(KO) CUBRID 로그 매니저 — WAL, LSA, 그리고 append 규율
목차
학술적 배경
섹션 제목: “학술적 배경”로그 매니저가 책임지는 핵심 약속은 한 줄로 압축된다. 변경 내역을 적은 로그 레코드가 안정 저장소에 도달한 다음에야, 그 변경 이 적용된 더티 페이지가 디스크로 나갈 수 있다. 이 규칙을 write-ahead log (WAL) 프로토콜 이라 부른다. CUBRID의 로그 매니저는 그 WAL 프로토콜의 구현이다.
이 약속이 왜 중요한지는 충돌 직후의 상황을 떠올리면 분명해진다. 서버가 갑자기 멈추면 디스크에는 일부 더티 페이지만 남고, 나머지 는 사라진다. 무엇이 살아남고 무엇이 사라졌는지 엔진은 알 수 없다. 그래서 복구 매니저는 로그를 다시 읽으며 잃어버린 변경을 다시 적용 (redo) 하고 미완성 트랜잭션의 변경은 되돌린다 (undo). 이 모든 동작이 의미 있으려면 한 가지 전제가 성립해야 한다 — 디스크에 적용된 변경은 모두 로그에 먼저 기록되어 있다. WAL은 이 전제를 보장하기 위한 규율이다. Database Internals (Petrov) 의 5장 §Recovery가 이 받침대 위에 ARIES (Mohan 외, 1992)가 서 있다고 풀어 쓰는 것도 같은 이유다.
로그 자체는 무엇인가. append-only 한 논리적 시퀀스이며, 각 원소는 타입을 가진 레코드 다. 모든 레코드는 두 질문에 답할 수 있을 만큼의 정보를 담는다. “디스크의 페이지가 이런 상태일 때, 이 변경을 다시 적용하려면 무엇을 해야 하는가 (redo). 그리고 디스크 의 페이지가 이런 상태일 때, 이 변경을 되돌리려면 무엇을 해야 하는가” (undo). 이 두 동작 위에 트랜잭션 경계 (commit/abort), 시스템 경계 (start/checkpoint/end-of-log), 구조적 경계 (savepoint, system-op start/end), 그리고 로그를 외부 채널로 흘려 주는 기능 (HA 상태, 복제, CDC supplemental) 이 차곡차곡 얹힌다. 이 모든 레코드는 LSN (log sequence number) 으로 식별되는 하나의 무한 스트림을 공유한다. LSN이라는 이름이 강조하는 것은 정합성 비교의 기준점이다. 곧 두 상태가 이전 인지 이후 인지, 같음 인지를 LSN이 알려준다.
이 모델 위에서 모든 실제 엔진은 두 가지 구현 결정을 내려야 한다. 이 두 결정이 본 문서가 따라가는 골격을 만든다.
- LSN을 어떻게 이름 붙이고 레코드를 어디에 배치할 것인가.
교과서적인 답은 단조 증가하는 64비트 카운터다. 그러나 실무
에서는 그 주소를
(page_id, in-page offset)으로 분해해 두는 편이 낫다. 그래야 LSN 하나만으로 페이지를 찾아 가져올 수 있다. 이 분해는 번호 공간(소진까지의 시간) 과 지역성(레코드 하나를 가져오는 비용) 사이에서 균형을 맞춘 결과다. - 메모리에 머무는 로그를 어떻게 규율할 것인가. 가장 단순한 답은 모든 appender가 글로벌 락 아래에서 자기 레코드를 페이지 버퍼에 직접 쓰는 방식이다. 그러나 이 방식은 락 경합으로 곧 막혀 버린다. 실무 엔진은 두 단계로 쪼갠다 — 작은 mutex 아래 에서 레코드를 staging list 에 모아 두고, 단독 스레드 하나 가 그 리스트를 페이지 버퍼로 옮긴다. 그리고 언제 디스크로 force할지에 대한 윈도우 정책이 따라 붙는다 (group commit).
CUBRID은 이 두 질문에 구체적으로 답한다. 다음 절은 그 답을 이해하기 위해 필요한 공통 어휘를 먼저 정리한다.
DBMS 공통 설계 패턴
섹션 제목: “DBMS 공통 설계 패턴”WAL을 쓰는 거의 모든 엔진 — PostgreSQL, InnoDB, Oracle, SQL Server, CUBRID — 은 비슷한 한 줌의 패턴 위에 자기 구현을 얹는다. 이 패턴들은 ARIES 논문에 등장하지 않는다. 교과서와 소스 코드 사이를 메우는 공학적 어휘라는 점이 특징이다.
식별자로서의 LSN
섹션 제목: “식별자로서의 LSN”LSN은 로그 위 위치를 가리키지만, 엔진은 그 LSN을 페이지 상태에
대한 동등성 술어 로도 활용한다. 모든 더티 데이터 페이지는 자기
를 마지막으로 고친 로그 레코드의 LSN을 함께 들고 다닌다. 그래서
버퍼풀의 플러시 규칙이 단순해진다 — 데이터 페이지가 디스크로
나가기 전, 그 페이지의 LSN까지 로그가 force되어 있어야 한다는
점이다. 같은 LSN을 복구 매니저의 analysis 패스가 다시 읽으면서
이 페이지에 redo가 더 필요한가 를 판단한다. PostgreSQL은
XLogRecPtr, InnoDB은 lsn_t, CUBRID은 LOG_LSA 라 부르는데,
구조는 다르지만 역할은 같다.
타입드 union 형태의 로그 레코드
섹션 제목: “타입드 union 형태의 로그 레코드”로그 레코드의 첫 바이트는 고정 헤더다 (back-LSA, forward-LSA, trid, type). 그 뒤를 type별로 다른 페이로드 구조체가 잇는다. 타입 집합은 작고 닫혀 있다 (CUBRID 약 30개, InnoDB 약 70개). 닫혀 있는 이유는 record-type 별로 함수 포인터를 매핑하는 복구 디스패치 테이블이 가능하려면 그래야 하기 때문이다. 페이로드 자체는 거의 자기 기술적이지 않다는 점에 주의해야 한다. 곧 페이 로드를 어떻게 파싱할지는 type 필드가 알려준다.
단일-writer 파이프라인으로서의 append 버퍼
섹션 제목: “단일-writer 파이프라인으로서의 append 버퍼”여러 thread가 동시에 로그 버퍼에 쓰면 락 경합이 곧 병목이 된다. 표준적인 탈출구는 두 단계 파이프라인이다. appender들은 작은 mutex 아래에서 prior list (스테이징된 레코드의 연결 리스트) 에 자기 레코드를 단다. 그리고 단독 스레드 하나가 prior list를 처음부터 끝까지 따라 걸으며 LSN 순서대로 로그 페이지 버퍼로 복사한다. prior list의 head/tail 포인터만 prior-LSA mutex 아래에 있고, 나머지 작업 — 레코드 바이트 복사, 압축 — 은 mutex 바깥에서 일어난다. 그래서 critical section이 짧다는 점이 이 설계의 핵심 이다.
Force-at-commit 와 group commit
섹션 제목: “Force-at-commit 와 group commit”commit 로그 레코드는 클라이언트가 commit 성공 응답을 보기 전에 안정 저장소 위에 있어야 한다. 매번 fsync 하는 정책은 회전 미디어 에서 너무 비싸고, SSD에서도 여전히 부담스럽다. 그래서 group commit이 보편적으로 쓰인다 — commit 중인 트랜잭션이 자기 commit 레코드를 prior list에 단 다음, 내 LSN까지 force해 달라 고 요청하고 잠을 잔다. 드레인 스레드가 다수 waiter를 한 번의 fsync 로 묶어 처리한다. 이 윈도우의 길이가 commit 지연과 처리량 사이의 trade-off가 된다.
Active log와 archive
섹션 제목: “Active log와 archive”디스크 위 로그는 두 단계로 구성된다. 고정 크기의 active log (원형 파일 또는 작은 페이지 집합) 에 더해, 길이가 정해지지 않은 archive log volume 사슬이 따라 붙는다. archive 볼륨은 한 번 만들어지면 read-only다. archive가 필요한 이유는 두 가지다 — 미디어 복구 (백업으로부터의 재생), 그리고 과거 시점 읽기 (CDC tail, flashback). active와 archive 사이의 경계는 체크포인트가 이 LSN 이전 레코드의 redo는 더 이상 필요 없다 고 확정할 때 앞으로 움직인다.
