_redolsa 에서 시작해 앞으로 걷는다. 페이지를
갱신하는 모든 레코드 (LOG_*UNDOREDO_DATA, LOG_REDO_DATA,
LOG_MVCC_*, LOG_RUN_POSTPONE, LOG_COMPENSATE) 마다 다음을
수행한다.
- 대상 페이지를 buffer pool에 fix.
page.lsa와record.lsa를 비교.page.lsa >= record.lsa이면 변경이 이미 디스크에 있으니 건너뛴다. 아니면 다음 단계.RV_fun[record.rcvindex].redofun (rcv)를 호출해 적용.page.lsa = record.lsa로 설정하고 dirty로 표시.- 페이지 unfix.
CUBRID은 이 과정을 log_rv_redo_record_sync<T> 라는 템플릿 디스
패처로 표현한다 (log_recovery_redo.hpp). 템플릿 인자 T 는
로그 레코드의 타입드 페이로드다 (LOG_REC_UNDOREDO,
LOG_REC_MVCC_UNDOREDO, LOG_REC_REDO, LOG_REC_COMPENSATE
등). 페이로드에 따라 다른 필드를 추출하기 위해 T 별 특화가
필요한 함수가 다섯 개다 — log_rv_get_log_rec_data<T>,
log_rv_get_log_rec_redo_length<T>, log_rv_get_log_rec_offset<T>,
log_rv_get_log_rec_mvccid<T>, log_rv_get_fun<T>.
// log_rv_redo_record_sync<T> — src/transaction/log_recovery_redo.hpp (condensed)template <typename T>voidlog_rv_redo_record_sync (THREAD_ENTRY *thread_p, log_rv_redo_context &redo_context, const log_rv_redo_rec_info<T> &record_info, const VPID &rcv_vpid){ const LOG_DATA &log_data = log_rv_get_log_rec_data<T> (record_info.m_logrec);
LOG_RCV rcv; if (!log_rv_fix_page_and_check_redo_is_needed (thread_p, rcv_vpid, rcv, log_data.rcvindex, record_info.m_start_lsa, redo_context.m_end_redo_lsa)) return; /* page.lsa >= record.lsa, no work */
rcv.length = log_rv_get_log_rec_redo_length<T> (record_info.m_logrec); rcv.mvcc_id = log_rv_get_log_rec_mvccid<T> (record_info.m_logrec); rcv.offset = log_rv_get_log_rec_offset<T> (record_info.m_logrec);
log_rv_get_log_rec_redo_data<T> (thread_p, redo_context, record_info, rcv);
rvfun::fun_t redofunc = log_rv_get_fun<T> (record_info.m_logrec, log_data.rcvindex); redofunc (thread_p, &rcv);
pgbuf_set_lsa (thread_p, rcv.pgptr, &record_info.m_start_lsa);}여기에 한 가지 미묘하지만 받침대 같은 특화가 있다. LOG_REC_COMPENSATE
(CLR) 를 log_rv_get_fun 이 반환하는 함수는 RV_fun[rcvindex].undofun
이다 — redofun 이 아니다.
// log_rv_get_fun specialisation — src/transaction/log_recovery_redo.hpp:396template <>inline rvfun::fun_tlog_rv_get_fun<LOG_REC_COMPENSATE> (const LOG_REC_COMPENSATE &, LOG_RCVINDEX rcvindex){ // yes, undo return RV_fun[rcvindex].undofun;}소스의 코멘트가 직접 yes, undo 라고 적혀 있다. 그 이유는 이렇게 풀어 쓸 수 있다 — CLR의 페이로드는 이전에 rollback된 동작 의 undo 이미지다. 복구가 redo 패스 도중에 CLR을 만나면, 그 undo 이미지를 forward로 다시 적용해서 undo가 끝난 시점의 상태를 복원해야 한다. 함수 테이블의 undo arm이 바로 그 동작을 담고 있다는 뜻이다. redo arm을 호출하면 원래 변경을 다시 적용하는 꼴이 되어 복구가 망가진다. 더블-fault 복구에서 데이터가 사라지는 대표적인 자리가 이 곳이다.
복구 디스패치 테이블
섹션 제목: “복구 디스패치 테이블”RV_fun[] (recovery.h:234) 가 중심 디스패치 테이블이다. 각
엔트리는 다음 모양이다.
// struct rvfun — src/transaction/recovery.hstruct rvfun{ using fun_t = int (*)(THREAD_ENTRY *thread_p, LOG_RCV *logrcv); using dump_fun_t = void (*)(FILE *fp, int length, void *data);
LOG_RCVINDEX recv_index; /* For verification — must equal the array index */ const char *recv_string; /* For debug logging */ fun_t undofun; fun_t redofun; dump_fun_t dump_undofun; dump_fun_t dump_redofun;};함수에 전달되는 복구 인자 struct는 다음과 같다.
