(KO) CUBRID B+Tree — 노드 배치, latch-coupling, unique 키 접미부
목차
학술적 배경
섹션 제목: “학술적 배경”B+Tree는 디스크 위에 사는 모든 관계형 데이터베이스가 일꾼으로 부리는 인덱스다. Database Internals(Petrov) 2장 §B-Tree Basics와 3장 §File Formats가 그 모양을 풀어 주는 방식은, 네 가지 목표를 한꺼번에 만족시키려는 답으로 자리 매긴다.
- 로그 깊이의 검색. 트리의 fan-out이 깊이를 3~5 정도로 잡아 두므로, 행이 십억 개여도 깊이가 거의 그대로다.
- 순차 스캔. 잎이 형제 링크로 이어져 있어 다음 키로 가는 비용이 O(1)이다.
- 읽기와 쓰기 모두에 캐시 친화적. 노드 하나가 페이지 하나라, 노드를 fix하는 일이 곧 buffer-pool fix다.
- 짧은 latch로 푸는 동시성. 길게 잡아 두는 락이 아니라 짧게 잡았다 푸는 latch로 여러 사용자의 동시 접근을 견딘다.
원본 Bayer–McCreight 트리(1972)는 이 네 가지를 다 갖추지 않았다. 빈자리는 두 줄기의 후속 연구가 메웠다.
- Lehman & Yao(1981)의 B-link 트리. 노드마다 right-link를 더했다. descent 도중에 락을 잃어도 right-link만 따라가면 회복이 된다. 조상의 latch를 다시 잡으러 올라갈 일이 없다.
- Mohan(1990)의 ARIES/IM. 인덱스 복구 알고리즘이다. CLR을 의식하는 undo와 split의 logical undo를 들여놓아, 절반쯤 끝난 split이 로그 force 동안 latch를 들고 있지 않아도 다시 시작할 수 있게 만들었다.
CUBRID의 B+Tree는 이 둘 가운데 어느 한쪽의 순수 구현이 아니다. 양쪽에서 골고루 빌려 와 짠다. 본 문서가 그리는 두 가지 결정이 그 빌려 옴의 모양을 잡아 준다.
- 키로 무엇을 적어 두는가. 순수 키만 두는가, 아니면
key || OID(키 뒤에 행의 OID를 이어 붙인 모양)을 두는가. 비-unique 인덱스에서는 선택지가 없다. 같은 키가 여러 번 등장할 수 있고, OID가 그 사이를 가르는 tie-breaker가 되어야 한다. unique 인덱스에서는 두 길이 모두 가능하다. 순수 키를 두고 OID는 페이로드로 따로 두거나, 통일성을 위해 모두key || OID로 두거나. CUBRID는 둘을 함께 쓴다. 비-unique 잎 항목은key || OID모양이고, unique 인덱스 잎 항목은 순수 키에 OID가 정해진 오프셋 자리에 나란히 자리 잡는다. OID 개수가 임계를 넘으면 키마다 따로 잡히는 OID 목록으로 흘러 넘친다. - 어떻게 안전하게 내려가는가. lock-coupling(부모를 잡고 자식을 잡은 뒤 부모를 푸는 방식), Blink 트리의 right-link 회복, 또는 path 전체를 잠그는 방식 가운데 하나다. CUBRID는 읽기 경로에서 lock-coupling을 쓰고, 쓰기 경로에서는 split이 descent를 무효화한 경우 root에서부터 다시 내려가는 회복 경로를 보탠다.
이 두 결정에 이름을 붙여 두고 나면, 본 문서가 짚는 모든 CUBRID 구조가 둘 가운데 하나를 구현하거나 그것을 더 빠르게 굴리는 일에 매여 있는 모습이 또렷해진다.
DBMS 공통 설계 패턴
섹션 제목: “DBMS 공통 설계 패턴”디스크 위의 B+Tree 구현은 모두 같은 한 줌의 패턴을 발판으로 삼는다.