이론 ↔ CUBRID 명칭 매핑
섹션 제목: “이론 ↔ CUBRID 명칭 매핑”| 이론적 개념 | CUBRID 명칭 |
|---|---|
| LSN — log sequence number | LOG_LSA — pageid:48 / offset:16 으로 패킹된 bit-field (log_lsa.hpp) |
| Log record header | LOG_RECORD_HEADER (log_record.hpp) |
| Log record type enum | LOG_RECTYPE — LOG_UNDOREDO_DATA 부터 LOG_SUPPLEMENTAL_INFO 까지 35개 이상 |
| Per-record 복구 함수 테이블 | LOG_RCVINDEX (recovery.h) → (undofun, redofun) in RV_fun[] |
| Page buffer 복사 전 staging 레코드 | LOG_PRIOR_NODE, LOG_PRIOR_LSA_INFO (log_append.hpp) |
| Prior-list mutex | log_prior_lsa_info::prior_lsa_mutex |
| Page buffer 로의 drain (단일 writer) | logpb_prior_lsa_append_all_list (log_page_buffer.c) |
| Append cursor + last-flushed LSA | log_append_info::nxio_lsa (atomic) + prev_lsa |
| 페이지 force-flush | logpb_flush_all_append_pages / logpb_force_flush_pages |
| Group-commit waiter | LOG_FLUSH_INFO + flush daemon 의 condition variable |
| Active log 헤더 | logical 페이지 LOGPB_HEADER_PAGE_ID = -9 의 LOG_HEADER |
| Per-page 헤더 | LOG_HDRPAGE (checksum + flags 포함) |
| Archive log 헤더 | LOG_ARV_HEADER |
| Compensation log record (CLR) | LOG_COMPENSATE + log_append_compensate |
| Postpone (commit 시 deferred 동작) | LOG_POSTPONE + LOG_RUN_POSTPONE |
| MVCC 계열 레코드 | LOG_MVCC_UNDOREDO_DATA, LOG_MVCC_UNDO_DATA, LOG_MVCC_REDO_DATA |
| CDC 보조 레코드 | LOG_SUPPLEMENTAL_INFO + SUPPLEMENT_REC_TYPE |
이 표를 읽고 다음 절로 넘어가면, 처음 보는 CUBRID 심볼이 등장 했을 때도 그것이 어떤 종류의 구조인지 미리 가늠할 수 있다.
CUBRID의 구현
섹션 제목: “CUBRID의 구현”CUBRID 로그 경로에는 네 개의 이동 부품이 있다. 모든 레코드의 이름을 부여하는 LSA 스킴, 그 주소에 들어 있는 타입드 로그 레코드, 레코드가 페이지에 닿기 전 머무는 prior list, 그리고 레코드를 디스크로 흘려 보내는 로그 페이지 버퍼와 flush daemon. 이 네 가지를 차례로 본다.
전체 구조
섹션 제목: “전체 구조”
그림 1 — 여러 트랜잭션 스레드가 prior_lsa_alloc_and_copy_data로 Prior list에 레코드를 동시에 올리고, drain 스레드가 이를 로그 페이지 버퍼로 옮기며, flush daemon이 active log 파일로 내보내는 세 계층 구조.
이 그림이 보여 주는 것은 정합성을 지키는 세 개의 경계다. 첫째, prior-list 경계. 여러 appender가 동시에 작업해도 한 mutex 아래에서 자기 노드와 리스트 tail만을 만진다. 둘째, 페이지 버퍼 경계. drain 스레드 하나가 LSN을 페이지로 옮기는 단독 writer 역할을 한다. 셋째, 디스크 경계. flush daemon 하나가 페이지를 active log 파일로 내보내는 단독 writer 역할을 한다. 각 경계가 한 가지 관심사 (레코드 순서, LSN 할당, 내구성) 만을 직렬화하기 때문에, 그 외의 작업은 병렬로 진행된다.
LSA — 로그 위 위치에 이름을 붙이기
섹션 제목: “LSA — 로그 위 위치에 이름을 붙이기”LSA는 64비트 정수에 두 정보를 함께 담는다. 위쪽 48비트는 logical
page id이고, 아래쪽 16비트는 페이지 안에서의 offset이다. CUBRID
은 LSA를 연산자가 정의된 struct로 노출하면서, C 측에서 쓸 수
있도록 매크로 shim (LSA_COPY, LSA_LT, …) 도 함께 제공한다.
// struct log_lsa — src/transaction/log_lsa.hppstruct log_lsa{ std::int64_t pageid:48; /* Log page identifier : 6 bytes */ std::int64_t offset:16; /* Offset in page : 2 bytes (defined as 16-bit INT64 for alignment) */
inline log_lsa () = default; inline constexpr log_lsa (std::int64_t log_pageid, std::int16_t log_offset);
constexpr inline bool is_null () const; constexpr inline bool is_max () const;
constexpr inline bool operator== (const log_lsa &olsa) const; inline bool operator< (const log_lsa &olsa) const; // ... condensed ...};
constexpr std::int64_t NULL_LOG_PAGEID = -1;constexpr std::int16_t NULL_LOG_OFFSET = -1;constexpr log_lsa NULL_LSA { NULL_LOG_PAGEID, NULL_LOG_OFFSET };constexpr log_lsa MAX_LSA = { /* 47-bit max */, /* 15-bit max */ };
그림 2 — 로그 위 위치에 이름 붙이기. 64비트 log_lsa 는 48비트
논리 페이지 id와 16비트 페이지 내 offset을 함께 담는다. 페이지
필드만으로도 wrap 전까지 약 500 PB의 로그 주소 공간을 주며,
offset은 정렬을 위해 부호 있는 16비트지만 실제 한도는 로그 페이지
크기다. (pageid, offset) 사전식 순서가 append 경로의 모든 단조성
검사가 기대는 비교자다.
이 정의에서 짚어 둘 점이 세 가지 있다. 첫째, 주소 공간의
크기. 48비트 pageid는 약 1.4 × 10^14 페이지에서 포화된다. 기본
db_logpagesize 가 4 KiB라고 보면, 약 500 PB에 해당하는 로그를
다 쓰고 나서야 LSN이 소진된다는 뜻이다. 곧 실무 운영 기간 안에는
신경 쓸 필요가 없다. 둘째, offset의 정렬 사연.
offset 필드는 정렬을 맞추기 위해 의도적으로 int16_t 가 아니라
int64_t:16 으로 선언되어 있다. 이는 헤더의 코멘트에도 명시되어
있는 사항이다. 그리고 offset의 최댓값은 INT16_MAX 가 아니라
한 로그 페이지의 데이터 영역 크기가 결정한다. 셋째, null 처리
의 미묘함. NULL_LSA 는 (-1, -1) 이지만, is_null() 검사는
pageid == -1 만 본다. 반면 set_null() 은 두 필드를 모두 -1로
쓴다. 그 이유는 헤더 코멘트가 직접 알려준다 — 한 필드만 초기화
하면 valgrind가 “conditional jump or move on uninitialized value”
경고를 띄우기 때문이다.
비교 연산은 (pageid, offset) 의 사전식이다. 이 비교가 prior
list와 페이지 버퍼 drain이 단조 증가를 보장하기 위해 의지하는
동작이다.
Log record — 헤더와 타입드 페이로드
섹션 제목: “Log record — 헤더와 타입드 페이로드”모든 레코드는 LOG_RECORD_HEADER 로 시작한다. 그 바로 뒤에 type
별로 다른 헤더 struct가 따라 붙고, 다시 그 뒤에 0개 이상의 데이
터 버퍼 (undo 이미지, redo 이미지, 키, OID 등) 가 따라 붙는다.