// LOG_RCV — src/transaction/recovery.hstruct log_rcv{ MVCCID mvcc_id; PAGE_PTR pgptr; /* Page to recover; recovery functions must not free but must mark dirty when needed. */ PGLENGTH offset; /* Offset/slot in pgptr */ int length; const char *data; /* Replacement data; pointer becomes invalid after the call */ LOG_LSA reference_lsa; /* For compensate / postpone — the related LSA */};LOG_RCVINDEX enum (recovery.h:36) 은 서브시스템별로 묶여
있다.
| Prefix | 서브시스템 | 예시 |
|---|---|---|
| RVDK_ | Disk manager (volumes, sectors) | RVDK_FORMAT, RVDK_RESERVE_SECTORS |
| RVFL_ | File manager (extents, file headers) | RVFL_ALLOC, RVFL_DEALLOC, RVFL_EXTDATA_* |
| RVHF_ | Heap file manager | RVHF_INSERT, RVHF_MVCC_INSERT, RVHF_UPDATE |
| RVOVF_ | Heap overflow records | RVOVF_NEWPAGE_INSERT, RVOVF_PAGE_UPDATE |
| RVEH_ | Extensible hash (옛 인덱스 타입) | RVEH_INSERT, RVEH_DELETE |
| RVBT_ | B+Tree | RVBT_NDHEADER_UPD, RVBT_NDRECORD_INS 등 |
RCV_IS_BTREE_LOGICAL_LOG 매크로 (recovery.h:241) 가 logical
로깅을 쓰는 B+Tree 인덱스를 별도로 표시한다. 이 인덱스들은 undo
시점의 페이지 상태가 physical undo의 가정과 맞지 않을 수 있어
다른 처리가 필요하다. 목록에는 RVBT_DELETE_OBJECT_PHYSICAL,
RVBT_MVCC_DELETE_OBJECT, RVBT_MVCC_INSERT_OBJECT,
RVBT_NON_MVCC_INSERT_OBJECT, RVBT_MARK_DELETED 등이 들어
간다.
Undo 패스 — loser 사슬을 거꾸로 걷기
섹션 제목: “Undo 패스 — loser 사슬을 거꾸로 걷기”log_recovery_undo (log_recovery.c:4418) 가 analysis가 식별한
loser 트랜잭션 위를 순회한다. 각 트랜잭션마다 prev_tranlsa 사슬
을 tail_lsa 에서 거꾸로 걸으면서, undo 가능한 레코드마다
log_rv_undo_record (log_recovery.c:163) 를 호출한다. 매 undo
가 CLR을 발행한다. 사슬이 트랜잭션의 head_lsa 에 도달하면 (또는
logical-undo 시스템 op을 다루는 LOG_SYSOP_END_LOGICAL_UNDO 를
만나면) 트랜잭션의 상태가 TRAN_UNACTIVE_UNILATERALLY_ABORTED 로
표시된다.
CLR의 undo_nxlsa 필드 (LOG_REC_COMPENSATE 안) 가 “방금 undo
한 레코드의 직전 레코드” 를 가리킨다. 그래서 undo 도중 다시 충돌
이 발생해도, 다음 redo 패스가 부분 CLR 사슬을 forward로 재생
하면서 같은 자리에서 다시 시작한다는 뜻이다. ARIES가 자기 이름
으로 강조하는 undo 자체가 redo 가능하다 는 성질이 여기서 나온다.
Postpone 패스 — deferred 동작 replay
섹션 제목: “Postpone 패스 — deferred 동작 replay”log_recovery_finish_all_postpone (log_recovery.c:4243) 가 그
사이 케이스를 처리한다 — commit은 했지만 postpone 동작이 큐에
남아 있던 트랜잭션들이다. postpone은 commit 이후 실행되는
deferred 동작이다 (예 — 카탈로그 정리, 파일 감소 카운터). 모두
복구가 발견할 수 있는 형태로 기록된다 — commit 이전에
LOG_POSTPONE 레코드를 남기고, commit이
LOG_COMMIT_WITH_POSTPONE 으로 postpone이 남았다 를 표시한다.
이 패스는 적절한 상태 (TRAN_UNACTIVE_COMMITTED_WITH_POSTPONE,
TRAN_UNACTIVE_TOPOPE_COMMITTED_WITH_POSTPONE) 에 있는 TT
엔트리들을 순회하며 postpone들을 끝까지 실행한 뒤, 상태를
TRAN_UNACTIVE_COMMITTED 로 전이한다.