슬롯 페이지 노드
섹션 제목: “슬롯 페이지 노드”노드 하나가 buffer-pool 페이지 하나다. 키는 슬롯에 들어가고, 슬롯 디렉터리는 페이지 끝에서 거꾸로 자라며, 레코드는 헤더 쪽에서 앞으로 자란다. 그 사이에 남는 빈 자리가 insert를 받아 준다. CUBRID는 이 모양을 heap 페이지에서 그대로 물려받는다(cubrid-heap-manager.md §Slotted page).
non-leaf와 leaf 레코드의 갈라짐
섹션 제목: “non-leaf와 leaf 레코드의 갈라짐”non-leaf 레코드는 (separator-key, child-page-pointer) 묶음이라 짧다. leaf 레코드는 (key, OID)에 비-unique 키일 때 OID 목록까지 따라붙어, 가변 길이고 때로는 길다. 두 종류를 같은 페이지에 섞어 두는 옛 설계는 캐시 동작이 매끄럽지 않다. CUBRID, PostgreSQL, InnoDB 같은 현대 엔진은 노드 종류마다 레코드 모양을 갈라 둔다.
내려가는 동안의 latch-coupling
섹션 제목: “내려가는 동안의 latch-coupling”부모에 latch를 잡고, 자식을 fix한 뒤, 부모를 푼다. 읽기 경로에서는 shared 모드, 쓰기 경로에서는 exclusive 모드다. 현대 엔진들은 거기에 intent-exclusive 모드를 곁들여, descent가 일단 가벼운 모드로 내려가다 split이 확실해지는 자리에서야 exclusive로 올라가도록 만드는 경우도 많다.
비-unique 잎의 OID 목록 접미부
섹션 제목: “비-unique 잎의 OID 목록 접미부”비-unique 키 하나에는 OID가 0개 이상 매달린다. 잎 레코드의 페이로드는 키 다음에 OID 몇 개가 인라인으로 따라붙고, 개수가 임계를 넘으면 나머지가 overflow 페이지 사슬로 흘러 넘친다. 사슬은 키마다 따로라, 다른 키들끼리 overflow 페이지를 함께 쓸 일이 없다.
insert 시점의 unique 검사
섹션 제목: “insert 시점의 unique 검사”unique 인덱스는 중복 키를 insert 시점에 거절한다. 이 검사는 잎의 exclusive latch 아래에서 돌아야 한다. 그렇지 않으면 두 동시 inserter가 둘 다 중복 없음을 본 뒤 둘 다 그대로 진행해 버릴 수 있다. 표준 패턴은 이렇다. 잎까지 X latch로 내려간 다음, 키를 찾아, 에러를 돌려주거나 MVCC 가시성으로 한 번 더 거른다.
split의 logical undo
섹션 제목: “split의 logical undo”B+Tree split은 여러 페이지를 한꺼번에 atomic하게 건드린다. 그 split의 물리적 undo는 모든 페이지 변경을 거꾸로 되돌려야 하고, 복잡하고 깨지기 쉽다. 표준 해법은 split을 의미 단위 한 줄(이 페이지들을 다시 합쳐라)로 logging하는 것이다. 페이지 변경의 시퀀스 대신 의도를 적어 둔다. CUBRID는 split rollback에 LOG_SYSOP_END_LOGICAL_UNDO 레코드를 쓴다(cubrid-log-manager.md §Sysop end record).