// LOG_RECORD_HEADER and the record-type enum — src/transaction/log_record.hppstruct log_rec_header{ LOG_LSA prev_tranlsa; /* Address of previous log record for the same transaction */ LOG_LSA back_lsa; /* Backward log address */ LOG_LSA forw_lsa; /* Forward log address */ TRANID trid; /* Transaction identifier */ LOG_RECTYPE type; /* Log record type */};
enum log_rectype{ LOG_SMALLER_LOGREC_TYPE = 0, /* lower bound check */ LOG_UNDOREDO_DATA = 2, /* an undo and redo data record */ LOG_UNDO_DATA = 3, LOG_REDO_DATA = 4, LOG_DBEXTERN_REDO_DATA = 5, LOG_POSTPONE = 6, LOG_RUN_POSTPONE = 7, LOG_COMPENSATE = 8, /* CLR — compensate an undone undo */ LOG_COMMIT_WITH_POSTPONE = 14, LOG_COMMIT = 17, LOG_SYSOP_START_POSTPONE = 18, LOG_SYSOP_END = 20, /* nested top-op end (commit / abort / logical) */ LOG_ABORT = 22, LOG_START_CHKPT = 25, LOG_END_CHKPT = 26, LOG_SAVEPOINT = 27, LOG_2PC_PREPARE = 28, /* 2PC voted yes */ /* LOG_2PC_START / COMMIT_DECISION / ABORT_DECISION / INFORM / RECV_ACK ... */ LOG_END_OF_LOG = 35, LOG_DUMMY_HEAD_POSTPONE = 36, /* no-op markers */ LOG_DUMMY_CRASH_RECOVERY = 37, LOG_REPLICATION_DATA = 39, LOG_REPLICATION_STATEMENT = 40, LOG_DIFF_UNDOREDO_DATA = 43, /* diff undo+redo to save space */ LOG_DUMMY_HA_SERVER_STATE = 44, LOG_DUMMY_OVF_RECORD = 45, /* overflow-record marker */ LOG_MVCC_UNDOREDO_DATA = 46, /* MVCC variant: carries MVCCID + vacuum info */ LOG_MVCC_UNDO_DATA = 47, LOG_MVCC_REDO_DATA = 48, LOG_MVCC_DIFF_UNDOREDO_DATA = 49, LOG_SYSOP_ATOMIC_START = 50, LOG_DUMMY_GENERIC = 51, /* "ridiculous, but flush needs it" — comment in header */ LOG_SUPPLEMENTAL_INFO = 52, /* CDC supplemental: tran user, DDL, undo/redo LSA, raw image */ LOG_LARGER_LOGREC_TYPE,};헤더에 LSA가 세 개나 들어 있는 이유는 ARIES가 복구 시점에 그 셋
을 모두 필요로 하기 때문이다. 첫 번째 prev_tranlsa 는 같은
트랜잭션에 속한 레코드들을 사슬로 잇는다. 그래서 rollback 패스가
트랜잭션의 tail에서 시작해 이 사슬을 거꾸로 따라 갈 수 있다는
점이다. 두 번째 back_lsa 와 세 번째 forw_lsa 는 레코드들을
로그 위 물리 순서로 잇는다. analysis 패스와 redo 패스가 매번
페이지 헤더를 다시 읽지 않고도 앞으로 스캔할 수 있는 것은 이
사슬 덕분이다.
MVCC 계열 레코드는 추가로 MVCCID와 LOG_VACUUM_INFO
(prev_mvcc_op_log_lsa + vfid) 를 담는다. 이 두 정보가 vacuum
서브시스템이 전체 로그를 다시 파싱하지 않고도 MVCC 연산만 따라
걸을 수 있게 해 준다.
타입 집합 자체는 의도적으로 append-only 설계다. 옛 코드를 비활성
화한 #if 0 블록 (LOG_CLIENT_NAME = 1, LOG_LCOMPENSATE = 9,
LOG_UNLOCK_COMMIT = 41 등) 이 번호 구멍으로 남아 있는 것은 그
때문이다. 옛 릴리스에서 만든 바이너리 로그를 새 빌드도 그대로
파싱할 수 있어야 한다는 호환성 약속을 지키기 위한 결정이다.

그림 3 — 한 레코드와 그 링크. 각 레코드는 고정
LOG_RECORD_HEADER, 그 뒤 type별 헤더, 그 뒤 0개 이상의 데이터
버퍼다. 헤더의 세 LSA가 독립된 두 사슬을 만든다. back_lsa /
forw_lsa 는 모든 레코드를 물리 로그 순서로 엮어 analysis·redo
패스가 앞으로 스캔하게 하고, prev_tranlsa(굵은 화살표)는 한
트랜잭션의 레코드만 엮는다 — trid 9 를 건너뛰어 trid 7 의 두
레코드를 잇는 점에 주목하라. 이것이 rollback 시 undo 패스가
거꾸로 따라 걷는 사슬이다.
헤더의 type 태그가 뒤따르는 페이로드 모양을 작은 닫힌 집합에서 고른다. ~35개 상수를 역할별로 묶으면 복구 dispatch 테이블이 기대는 union이 한눈에 보인다:

그림 4 — 레코드 타입 분류. enum은 하나의 평평한 닫힌 집합이지만
모든 상수는 일곱 역할 중 하나에 속한다. 데이터/복구 계열이 hot
path(undo, redo, CLR, postpone)이고, MVCC 계열은 추가 MVCCID +
vacuum 링크를 담으며, 복제/CDC 계열은 cubrid-cdc.md·
cubrid-ha-replication.md 가 다루는 out-of-band 채널이다. dummy
마커는 flush·복구 기계가 기대는 no-op이다.
짚을 만한 구체적인 union으로 LOG_REC_SYSOP_END 가 있다. 시스템
op (서브트랜잭션 단위의 복구) 가 끝날 때 기록되는 레코드다.
// LOG_REC_SYSOP_END — src/transaction/log_record.hppstruct log_rec_sysop_end{ LOG_LSA lastparent_lsa; /* last address before the top action */ LOG_LSA prv_topresult_lsa; /* previous top action's end LSA */ LOG_SYSOP_END_TYPE type; /* COMMIT | ABORT | LOGICAL_UNDO | LOGICAL_MVCC_UNDO | LOGICAL_COMPENSATE | LOGICAL_RUN_POSTPONE */ const VFID *vfid; union { LOG_REC_UNDO undo; /* logical undo */ LOG_REC_MVCC_UNDO mvcc_undo; /* logical MVCC undo */ LOG_LSA compensate_lsa; /* logical compensate */ struct { LOG_LSA postpone_lsa; bool is_sysop_postpone; } run_postpone; };};CUBRID에서 system op 은 엔진이 내부적으로 사용하는 nested 트랜잭션이다. 인덱스 split, heap-overflow 할당, 그리고 여러 페이지를 함께 만지면서 한 그룹으로만 atomic이어야 하는 다른 연산들에서 쓰인다. union이 어떤 arm을 쓰는지는 type 상수가 정한다. logical-undo 이미지는 시스템 op의 물리 변경을 거꾸로 재생하지 않고도 그 op 전체를 뒤집을 수 있게 해 준다는 점이 이런 구조의 장점이다. compensate_lsa 와 postpone_lsa 는 각각 되돌려진 시스템 op가 깨끗한 흔적을 남긴다, “충돌로 멈춘 postpone이 재개될 수 있다” 라는 시나리오를 위해 존재한다.

그림 5 — 시스템 op 종료 레코드. 시스템 op은 트랜잭션의
topops.stack[] 에 중첩되고, 가장 안쪽 것이 끝나면 type 이
union을 구분하는 LOG_REC_SYSOP_END 를 발행한다. 평범한
COMMIT/ABORT 는 추가 페이로드가 없지만, 네 logical 변종은 각각
복구가 여러 페이지 연산(인덱스 split, overflow 확장)을 물리 변경
역재생이 아니라 한 atomic 단위로 되돌리는 데 필요한 LSA나 undo
이미지를 정확히 담는다.
Prior list — 페이지 버퍼 이전의 staging
섹션 제목: “Prior list — 페이지 버퍼 이전의 staging”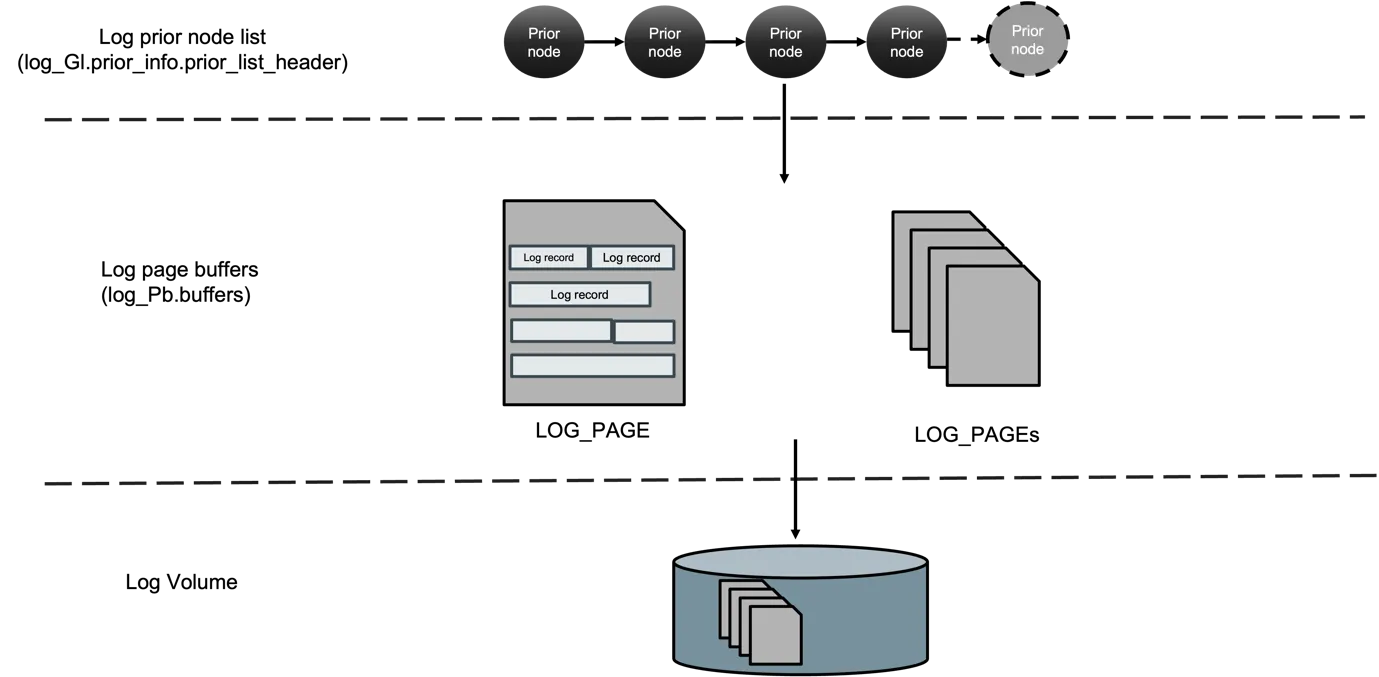
그림 6 — 로그 레코드 한 건이 거치는 세 저장 계층을 한 화면에 보여
준다는 점이다. 위쪽에서 트랜잭션이 LOG_PRIOR_NODE 를 만들어
log_Gl.prior_info.prior_list_header 끝에 매단다. drain 스레드가
이 노드를 log_Pb.buffers — LOG_PAGE 프레임의 메모리 링버퍼 —
로 옮겨 적고, flush 데몬이 그 페이지를 active 로그 볼륨에 기록한
다. 점선으로 나뉜 세 영역이 본문에서 다룰 세 직렬화 지점에 정확
히 대응한다. 위에서 prior-list 뮤텍스, 가운데에서 단일 writer
drain, 아래에서 단일 writer flush. (출처: log manager_v0.5.docx,
prior-list 개요 그림.)