체크포인트 — 다음 analysis가 시작점으로 삼는 경계
섹션 제목: “체크포인트 — 다음 analysis가 시작점으로 삼는 경계”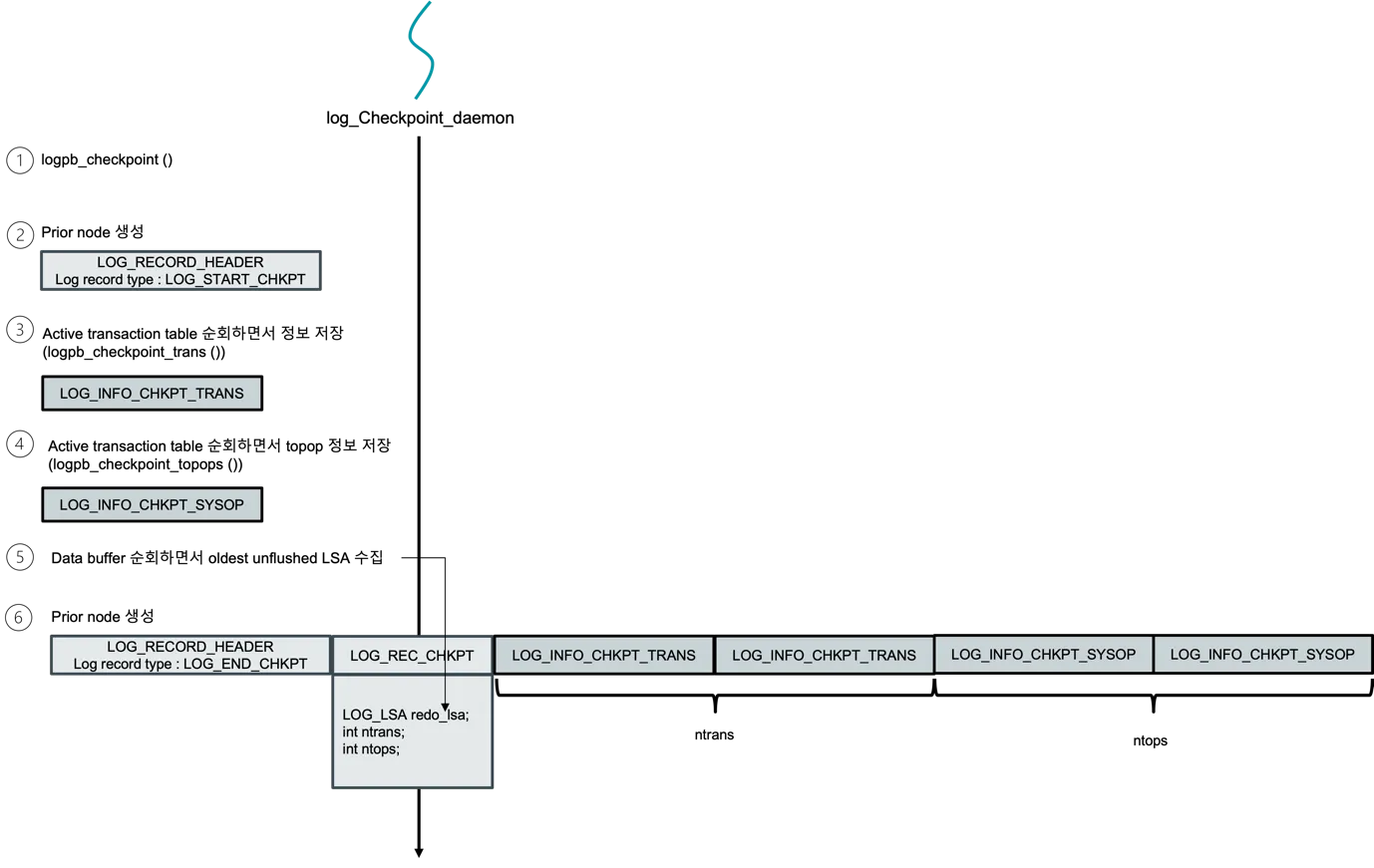
그림 2 — log_Checkpoint_daemon 이 한 번 깨어났을 때 따르는 번호
타임라인이다. ① logpb_checkpoint 호출. ② LOG_START_CHKPT 를
append — 이 LSA 가 다음 재시작이 분석을 시작할 chkpt_lsa 가 된다
는 점이 중요하다. ③ active transaction table 을 순회하며 살아 있는
TDES 마다 LOG_INFO_CHKPT_TRANS 를 한 개씩 적는다. 함수는
logpb_checkpoint_trans 다. ④ active 시스템 op 스택을 순회해
LOG_INFO_CHKPT_SYSOP 를 적는다 (logpb_checkpoint_topops). ⑤
페이지 버퍼의 dirty 리스트를 따라 걸어 가장 작은 unflushed LSA 를
찾는다. 이 값이 redo-LSA 힌트가 되어, 다음 analysis 패스가 그 아래
의 모든 것을 건너뛸 수 있게 해준다. ⑥ LOG_END_CHKPT 와 패킹된
LOG_REC_CHKPT 페이로드(redo_lsa, ntrans, ntops, 그리고 transaction/
sysop 배열) 를 적는다. 이 절차가 fuzzy 라고 불리는 이유는 ③–⑤ 가
trantable 을 멈추지 않은 채 진행되기 때문이다. 교과서가 말하는
quiescent 체크포인트와 갈라지는 지점이다. (출처: recovery manager_v0.2.docx, 체크포인트 daemon 그림.)
체크포인트는 logpb_checkpoint (log_page_buffer.c:6877) 가
발행한다. 호출 주체는 체크포인트 daemon이며, 호출 간격은 설정
가능하다 (LOG_GLOBAL 의 chkpt_every_npages). 이 함수가 따르는
fuzzy 체크포인트 절차는 다음과 같다.
- trantable critical section을 read 모드로 진입. 그 동안 다른 트랜잭션들은 계속 실행된다.
LOG_START_CHKPT를 append. 그 LSA가 다음 재시작 시 analysis가 시작점으로 삼는chkpt_lsa가 된다.- trantable을 따라 걸으며 active TDES 마다
LOG_INFO_CHKPT_TRANS스냅샷을 쌓는다 (head/tail LSA, undo-next, postpone-next, savepoint, 상태, user). 이 일을logpb_checkpoint_trans(log_page_buffer.c:6783) 가 한다. - active 시스템 op들도 마찬가지로
LOG_INFO_CHKPT_SYSOP스냅샷을 쌓는다 —logpb_checkpoint_topops(log_page_buffer.c:6833). - buffer manager의 dirty page 리스트를 따라 걸으며 페이지마다
(vpid, recovery_lsa)쌍을 잡는다. 그 중 가장 작은 LSA가 redo-LSA 힌트가 된다. LOG_END_CHKPT를 append. 페이로드는LOG_REC_CHKPT { redo_lsa, ntrans, ntops }와 그 뒤를 잇는 trans/topops/dpt 배열이다.- 두 레코드 모두 안정 저장소에 닿도록 로그 force-flush.
log_Gl.hdr.chkpt_lsa를 시작 레코드의 LSA로 갱신한 뒤 로그 헤더를 force-flush.
핵심 성질이 하나 있다 — 2단계와 6단계 사이 에 다른 트랜잭션
들이 계속 진행하면서 자기 로그 레코드를 발행한다. analysis가 이
윈도우를 자연스럽게 흡수하는 방식은 단순하다 — LOG_END_CHKPT
를 먼저 읽고, 그 다음 시작 레코드부터 다시 걷는다. 그 윈도우
안의 어떤 레코드도 체크포인트 이후 레코드와 같은 방식으로
처리되니, 정합성은 깨지지 않는다는 점이다.
Parallel redo — 페이지 간 I/O 겹치기
섹션 제목: “Parallel redo — 페이지 간 I/O 겹치기”log_recovery_redo_parallel.{cpp,hpp} 가 redo 패스의 현대 코드
경로다. 핵심 통찰은 단순하다 — 단일 페이지의 redo는 LSN 순서로
순차여야 하지만, 페이지 사이의 redo는 자명하게 병렬이다.
coordinator는 VPID별 작업 큐를 둔다. thread 풀 (크기 설정 가능)
에 작업을 분산한다. 동기화는 buffer manager의 페이지 fix가
자연스럽게 제공한다 — 같은 페이지를 두 worker가 동시에 fix할 수
없으니, 같은 페이지를 만지는 작업은 buffer manager 측에서 직렬화
된다는 뜻이다.
log_recovery_redo_perf.hpp 의 성능 카운터 (PSTAT_LOG_REDO_FUNC_EXEC,
perfmon_counter_timer_raii_tracker) 가 per-redo 시간을 보고
한다. 이 카운터는 두 가지 시점 — 재시작 시점의 복구 redo 경로,
그리고 페이지 서버 복제 경로 — 을 모두 커버한다. 둘 다 같은
디스패처를 공유하기 때문이다.