트랜잭션이 undo+redo 데이터 레코드를 로그하려고 하면, 가장 먼저
호출되는 함수가 prior_lsa_alloc_and_copy_data
(log_append.cpp:273) 다. 이 함수는 LOG_PRIOR_NODE 를 하나
할당한 뒤, 호출자가 넘긴 버퍼로부터 헤더와 type별 필드를 채워
넣는다. 이 시점의 노드는 아직 LSA를 받지 않은 상태다.
// LOG_PRIOR_NODE / LOG_PRIOR_LSA_INFO — src/transaction/log_append.hppstruct log_prior_node{ LOG_RECORD_HEADER log_header; LOG_LSA start_lsa; /* assertion-only — assigned on attach */ bool tde_encrypted;
int data_header_length; char *data_header;
int ulength; /* undo length */ char *udata; int rlength; /* redo length */ char *rdata;
LOG_PRIOR_NODE *next;};
struct log_prior_lsa_info{ LOG_LSA prior_lsa; /* next LSA to assign */ LOG_LSA prev_lsa; /* last attached node's LSA */
LOG_PRIOR_NODE *prior_list_header; LOG_PRIOR_NODE *prior_list_tail; INT64 list_size; /* bytes */ LOG_PRIOR_NODE *prior_flush_list_header;
std::mutex prior_lsa_mutex;};다음으로 트랜잭션이 호출하는 함수가 prior_lsa_next_record
(1553) 다. 이미 prior mutex를 잡고 있다면 그 변종인
prior_lsa_next_record_with_lock (1559) 를 호출한다. 이 호출이
하는 일이 두 가지다. 첫째, 노드의 start_lsa 에 현재 prior_lsa
값을 할당한다. 둘째, 노드를 prior_list의 tail에 매단다. 이 두 동
작이 모두 mutex 안에서 함께 일어난다는 점이 핵심이다. 그래서
함수가 반환하는 LSA는 트랜잭션이 가진 이걸 로그에 적었다 라는
약속이 된다.
// prior_lsa_next_record_internal — src/transaction/log_append.cppLOG_LSAprior_lsa_next_record_internal (THREAD_ENTRY *thread_p, LOG_PRIOR_NODE *node, LOG_TDES *tdes, int with_lock){ // ... condensed ... if (with_lock == LOG_PRIOR_LSA_WITHOUT_LOCK) log_Gl.prior_info.prior_lsa_mutex.lock ();
start_lsa = log_Gl.prior_info.prior_lsa; prior_lsa_start_append (thread_p, node, tdes); /* assigns node->start_lsa, bumps prior_lsa by record size */ prior_lsa_end_append (thread_p, node); /* attaches to prior_list tail */
if (with_lock == LOG_PRIOR_LSA_WITHOUT_LOCK) log_Gl.prior_info.prior_lsa_mutex.unlock ();
return start_lsa;}이 규율에서 두 가지 속성이 자연스럽게 따라 나온다. 첫째, 짧은
critical section. mutex가 잡히는 구간은 “어디에 둘지 정한다 +
실제로 매단다” 라는 두 동작뿐이며 둘 다 O(1)이다. 호출자 버퍼
로부터의 실제 레코드 복사는 더 앞서 prior_lsa_alloc_and_copy_data
안에서, 곧 mutex 바깥에서 이미 끝나 있다. 둘째, 전체 순서가
보장되는 LSA. 부착이 LSA 할당과 함께 일어나므로, 한 트랜잭션의
LSA는 다른 모든 트랜잭션의 LSA를 단조 비교가 가능하다. “내가
LSA X에 append했는데 옆 사람이 X+δ에서 먼저 commit했다” 같은
race가 원천적으로 존재할 수 없다는 뜻이다.
Page buffer drain — 단일 writer로의 LSN 순서 옮기기
섹션 제목: “Page buffer drain — 단일 writer로의 LSN 순서 옮기기”다음 단계는 drain이다. logpb_prior_lsa_append_all_list
(log_page_buffer.c:3106) 가 그 일을 한다. 호출 주체는 로그
critical section, flush daemon, 그리고 “내 레코드가 페이지 버퍼
까지는 닿아 있어야 한다” 가 필요한 모든 경로다. 이 함수가 하는
일은 prior list를 따라 걸으며 각 노드를 적절한 LOG_PAGE 안에
복사해 넣는 것이다. 페이지가 부족하면 logpb_initialize_pool
(553) 이 만들어 둔 페이지 버퍼 풀에서 새 페이지를 할당해 가져
온다.
// logpb_prior_lsa_append_all_list — src/transaction/log_page_buffer.cintlogpb_prior_lsa_append_all_list (THREAD_ENTRY *thread_p){ // ... condensed ... /* Detach the prior list under the mutex; release it; copy outside. */ std::unique_lock<std::mutex> lk (log_Gl.prior_info.prior_lsa_mutex); LOG_PRIOR_NODE *first = log_Gl.prior_info.prior_list_header; log_Gl.prior_info.prior_list_header = NULL; log_Gl.prior_info.prior_list_tail = NULL; log_Gl.prior_info.list_size = 0; lk.unlock ();
for (LOG_PRIOR_NODE *node = first; node != NULL; node = node->next) { logpb_append_next_record (thread_p, node); if (logpb_is_page_in_archive (...)) /* page boundary crossing */ logpb_next_append_page (thread_p, ...); logpb_free_node (node); } return NO_ERROR;}코드에서 직접 드러나는 두 속성이 있다. 첫째, drain은 페이지
버퍼로의 단독 writer다. prior-list mutex는 appender 끼리 의
충돌만을, drain mutex는 appender 와 drain 사이의 충돌만을
직렬화한다. 두 mutex가 다른 관심사를 분리한다는 뜻이다. 둘째,
페이지 경계는 별도 함수가 책임진다. logpb_next_append_page
(2630) 가 현재 페이지를 dirty로 표시하고, 새로운 logical 페이지
를 할당하고, 그 physical descriptor를 결합한다.