세 패스 타임라인
섹션 제목: “세 패스 타임라인”sequenceDiagram participant LR as log_recovery participant AN as log_recovery_analysis participant RD as log_recovery_redo participant FP as log_recovery_finish_all_postpone participant UN as log_recovery_undo participant DK as 디스크 Note over LR: 서버 시작 — hdr.is_shutdown == false LR->>AN: walk from chkpt_lsa AN->>DK: read log records AN-->>LR: TT, DPT, start_redolsa, end_redo_lsa LR->>RD: redo from start_redolsa to end_redo_lsa RD->>DK: fix-and-apply per record (parallel by VPID) LR->>FP: finish committed-with-postpone trans FP->>DK: replay postpones LR->>UN: undo loser trans UN->>DK: walk prev_tranlsa, apply undofun, emit CLR Note over LR: rcv_phase = LOG_RESTARTED
그림 4 — log_recovery가 네 패스를 순서대로 호출하고 각 패스가 디스크를 읽고 쓰는 단계별 시퀀스. Analysis가 TT · DPT · start_redolsa를 반환한 뒤 Redo가 VPID 별 병렬 적용을 수행하고, 마지막으로 rcv_phase = LOG_RESTARTED가 설정되어 복구가 완료된다는 점이 핵심이다.
소스 코드 가이드
섹션 제목: “소스 코드 가이드”anchor는 심볼명 이다. 라인은 흘러간다.
재시작 진입
섹션 제목: “재시작 진입”log_recovery(log_recovery.h, 본문log_recovery.c) — 세 패스 driver.log_Gl.rcv_phase(LOG_RECVPHASE,log_impl.h) — 글로벌 단계 표시.log_recovery_resetlog(log_recovery.c) — 복구 성공 후 로그를 새 append LSA로 truncate.
Analysis 패스
섹션 제목: “Analysis 패스”log_recovery_analysis(log_recovery.c) — 체크포인트 에서부터 forward walk.log_rv_analysis_record(log_recovery.c) — record type 별 switch로 TT와 DPT 갱신.LOG_INFO_CHKPT_TRANS/LOG_INFO_CHKPT_SYSOP(log_record.hpp) — analysis가 부트스트랩 위해 읽는 체크 포인트 스냅샷 엔트리.
Redo 패스
섹션 제목: “Redo 패스”log_recovery_redo(log_recovery.c) — start_redo_lsa부터 forward walk.log_rv_redo_record_sync<T>(log_recovery_redo.hpp) — per-record-type 템플릿 디스패처.log_rv_get_fun<T>(log_recovery_redo.hpp) — record kind 에 따라redofun또는undofun을 선택 (CLR은 undo).log_rv_fix_page_and_check_redo_is_needed(log_recovery.h, 본문log_recovery.c) — 적용 여부를 결정하는 LSN 비교.log_rv_get_log_rec_redo_data<T>(log_recovery_redo.hpp) —LOG_DIFF_UNDOREDO_DATA의 unzip + diff-merge.log_recovery_redo_parallel.{cpp,hpp}— VPID별 작업 큐와 worker 풀.
Undo 패스
섹션 제목: “Undo 패스”log_recovery_undo(log_recovery.c).log_rv_undo_record(log_recovery.c) — per-record undo 디스패처. CLR을 발행.log_rv_get_unzip_log_data(log_recovery.c,log_recovery.h에 선언) — 압축된 undo 레코드 압축 해제.
Postpone 패스
섹션 제목: “Postpone 패스”log_recovery_finish_all_postpone(log_recovery.c).log_do_postpone(log_manager.c) — 런타임 postpone driver. 복구 패스도 같은 함수를 사용한다.
체크포인트
섹션 제목: “체크포인트”logpb_checkpoint(log_page_buffer.c) — fuzzy 체크포인트 발행기.logpb_checkpoint_trans(log_page_buffer.c) — TDES별 스냅샷.logpb_checkpoint_topops(log_page_buffer.c) — sysop별 스냅샷.logpb_dump_checkpoint_trans(log_page_buffer.c) —cubrid logdump용 스냅샷 디버그 dump.
복구 디스패치
섹션 제목: “복구 디스패치”RV_fun[](recovery.h) — 디스패치 테이블.LOG_RCVINDEXenum (recovery.h).LOG_RCVstruct (recovery.h).RCV_IS_BTREE_LOGICAL_LOG매크로 (recovery.h).rv_check_rvfuns(recovery.h) — 디버그 빌드 invariant 검사기. 모든 엔트리가RV_fun[i].recv_index == i인지 assert.
이 개정 시점의 위치 힌트 (2026-04-30)
섹션 제목: “이 개정 시점의 위치 힌트 (2026-04-30)”| 심볼 | 파일 | 라인 |
|---|---|---|
log_recovery (declaration) | log_recovery.h | 37 |
log_rv_analysis_record | log_recovery.c | 2378 |
log_recovery_analysis | log_recovery.c | 2587 |
log_recovery_redo | log_recovery.c | 3251 |
log_recovery_finish_all_postpone | log_recovery.c | 4243 |
log_recovery_undo | log_recovery.c | 4418 |
log_recovery_resetlog | log_recovery.c | 5221 |
log_rv_redo_record | log_recovery.c | 430 |
log_rv_undo_record | log_recovery.c | 163 |
log_rv_redo_record_modify | log_recovery.c | 6173 |
log_rv_undo_record_modify | log_recovery.c | 6191 |
log_rv_redo_record_sync<T> (tmpl) | log_recovery_redo.hpp | 587 |
log_rv_get_fun<LOG_REC_COMPENSATE> | log_recovery_redo.hpp | 396 |
log_rv_redo_context | log_recovery_redo.hpp | 33 |
LOG_RCV struct | recovery.h | 195 |
struct rvfun | recovery.h | 221 |
LOG_RCVINDEX enum | recovery.h | 36 |
RCV_IS_BTREE_LOGICAL_LOG macro | recovery.h | 241 |
logpb_checkpoint | log_page_buffer.c | 6877 |
logpb_checkpoint_trans | log_page_buffer.c | 6783 |
logpb_checkpoint_topops | log_page_buffer.c | 6833 |
LOG_REC_CHKPT struct | log_record.hpp | 345 |
LOG_INFO_CHKPT_TRANS struct | log_record.hpp | 354 |
LOG_INFO_CHKPT_SYSOP struct | log_record.hpp | 372 |
소스 검증 (2026-04-30 기준)
섹션 제목: “소스 검증 (2026-04-30 기준)”검증된 사실
섹션 제목: “검증된 사실”-
패스 순서는 analysis → redo → postpone → undo이다 — 교과서 ARIES가 시사하는 analysis → redo → undo 가 아니다.
log_recovery본문 (위 sketch 참조) 와 명시적log_recovery_finish_all_postpone호출에서 검증. 교과서 순서에서 벗어난 것은 의도적이다 — postpone은 commit된 트랜잭션의 deferred 동작을 구체화하기 때문에, loser들의 undo가 시작되기 전에 끝나야 한다. 그렇지 않으면 undo가 postpone이 의지하는 상태를 다시 되돌려 버릴 수 있다. -
CLR을 redo 시점에 만나면
RV_fun[]의 undo 함수를 호출한다 — redo 함수가 아니다.log_recovery_redo.hpp:396-401에서 검증. 소스의 인라인 코멘트가 직접 yes, undo 라고 적혀 있다. 그 이유는 CLR의 페이로드가 이전에 rollback된 동작 의 undo 이미지이기 때문이다. redo 도중 그것을 forward 로 다시 적용한다는 것은 그 undo를 다시 적용한다는 뜻이고, 이는 undo arm이 하는 일과 같다. -
redo의 per-record 디스패치는
LOG_RECTYPE이 아니라 페이 로드 타입으로 템플릿 디스패치된다.log_recovery_redo.hpp에서 검증 — primary 템플릿log_rv_redo_record_sync<T>와LOG_REC_UNDOREDO,LOG_REC_MVCC_UNDOREDO,LOG_REC_REDO,LOG_REC_MVCC_REDO,LOG_REC_RUN_POSTPONE,LOG_REC_COMPENSATE별 특화. 컴파일 타임 디스패치가 hot redo 루프의 페이로드 모양 검사를 제거한다. -
복구 인자 struct
LOG_RCV는 자기 copy / move 연산을 delete한다.recovery.h:208-213에서 검증. 함의 — 복구 함수는 이 struct를 포인터로 받고,data의 소유권은 빌려 쓰는 것이며 surrounding scope이 끝나면 무효화된다. 소스의 코멘트도 명시한다 — “Pointer becomes invalid once the recovery of the data is finished”. -
체크포인트는 fuzzy다 —
LOG_START_CHKPT와LOG_END_CHKPT가 별도 레코드다.logpb_checkpoint본문을 읽으며 검증.LOG_START_CHKPT는 trans/topops/DPT 열거 이전에 append 되고,LOG_END_CHKPT는 이후에 append된다. 글로벌log_Gl.hdr.chkpt_lsa는 시작 레코드의 LSA로 전진한다. -
active log 헤더에는
chkpt_lsa와smallest_lsa_at_last_chkpt이 별도로 있다.log_storage.hpp:141,log_storage.hpp:163에서 검증. 첫 번째는 복구 시작점이고, 두 번째는 archive 제거를 위한 워터마크다 (아래 페이지를 가진 archive는 충돌 복구에 더 이상 필요 없다). -
복구 시점 TDES 부가 정보는 별도 map이 아니라 TDES 안에 저장된다.