Flush — 내구성을 만드는 마지막 단계
섹션 제목: “Flush — 내구성을 만드는 마지막 단계”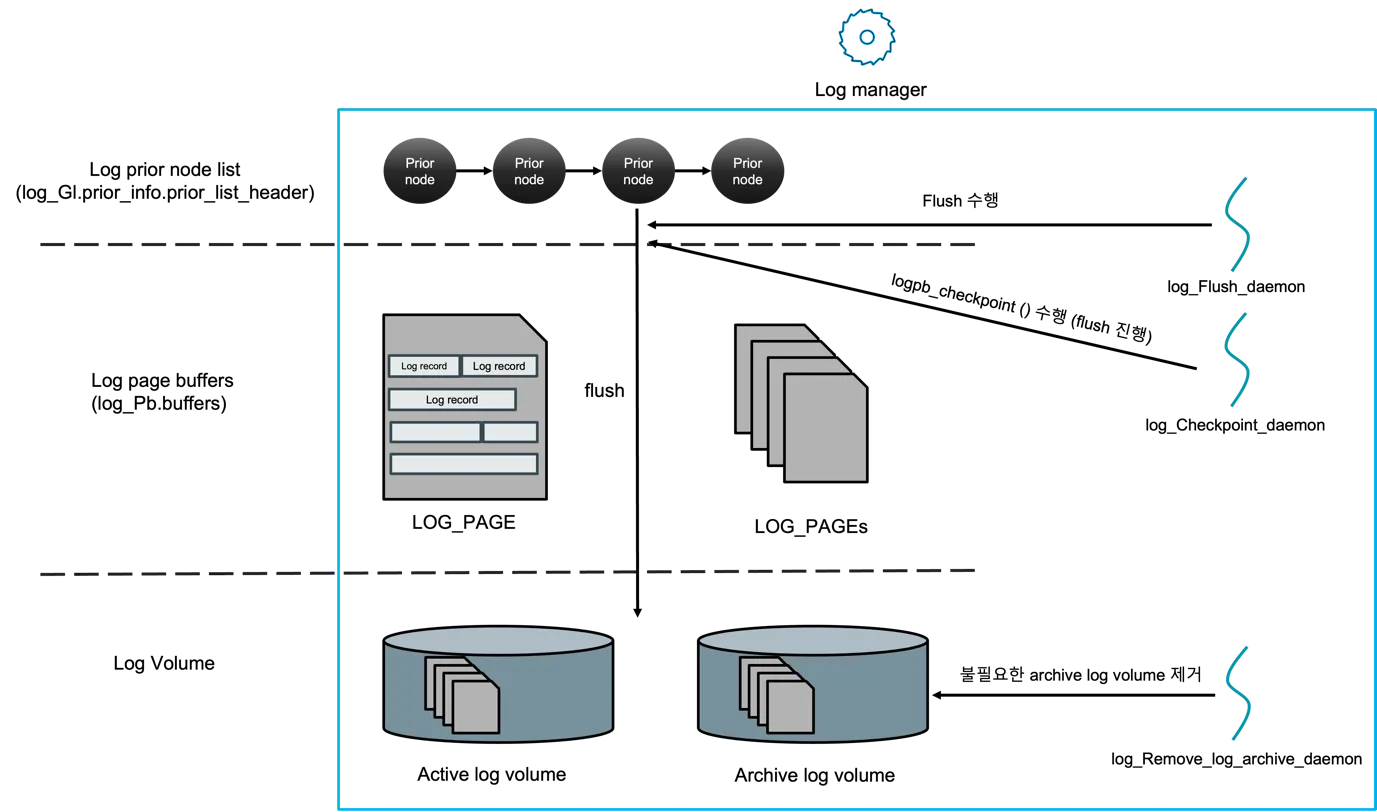
그림 7 — 그림 6 의 세 계층을 그대로 두고, 로그 매니저의 세 데몬
이 어디에 붙는지를 표시했다. log_Flush_daemon 이 active 로그 볼륨
으로 실제 페이지를 쓰는 유일한 주체다. log_Checkpoint_daemon 이
주기적으로 logpb_checkpoint 를 불러서, 다음 분석(analysis) 패스가
출발할 LSA 를 앞으로 당겨준다. log_Remove_log_archive_daemon 은
HA 복제본이나 백업이 더 이상 참조하지 않는 archive 볼륨을 회수한
다. 디스크에 쓰는 일은 모두 데몬이 맡고, append 호출자는 I/O 를
직접 기다리지 않는다는 점이 핵심이다. (출처: log manager_v0.5.docx,
로그 매니저 + 데몬 그림.)
flush가 마지막 단계다. logpb_flush_all_append_pages (3232) 가
실무 일꾼이다. 이 함수가 페이지 버퍼의 dirty 리스트를 따라 걸으
며, file_io 서브시스템으로 각 페이지를 active log 파일에 쓴
뒤, log_append_info::nxio_lsa 를 갱신한다. nxio_lsa 는 “이
LSN 아래의 모든 것이 안정 저장소 위에 있다” 라는 워터마크다.
// log_append_info — src/transaction/log_append.hppstruct log_append_info{ int vdes; /* volume descriptor of active log */ std::atomic<LOG_LSA> nxio_lsa; /* lowest LSA not yet on disk */ LOG_LSA prev_lsa; /* last appended record */ LOG_PAGE *log_pgptr; /* the currently fixed log page */ bool appending_page_tde_encrypted;};force-flush 경로는 logpb_force_flush_pages (4096) 다. 이 함수가
호출되는 시점은 commit 시점이다. HA 구성이 강제하면 log_commit
이 직접 호출하기도 하고, 그 외 경로에서는 flush daemon으로
간접적으로 호출된다. flush daemon (log_wakeup_log_flush_daemon
— log_manager.h 에 선언) 은 condition variable에서 잠을 자고
있으며, 디스크 도달을 보장받고 싶은 appender들이 그 daemon을
깨운다. 깨어난 waiter는 nxio_lsa >= my_commit_lsa 인지 확인하고
참이 아니면 다시 잠을 잔다. 이 패턴이 group-commit 구현이다 —
다수의 waiter, 한 번의 fsync.
이 구조에 대응하는 read-측 보장이 WAL 불변식이다. 데이터 페이지
flush (pgbuf_flush_page_*) 는 페이지 쓰기를 발행하기 전에
nxio_lsa >= page->lsa 를 보장해야 한다. CUBRID은 이 검사를
pgbuf_flush_check_log_lsa 에서 강제한다. 필요하면 그 함수가
다시 로그 매니저를 호출해 force를 트리거한다 (데이터 페이지 측의
자세한 이야기는 cubrid-page-buffer-manager.md 에서 다룬다).
압축, archiving, 그리고 active-log 헤더
섹션 제목: “압축, archiving, 그리고 active-log 헤더”hot append 경로 너머에는 로그 매니저가 소유하지만 매 레코드 경로 에는 등장하지 않는, 그러나 운영에 직접 영향을 주는 세 가지 기계 가 더 있다.
압축. log_Zip_min_size_to_compress 보다 큰 레코드는 zlib으로
in-place로 압축된다. 압축이 일어나는 자리는 prior_lsa_alloc_and_copy_data
이며, 이때 thread 별 LOG_ZIP 컨텍스트
(log_compress.c, log_append_get_zip_undo /
log_append_get_zip_redo) 를 사용한다. 글로벌 토글은
log_Zip_support 다. 한 가지 짚어 둘 점은 압축 경계가 페이지가
아니라 prior-list 노드다. 곧 레코드의 압축된 형태는
페이지 경계를 가로질러도 동일하게 유지되며, 복구 측은 같은
컨텍스트로 압축을 풀 수 있다.
Archiving. active log는 고정 크기다. 가득 차면 가장 오래된
페이지가 archive 볼륨으로 롤오버된다. LOG_ARV_HEADER 가 각
archive 파일을 식별하며 (log_storage.hpp), LOG_HEADER 안의
nxarv_pageid 와 nxarv_phy_pageid 가 archive할 다음 페이지를
추적한다. archive 제거 daemon (log_wakeup_remove_log_archive_daemon)
은 두 조건이 모두 성립할 때만 archive를 삭제한다 — 체크포인트
LSA가 그 archive를 지나갔고, 어떤 복제 / CDC reader도 그 archive
를 더 이상 필요로 하지 않을 때.
Active-log 헤더. logical 페이지 LOGPB_HEADER_PAGE_ID = -9
에 사는 LOG_HEADER 가 부트스트랩 구조다. 이 헤더는 데이터베이
스 생성 시각, 페이지 크기, 다음 트랜잭션 ID, 다음 MVCC ID, append
LSA, 체크포인트 LSA, archive 부기, HA 상태, 백업 LSA, vacuum
부기를 모두 담는다. 충돌 경계를 넘어 로그가 어디까지 와 있는가
를 알려 주는 단일 진실의 원천이라는 점이 이 헤더의 역할이다.
헤더의 eof_lsa 는 LOG_END_OF_LOG 의 LSA이며, 복구의 analysis
패스가 합법적인 로그의 끝을 찾을 때 이 값을 기준으로 삼는다.

그림 8 — 2계층 on-disk 로그. active 볼륨은 고정 크기 원형
파일이고, logical 페이지 -9 가 LOG_HEADER — 모든 archive에
복사되어 어느 볼륨에서든 emergency 복구를 시작할 수 있게 하는
부트스트랩 레코드다. active log가 차면 가장 오래된 페이지가 새
불변 archive 볼륨으로 롤오버된다(nxarv_pageid 가 경계 추적).
archive 제거 daemon은 체크포인트 LSA가 그 archive를 지났고
그리고 어떤 CDC reader·HA 복제본·백업도 그 페이지 범위를 더는
필요로 하지 않을 때에만 그 archive를 삭제한다.
나머지 엔진이 보는 append API
섹션 제목: “나머지 엔진이 보는 append API”로그 매니저 바깥에서 보면 거의 모든 사용은 세 가지 진입점 패밀리로 처리된다.