log_impl.h:558에서 검증 (LOG_TDES::rcv필드, 타입LOG_RCV_TDES). 이 부가 정보는sysop_start_postpone_lsa,tran_start_postpone_lsa,atomic_sysop_start_lsa,analysis_last_aborted_sysop_lsa와_start_lsa를 담는다. analysis 동안 채워지고 redo/undo 패스가 소비한다. -
복구 디스패치 테이블은 정적으로 정의되어 있다 — 새
LOG_RCVINDEX를 추가하려면 undo와 redo 함수 포인터를 둘 다 등록해야 한다.recovery.h:221-234(struct 정의 + extern 선언) 와rv_check_rvfuns디버그 invariant에서 검증. 검사기 는RV_fun[i].recv_index == i가 모든 엔트리에 성립하는지 확인한다. 즉 순서를 바꾸거나 빠뜨리면 시작 시점에 잡힌다. -
Parallel redo는 트랜잭션이 아니라 VPID로 디스패치한다.
log_recovery_redo_parallel.cpp(30 KB) 의 존재와 ARIES의 per-page LSN 순서 제약으로부터 추론. buffer manager의 페이지 fix가 자연스러운 직렬화 — 두 worker가 같은 페이지를 동시에 fix할 수 없으니 같은 페이지를 만지는 작업은 자동으로 순서화 된다. -
같은 redo 디스패처가 충돌 복구와 페이지 서버 복제 양쪽에 쓰인다.
log_recovery_redo.hpp:638-643의 코멘트에서 검증 — “perf data for actually calling the log redo function; it is relevant in two contexts: log recovery redo after a crash (either synchronously or using the parallel infrastructure); log replication on the page server”.
미해결 질문
섹션 제목: “미해결 질문”-
Parallel-redo worker 풀 크기. 설정 파라미터 이름과 기본값이 이번 패스에서는 위치를 잡히지 않았다. 추적 경로 —
log_recovery_redo_parallel.cpp의 생성자를 읽고system_parameter.{c,h}에서PRM_ID_LOG_RECOVERY_*파라 미터를 검색. -
체크포인트 빈도 knob.
LOG_GLOBAL::chkpt_every_npages는 존재하지만, 그 값이 어디서 서버 파라미터로 바인딩되는지 추적되지 않았다. 추적 경로 —chkpt_every_npageswriter를 검색. -
체크포인트와 충돌이 겹쳤을 때의 동작.
LOG_START_CHKPT와LOG_END_CHKPT사이 에 충돌이 일어나면 끝 레코드가 없다. analysis는 어떻게 동작하는가? 부분 체크포인트를 건너 뛰고 이전 것을 사용하는가, 아니면 시작 레코드를 그대로 복구 경계로 삼는가? 추적 경로 —log_rv_analysis_record의LOG_START_CHKPT와LOG_END_CHKPTarm을 추적. -
In-doubt 2PC 트랜잭션 복구. 다섯 번째 phase
LOG_RECOVERY_FINISH_2PC_PHASE가log_impl.h:631에 명명 되어 있지만, 위 sketch의log_recoverydriver에는 등장하지 않는다. 어디서 호출되는가? 추적 경로 —LOG_RECOVERY_FINISH_2PC_PHASEwriter를 검색하고cubrid-2pc.md와 cross-reference. -
페이지 서버 복제 경로와의 상호작용. redo 디스패처가 페이지 서버 복제와 공유된다. 그러나 복구와 복제 사이의 책임 분담이 추적되지 않았다. 추적 경로 —
log_recovery.c바깥 에서log_rv_redo_record_sync호출자를 검색. -
복구 동안의 TDE-encrypted 로그 페이지. redo 경로는 적용 전에 복호화해야 한다. 정확한 자리는 어디인가 —
log_reader::fetch_page_with_buffer안인가, 그 다음 단계의 디스패처 안인가? 추적 경로 —log_reader.cpp를 읽고tde_decrypt호출을 검색.
CUBRID 너머 — 비교 설계와 연구 프론티어
섹션 제목: “CUBRID 너머 — 비교 설계와 연구 프론티어”분석이 아닌 포인터(pointers).
-
PostgreSQL 복구 (
xlog.c) — analysis와 redo를 결합한 단일 패스 설계. loser undo가 불필요한 이유는 PostgreSQL의 트랜잭션이 MVCC로 버전 관리되고 commit된 상태가 inline 인코딩 되기 때문이다. CUBRID이 세 패스 모델을 유지하는 이유 는 heap 측 undo 레코드 (예 — file-allocation rollback) 가 MVCC 버전으로 표현될 수 없기 때문이다. -
InnoDB 복구 (
recv_recovery_*) — 두 패스 — scan + redo. rollback은 별도 undo 패스가 아니라 백그라운드purge가 처리 한다.mtr_tmini-transaction이 CUBRID 시스템 op과 거의 같은 atomic 그룹 역할을 한다. -
ARIES original (Mohan 외, TODS 17.1, 1992) — 표준 모델. CUBRID의 CLR 의미론, fuzzy 체크포인트, 세 패스 재시작은 충실한 구현이다. parallel-redo 와
log_rv_redo_record_sync<T>템플 릿은 ARIES가 상정하지 않은 현대적 추가다. -
Silo 복구 (Tu 외, SOSP 2013) — epoch별로 commit을 묶고 per-epoch 로그 범위를 LSN 순서 없이 replay한다. CUBRID의 per-page LSN 순서는 Silo가 의도적으로 포기하는 부분이다. 나란히 비교하면 병렬성을 위해 무엇을 희생하는지가 분명해진다.
-
Aurora의 offload-WAL 복구 (Verbitski 외, SIGMOD 2017) — 복구가 컴퓨트 노드가 아니라 스토리지 계층에서 일어난다. 그래서 컴퓨트 노드의 재시작이 빠르다 (로그 스캔이 없다). CUBRID은 프로세스 로컬이라 이는 구조적 대비에 가깝다.
-
SI Serializability 하의 복구 (Cahill, Ports 외) — SERIALIZABLE 워크로드에서는 복구가 술어-락 상태를 다시 세워야 한다. CUBRID의 SERIALIZABLE은 복구 매니저가 아니라 lock 매니저 에 의존하므로, 이는 기능 격차라기보다 비-이슈에 가깝다는 점이 다. PG SSI의 복구 측과 비교하면 그 차이가 문서화될 것이다.
원본 분석 (raw/code-analysis/cubrid/storage/recovery_manager/)
섹션 제목: “원본 분석 (raw/code-analysis/cubrid/storage/recovery_manager/)”Recovery_manager_v0.6.pptxrecovery manager_v0.2.pdfrecovery manager_v0.2.docxlog_manager_v0.3.pptx— 같은 폴더에 있지만, 그 내용은 로그 쪽 (cubrid-log-manager.md가 다룬다).
교재 챕터 (knowledge/research/dbms-general/)
섹션 제목: “교재 챕터 (knowledge/research/dbms-general/)”- Database Internals (Petrov), 5장 §ARIES, §“Recovery Algorithm”.
- Mohan, Haderle, Lindsay, Pirahesh, Schwarz, ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging, TODS 17.1, 1992.
CUBRID 소스 (/data/hgryoo/references/cubrid/)
섹션 제목: “CUBRID 소스 (/data/hgryoo/references/cubrid/)”src/transaction/log_recovery.{c,h}src/transaction/log_recovery_redo.{cpp,hpp}src/transaction/log_recovery_redo_parallel.{cpp,hpp}src/transaction/log_recovery_redo_perf.hppsrc/transaction/recovery.hsrc/transaction/log_page_buffer.c(체크포인트).src/transaction/log_compress.{c,h}(redo 시점 압축 해제).
이 지식 베이스의 형제 문서
섹션 제목: “이 지식 베이스의 형제 문서”knowledge/code-analysis/cubrid/cubrid-log-manager.md— 이 매니저가 읽는 로그.knowledge/code-analysis/cubrid/cubrid-transaction.md— 복구 가 다시 만들어 내는 TDES 상태.knowledge/code-analysis/cubrid/cubrid-mvcc.md— redo 시점에 MVCC 계열 레코드의 MVCCID 처리.knowledge/code-analysis/cubrid/cubrid-2pc.md—LOG_RECOVERY_FINISH_2PC_PHASEarm이 처리하는 in-doubt 진입. 같은 배치에서 진행 중.knowledge/code-analysis/cubrid/cubrid-page-buffer-manager.md— redo 패스가 복원하는 WAL 불변식의 데이터 페이지 측.