// Append API surface — log_manager.h (excerpt)extern void log_append_undoredo_data (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int undo_length, int redo_length, const void *undo_data, const void *redo_data);extern void log_append_undo_data (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int length, const void *data);extern void log_append_redo_data (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int length, const void *data);extern void log_append_compensate (THREAD_ENTRY *, LOG_RCVINDEX, const VPID *, PGLENGTH, PAGE_PTR, int length, const void *data, LOG_TDES *);extern void log_append_postpone (THREAD_ENTRY *, LOG_RCVINDEX, LOG_DATA_ADDR *, int length, const void *data);extern LOG_LSA *log_append_savepoint (THREAD_ENTRY *, const char *savept_name);
extern TRAN_STATE log_commit (THREAD_ENTRY *, int tran_index, bool retain_lock);extern TRAN_STATE log_abort (THREAD_ENTRY *, int tran_index);
extern void log_sysop_start (THREAD_ENTRY *);extern void log_sysop_commit (THREAD_ENTRY *);extern void log_sysop_abort (THREAD_ENTRY *);extern void log_sysop_end_logical_undo (THREAD_ENTRY *, LOG_RCVINDEX, const VFID *, int undo_size, const char *undo_data);LOG_DATA_ADDR (log_append.hpp) 는 페이지 포인터, 파일 id,
in-page offset 을 한 묶음으로 들고 다닌다. 복구 측이 redo 또는
undo를 시도할 때 필요한 주소 정보다. LOG_RCVINDEX 는 글로벌
RV_fun[] 배열 (recovery.h) 의 디스패치 키다. 각 record kind를
redo 함수와 undo 함수를 짝지어 둔 표라고 보면 된다. append
API의 일은 호출자가 넘긴 (rcvindex, addr, payload) 튜플을 알맞은
LOG_RECTYPE 의 LOG_PRIOR_NODE 로 만들어 prior list에 매다는
것이다.
레코드 라이프사이클, 끝에서 끝까지
섹션 제목: “레코드 라이프사이클, 끝에서 끝까지”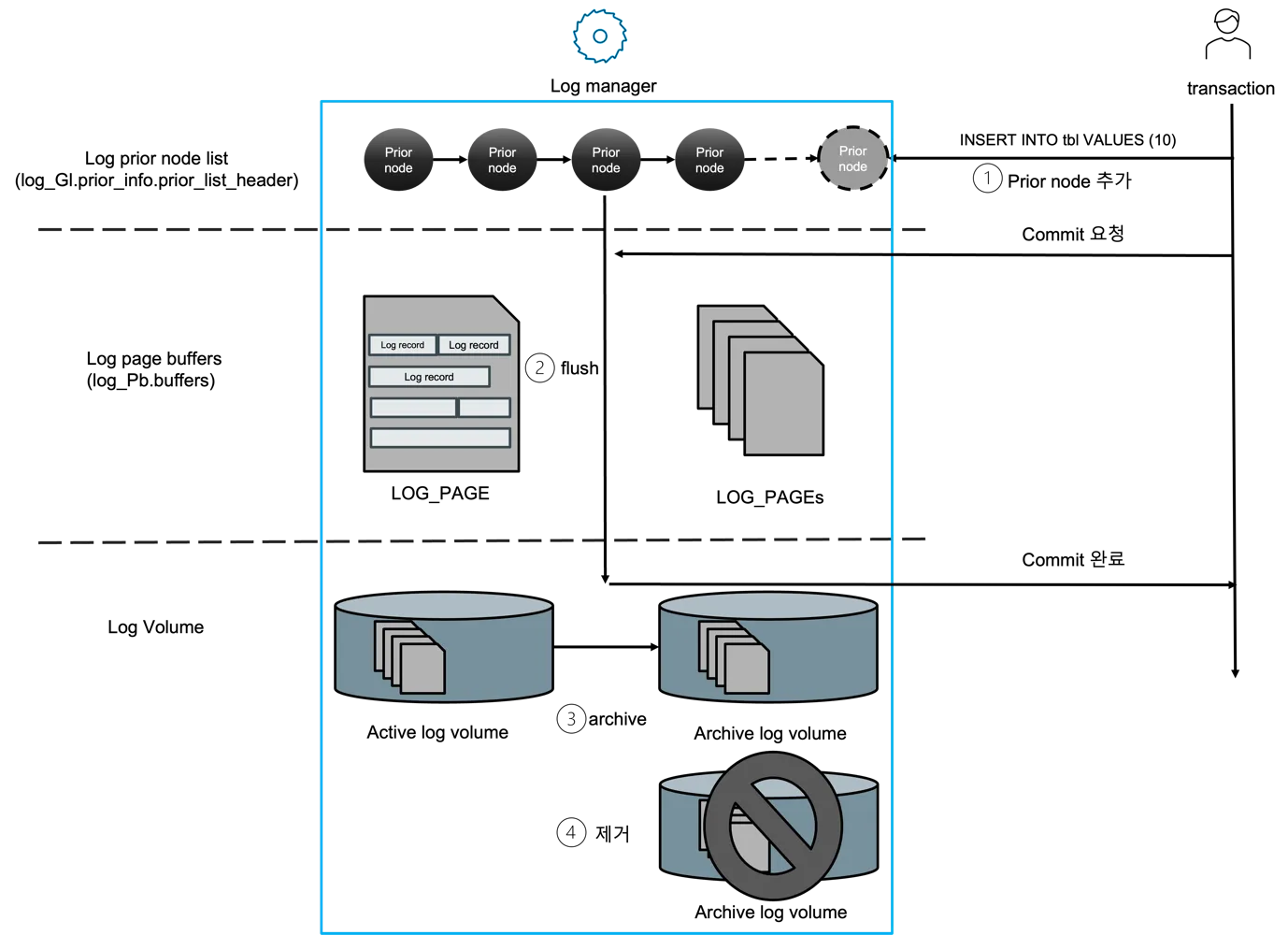
그림 9 — INSERT INTO tbl VALUES (10) 와 COMMIT 한 건을, 원본
deck 의 네 단계 번호를 그대로 살려서 보여준 그림이다. ① 트랜잭션
이 prior_lsa_alloc_and_copy_data 를 호출해 새 prior 노드를 만들
어 매단다. ② drain 이 그 노드를 LOG_PAGE 로 복사하면 flush 데몬
이 그 페이지를 active 로그에 기록한다. ③ active 로그가 충분히 차
면 archive 볼륨으로 굴러간다. ④ 어떤 replica 도 더 이상 읽지 않는
archive 는 정리된다. ① 과 ② 는 commit 호출 안에서 일어난다는 점
이 중요하다. 호출자가 nxio_lsa 가 자기 LSA 를 따라잡을 때까지 기
다리기 때문이다. ③ 과 ④ 는 백그라운드다. 아래의 시퀀스 다이어그램
은 같은 흐름을 함수 호출 단계로 풀어 보여준다. (출처:
log manager_v0.5.docx, commit 흐름 그림.)

그림 10 — log_append_undoredo_data 호출부터 nxio_lsa가 commit LSA를 넘어 committer 스레드가 깨어나기까지의 단계별 시퀀스. 트랜잭션 스레드는 디스크 I/O 없이 prior-list 부착만으로 복귀하고, flush는 daemon이 비동기로 처리한다는 점이 핵심이다.
이 다이어그램이 보여 주는 두 가지 순서가 있다. 하나는 LSN 순서다. 부착 시점에 prior-list mutex가 보장하는 단조성 덕분에, 엔진이 발급한 모든 LSN은 직전 LSN보다 크다. 다른 하나는 디스크 순서다. flush 시점에 active log 볼륨으로의 단일 writer가 보장 한다. 두 순서가 항상 일치하는 이유는 drain이 노드를 prior-list 순서대로 복사하고, flush가 페이지를 page-id 순서대로 쓰기 때문이다.
소스 코드 가이드
섹션 제목: “소스 코드 가이드”anchor는 심볼명 이다. 라인 번호는 흘러간다.
헤더 & 타입
섹션 제목: “헤더 & 타입”log_lsa(log_lsa.hpp) —pageid:48 / offset:16의 LSN.LOG_RECORD_HEADER(log_record.hpp) — 모든 레코드 앞쪽의 헤더.prev_tranlsa,back_lsa,forw_lsa,trid,type를 담는다.LOG_RECTYPE(log_record.hpp) — record 종류의 닫힌 enum.LOG_PAGE/LOG_HDRPAGE/LOG_HEADER(log_storage.hpp) — 디스크상의 레이아웃.LOG_PRIOR_NODE/LOG_PRIOR_LSA_INFO(log_append.hpp) — 호출자와 페이지 버퍼 사이의 staging 레코드.log_append_info(log_append.hpp) — 글로벌 append cursor와nxio_lsa.
Prior-list (staging)
섹션 제목: “Prior-list (staging)”prior_lsa_alloc_and_copy_data(log_append.cpp) —(rcvindex, addr, undo, redo)로부터 노드를 빌드하고 필요시 zip한다.prior_lsa_alloc_and_copy_crumbs(log_append.cpp) —LOG_CRUMB데이터 조각 리스트를 받는 변종.prior_lsa_next_record_internal(log_append.cpp) — prior mutex 안에서 LSA 할당과 tail 부착을 한 묶음으로 처리.prior_lsa_start_append/prior_lsa_end_append(log_append.cpp) — 부착의 두 절반.log_append_undoredo_data와 동료들 (log_manager.c) — 나머지 엔진이 호출하는 표면.
페이지 버퍼 drain
섹션 제목: “페이지 버퍼 drain”logpb_initialize_pool(log_page_buffer.c) — 풀 초기화 (LOGPB_BUFFER_NPAGES_LOWER이상의 페이지로).logpb_prior_lsa_append_all_list(log_page_buffer.c) — prior list를 페이지 버퍼로 drain.logpb_next_append_page(log_page_buffer.c) — 페이지 경계 넘기와 dirty 표시.
Flush
섹션 제목: “Flush”logpb_flush_all_append_pages(log_page_buffer.c) — dirty 페이지를 active log에 쓰고nxio_lsa를 전진.logpb_force_flush_pages(log_page_buffer.c) — commit 요청 / HA 용 force-flush 변종.log_wakeup_log_flush_daemon(log_manager.h) — group-commit 배치를 구동하는 daemon을 깨우기.
Lifecycle
섹션 제목: “Lifecycle”log_create(log_manager.c) — 데이터베이스 init 시 active log + 헤더 생성.log_initialize(log_manager.c) — 서버 시작 시 로그 열기 / 복구.log_commit(log_manager.c) —LOG_COMMITappend, force, 락 해제.log_abort(log_manager.c) — undo 구동,LOG_ABORTappend.log_complete(log_manager.c) — 최종 상태 전이; 트랜잭션 종료 레코드 발행.log_final(log_manager.c) — 정상 종료, force,LOG_HEADER::is_shutdown = true기록.
압축 & archive
섹션 제목: “압축 & archive”log_append_init_zip/log_append_final_zip(log_append.cpp).log_append_get_zip_undo/log_append_get_zip_redo(log_append.cpp).log_wakeup_remove_log_archive_daemon(log_manager.h) — 쓸모없어진 archive 볼륨을 삭제하는 daemon.
CDC 통합 (forward 경계)
섹션 제목: “CDC 통합 (forward 경계)”cdc_*패밀리 (log_manager.h) —cdc_find_lsa,cdc_get_logitem_info,cdc_make_dml_loginfo,cdc_validate_lsa,cdc_min_log_pageid_to_keep. 이 함수들이 로그 매니저 표면에 노출된 이유는 CDC가log_reader로 로그를 앞으로 걸으며, 로그 매니저에 이 범위는 살아 있어 달라 고 부탁하는 관계이기 때문이다.
이 개정 시점의 위치 힌트 (2026-04-30)
섹션 제목: “이 개정 시점의 위치 힌트 (2026-04-30)”| 심볼 | 파일 | 라인 |
|---|---|---|
log_lsa (struct) | log_lsa.hpp | 35 |
log_rec_header | log_record.hpp | 146 |
enum log_rectype | log_record.hpp | 35 |
log_rec_sysop_end | log_record.hpp | 305 |
log_prior_node | log_append.hpp | 91 |
log_prior_lsa_info | log_append.hpp | 112 |
log_append_info | log_append.hpp | 73 |
log_header | log_storage.hpp | 113 |
log_create | log_manager.c | 791 |
log_initialize | log_manager.c | 1059 |
log_append_undoredo_data | log_manager.c | 1893 |
log_append_redo_data | log_manager.c | 2035 |
log_commit | log_manager.c | 5352 |
log_abort | log_manager.c | 5461 |
log_complete | log_manager.c | 5653 |
prior_lsa_alloc_and_copy_data | log_append.cpp | 273 |
prior_lsa_alloc_and_copy_crumbs | log_append.cpp | 410 |
prior_lsa_next_record_internal | log_append.cpp | 1357 |
prior_lsa_next_record | log_append.cpp | 1553 |
prior_lsa_start_append | log_append.cpp | 1593 |
prior_lsa_end_append | log_append.cpp | 1652 |
logpb_initialize_pool | log_page_buffer.c | 553 |
logpb_next_append_page | log_page_buffer.c | 2630 |
logpb_prior_lsa_append_all_list | log_page_buffer.c | 3106 |
logpb_flush_all_append_pages | log_page_buffer.c | 3232 |
logpb_force_flush_pages | log_page_buffer.c | 4096 |
소스 검증 (2026-04-30 기준)
섹션 제목: “소스 검증 (2026-04-30 기준)”각 항목은 현재 소스에 대한 사실이다. 원본 분석 자료를 옆에 두지 않고 읽어도 의미가 통하도록 굵은 진술이 먼저 오고, 그 진술의 근거와 부연이 그 뒤에 따라 붙는다.
검증된 사실
섹션 제목: “검증된 사실”-
LOG_LSA는int64_t위에 bit-field로 정의된 64비트 패킹 struct다 (pageid:48 / offset:16).log_lsa.hpp:35에서 검증. offset 필드는 정렬을 위해int16_t가 아니라int64_t:16으로 선언되어 있으며, 같은 헤더의 코멘트가 그 사연을 명시한다. 함의 — 단일 로그 페이지의 데이터 영역은 signed 16비트 offset이 표현 가능한 32 KiB 이내여야 한다. CUBRID의 기본db_logpagesize가 4 KiB이므로 실무상 여유는 충분하다. -
Null LSA 는
(-1, -1)이지만is_null()은pageid만 검사한다.log_lsa.hpp:97-101과 109행의set_null()에서 검증.set_null함수는 두 필드를 모두 -1로 쓰는데, 인라인 코멘트가 그 이유를 직접 알려준다 — 한 필드만 초기화하면 valgrind가 “conditional jump or move on uninitialized value” 경고를 띄우기 때문이다. -
Append 파이프라인은 두 단계다 — prior list 다음에 페이지 버퍼.
log_append.hpp(struct 정의),log_append.cpp(prior_lsa_*함수),log_page_buffer.c(logpb_prior_lsa_append_all_list) 를 차례로 읽으며 검증. appender들이 경합하는 락은 prior-list mutex (prior_lsa_mutex) 하나뿐이다. drain은 단일 writer다. -
LSA 할당은 prior-list mutex 안에서 이루어진다 —
prior_lsa_start_append가 그 일을 한다.log_append.cpp:1593에서 검증. 즉 LSA의 전체 순서는 레코드 바이트가 복사된 시점이 아니라 appender가 mutex를 잡는 순서로 결정된다. 함의 —log_append_undoredo_data가 반환 하는 LSA는 동시 appender가 많은 환경에서도 안정적인 핸들로 쓸 수 있다. -
Group commit은
nxio_lsa위에서 대기하는 waiter들을 깨우는 flush daemon으로 구현되어 있다.log_manager.h:221의log_wakeup_log_flush_daemon와log_append.hpp:76의log_append_info::nxio_lsa(atomic) 를 함께 검증. daemon의 main 루프는log_page_buffer.c의log_flush_daemon안에 있다. waiter 측은logpb_flush_all_append_pages가nxio_lsa를 전진시키는 시점에 깨어난다. -
로그 레코드는 설정된 크기 임계값을 넘으면 in-place로 zlib 압축된다.
log_append.hpp:162-165의log_append_init_zip,log_append_get_zip_undo/_redo, 그리고log_compress.c로 검증. 토글은log_Zip_support, 임계값은log_Zip_min_size_to_compress로 둘 다 글로벌이다. -
Active log 헤더는 logical 페이지 id
-9에 살며,LOGPB_HEADER_PAGE_ID상수로 하드코딩되어 있다.log_storage.hpp:51에서 검증. 같은 헤더의 코멘트에 따르면 이 페이지는 log의 active 부분에 항상 머물고, “모든 archive log에 백업된다”. 두 사실 덕분에 비상 복구 (log_restart_emergency) 가 어떤 archive로부터든 가능해진다. -
Record 타입은 릴리스를 가로질러 append-only다.
log_record.hpp:35-141에 남아 있는 obsolete 타입의#if 0블록 (LOG_CLIENT_NAME = 1,LOG_LCOMPENSATE = 9,LOG_UNLOCK_COMMIT = 41등) 을 세어 검증. 번호 구멍이 그 자리에 보존되어 있어, 옛 빌드가 만든 바이너리 로그도 새 빌드 에서 그대로 파싱 가능하다. -
MVCC 로그 레코드는
MVCCID와LOG_VACUUM_INFO를 둘 다 나른다.log_record.hpp:202-217(LOG_REC_MVCC_UNDOREDO,LOG_REC_MVCC_UNDO) 에서 검증.vacuum_info.prev_mvcc_op_log_lsa가 MVCC 연산들을 별도의 사슬로 잇기 때문에, vacuum 서브시스템 은 다른 모든 레코드를 다시 읽지 않고도 MVCC 연산만 따라 갈 수 있다. -
LOG_SUPPLEMENTAL_INFO는 카탈로그 가시 이벤트를 CDC로 내보내기 위한 채널이다.log_record.hpp:418-439의SUPPLEMENT_REC_TYPEenum과log_manager.h:171-179의log_append_supplemental_*선언으로 검증. 보조 record 타입 집합은TRAN_USER,DDL,INSERT/UPDATE/DELETE,TRIGGER_INSERT/UPDATE/DELETE를 포함한다. 이 집합이 다운 스트림 측에서 CDC 컨슈머가 역직렬화하는 집합과 정확히 같다 (cubrid-cdc.md).
미해결 질문
섹션 제목: “미해결 질문”-
Group-commit 윈도우 정책의 정확한 형태. 고정 timeout인지, waiter 수 임계값인지, 아니면 그 둘의 조합인지가 아직 분명 하지 않다. flush daemon의 wake 조건을 보면 답을 알 수 있을 것이다. 추적 경로 —
log_page_buffer.c안의 daemon 본문을 읽고 (log_flush_daemon함수 또는 thread 진입점 검색), 그 조정을 구동하는 것으로 보이는log_writer.c(76 KB) 와 상관 짓기. -
Prior-list 크기는 어떻게 묶이는가.
LOG_PRIOR_LSA_INFO::list_size는 추적되지만, 그 소비자나 트리거가 이번 패스에서는 위치를 잡히지 않았다. appender가 계속 매달기 전에 drain을 강제로 부르는 soft cap이 있는가? 추적 경로 —list_size접근을 grep으로 찾아log_append.cpp와log_page_buffer.c를 살피기. -
TDE-encrypted 로그 페이지에서 암호화가 일어나는 시점.
log_prior_node::tde_encrypted와log_append_info::appending_page_tde_encrypted가 존재 한다. 그런데 암호화가 attach 시점, drain 시점, 또는 flush 시점 중 어디에서 실제로 일어나는지는 미검증이다. 추적 경로 —log_append.cpp의prior_set_tde_encrypted,prior_is_tde_encrypted본문을 읽고tde.h와 상관 짓기. -
LOG_DUMMY_GENERIC(record type 51) 의 정확한 용도. 헤더 코멘트는 이 타입을 ridiculous, but flush needs it 이라 부른다. 어떤 invariant를 보존하기 위한 것인가? 특정 LSA에 no-op 레코드를 두어서 페이지 경계 flush를 강제하는 것인가? 추적 경로 —LOG_DUMMY_GENERIC을 발행하는 자리 를 grep으로 찾고, recovery dispatch에서 소비하는 자리가 있는지 확인. -
Active log 크기 정책.
LOG_HEADER::npages는 create 시점에 정해지지만, 운영 중 resize / rotation 정책은 헤더 에 노출되지 않는다. 설정 가능한 knob이 있는가? 추적 경로 —log_create_internal바깥에서npages에 쓰기를 하는 자리를 검색. -
CDC 보존과 archive 삭제의 동기화.
cdc_min_log_pageid_to_keep(log_manager.h:235에 선언) 가 archive-remove daemon을 게이팅한다. 그런데 CDC가 진행 하면서 그 값이 어떻게 갱신되는지, daemon이 그 값을 얼마나 자주 다시 읽는지가 아직 추적되지 않았다. 추적 경로 —log_wakeup_remove_log_archive_daemon본문을 읽고cdc_min_log_pageid_to_keep의 모든 호출자를 따라가기.
CUBRID 너머 — 비교 설계와 연구 동향
섹션 제목: “CUBRID 너머 — 비교 설계와 연구 동향”분석이 아닌 포인터(pointers). 각 항목은 후속 문서의 출발점 이며, 깊이는 의도적으로 얕다.
-
PostgreSQL XLOG —
XLogRecPtr은 평탄한 64비트 LSN으로,(timeline, segment, offset)분해는 정수 바깥에서 한다. Record 포맷은 패킹된 페이로드가 아니라 record 당 별도의 block-data 배열을 사용한다. CUBRID의 prior-list staging은 PG의 WAL insertion locks (다수, 해시) 에 깔끔하게 매핑된다. 비교를 해 보면 단일 prior mutex가 PG의 stripe된 락에 비해 어떻게 스케일하는지 답을 얻을 수 있다. -
InnoDB redo log (mtr / log_t) — staging 단위로 mini-tran saction (
mtr_t) 을 쓰고, 그 다음 단계는 고정 크기 circular log 파일과 별도의log_buf링이다. group commit은flush_loop스레드가os_event위에서 처리한다. CUBRID의LOG_RUN_POSTPONE을 InnoDB의 deferred buffer-pool 작업과 비교하면, 두 엔진이 commit 전에 디스크에 닿아 있어야 한다 라는 점을 어디서 다르게 정의하는지가 분리된다. -
ARIES original (Mohan 외, 1992) — 여기 거론한 모든 WAL 엔진을 위한 표준 모델. CUBRID의 세 LSA 헤더 (
prev_tranlsa,back_lsa,forw_lsa) 는 ARIES record 레이아웃 그대로 이며,LOG_COMPENSATE를 통한 CLR도 ARIES CLR과 같다. CUBRID 의LOG_SYSOP_END와 ARIES의 nested top-action을 나란히 놓고 보면 CUBRID이 모델을 어디서 확장했는지 (logical undo, MVCC undo) 가 드러난다. -
Aurora의 offload-WAL (Verbitski 외, SIGMOD 2017) — WAL 자체를 스토리지 계층으로 옮긴다. 즉 각 컴퓨트 노드는 데이터 페이지가 아니라 로그 레코드를 쓴다. CUBRID의 WAL은 프로세스 로컬이라 이는 기능 격차라기보다 구조적 대비에 가깝다. 두 설계의 프로토콜을 나란히 보면 WAL이 곧 데이터베이스 일 때와 WAL이 데이터베이스를 기술 일 때 무엇이 바뀌는지가 분명해진다.
-
Silo (Tu 외, SOSP 2013) 의 epoch-기반 복구 — ARIES의 대안으로 epoch별로 commit을 묶는다. CUBRID의 group-commit 윈도우는 같은 아이디어의 약한 형태로 볼 수 있다 — 작은 배치를 함께 force하지만, Silo처럼 엄격한 epoch 경계를 두지는 않는다.
-
TimescaleDB / Hyper의 시계열 워크로드용 logging — redo 데이터의 컬럼 특성을 이용해 로그를 압축하는 전략이다. CUBRID의
LOG_DIFF_UNDOREDO_DATA(record type 43) 는 같은 아이디어의 가장 단순한 형태다.
원본 분석 (raw/code-analysis/cubrid/storage/)
섹션 제목: “원본 분석 (raw/code-analysis/cubrid/storage/)”log_manager/log manager_v0.5.docxrecovery_manager/log_manager_v0.3.pptx— recovery_manager 폴더 아래 파일이지만 다루는 표면이 로그 매니저의 그것이다.
교재 챕터 (knowledge/research/dbms-general/)
섹션 제목: “교재 챕터 (knowledge/research/dbms-general/)”- Database Internals (Petrov), 5장 Transactions and Recovery, §Write-Ahead Logging, §Log Sequence Numbers.
- Mohan 외, ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging (TODS 17.1, 1992) — 복구 문서가 인용하지만, LSN 스킴 과 CLR 설계가 처음 명시된 곳이 이 논문이다.
CUBRID 소스 (/data/hgryoo/references/cubrid/)
섹션 제목: “CUBRID 소스 (/data/hgryoo/references/cubrid/)”src/transaction/log_manager.{c,h}src/transaction/log_append.{cpp,hpp}src/transaction/log_record.hppsrc/transaction/log_lsa.{hpp,cpp}src/transaction/log_storage.hppsrc/transaction/log_page_buffer.csrc/transaction/log_compress.{c,h}src/transaction/log_writer.c
이 지식 베이스의 형제 문서
섹션 제목: “이 지식 베이스의 형제 문서”knowledge/code-analysis/cubrid/cubrid-page-buffer-manager.md— WAL 불변식의 데이터 페이지 측.knowledge/code-analysis/cubrid/cubrid-mvcc.md—LOG_MVCC_*레코드의 소비자.knowledge/code-analysis/cubrid/cubrid-recovery-manager.md— 이 로그의 reader. 같은 2026-04-30 배치에서 진행 중.knowledge/code-analysis/cubrid/cubrid-cdc.md—LOG_SUPPLEMENTAL_INFO의 소비자. 같은 배치에서 진행 중.knowledge/code-analysis/cubrid/cubrid-2pc.md—LOG_2PC_*레코드의 소유자. 같은 배치에서 진행 중.