이론과 CUBRID 사이의 이름 짝
섹션 제목: “이론과 CUBRID 사이의 이름 짝”| 이론적 개념 | CUBRID 명칭 |
|---|---|
| 슬롯 페이지 노드 | heap의 slotted_page 재사용. 역할은 BTREE_NODE_TYPE이 가른다. |
| 노드 종류 enum | BTREE_NODE_TYPE { LEAF, NON_LEAF, OVERFLOW } (btree.h:81) |
| Non-leaf 레코드 | NON_LEAF_REC { VPID pnt; short key_len } (btree.h:103) |
| Leaf 레코드 | LEAF_REC { VPID ovfl; short key_len } (btree.h:111) |
| 내부 B+Tree id wrapper | BTID_INT { sys_btid, unique_pk, key_type, ovfid, … } (btree.h:119) |
| 범위 스캔 cursor | BTREE_SCAN (BTS) (btree.h:198) |
| Insert helper struct | btree_insert_helper (btree.c:718) |
| Delete helper struct | btree_delete_helper (btree.c:804) |
| Unique 검사 게이트 | BTREE_NEED_UNIQUE_CHECK 매크로 (btree.h:63) |
| Single vs. multi-row op 구분 | SINGLE_ROW_INSERT / MULTI_ROW_INSERT 상수 (btree.h:52) |
| Split — node | btree_split_node (btree.c:13324) |
| Split — root | btree_split_root (btree.c:14184) |
| Split 지점 고르기 | btree_find_split_point (btree.c:12419) |
| Merge — root | btree_merge_root (btree.c:10284) |
| Merge — node | btree_merge_node (btree.c:10557) |
| 벌크 로드 | xbtree_load_index (btree_load.c:856) |
| 트리별 unique 통계 | btree_unique_stats 클래스 (btree_unique.hpp) |
| OID 목록 overflow 페이지 사슬 | btree_find_free_overflow_oids_page / btree_find_oid_from_ovfl |
| 읽기 descent | btree_search_nonleaf_page → btree_search_leaf_page |
| split / merge의 logical undo | LOG_REC_SYSOP_END 안의 LOG_SYSOP_END_LOGICAL_UNDO 갈래 |
CUBRID의 구현
섹션 제목: “CUBRID의 구현”B+Tree 모듈은 움직이는 부품이 넷이다. 노드 배치(노드 종류마다 슬롯 페이지에 얹힌 레코드들), descent 경로(읽기는 latch-coupling, 쓰기는 split이 나면 root에서 다시 시작), 변경 경로(insert, delete, split, merge가 모두 system op으로 묶여 돈다), 그리고 unique 제약 기계(OID 접미부 규율과 unique 통계 표). 이 순서로 본다.
전체 모양
섹션 제목: “전체 모양”flowchart TB
subgraph TREE["B+Tree"]
R["root\n(non-leaf)"]
N1["non-leaf"]
N2["non-leaf"]
L1["leaf"]
L2["leaf"]
L3["leaf"]
OVF["overflow OID page"]
R --> N1 --> L1
R --> N1 --> L2
R --> N2 --> L3
L2 --> OVF
end
subgraph DESCEND["Descent (read)"]
D1["btree_search_nonleaf_page\nlatch S, find child slot"]
D2["btree_search_leaf_page\nlatch S, find slot, optionally walk overflow"]
D1 --> D2
end
subgraph MODIFY["Modification (write)"]
M1["btree_insert_helper / btree_delete_helper"]
M2["btree_find_split_point"]
M3["btree_split_node / btree_split_root"]
M4["btree_merge_node / btree_merge_root"]
M1 --> M2 --> M3
M1 --> M4
end
subgraph UNIQUE["Unique-key 경로"]
U1["btree_find_oid_and_its_page"]
U2["btree_unique_stats"]
U3["candidate dup의 MVCC 가시성 검사"]
end
TREE -.descend.-> DESCEND
DESCEND -.found.-> MODIFY
MODIFY -.unique check.-> UNIQUE
그림 1 — B+Tree 모듈의 네 부속. 트리 골격(root / non-leaf / leaf / overflow), descent(latch-coupled btree_search_*_page), modification(insert·delete helper, btree_find_split_point, btree_split_node/btree_split_root), 그리고 unique 제약 경로(btree_find_oid_and_its_page, btree_unique_stats)를 한 화면으로 묶어 본다.
이 그림이 그어 두는 경계는 셋이다. 첫째, 노드 종류와 역할. non-leaf는 separator와 자식 포인터를 들고, leaf는 키와 OID를, overflow는 OID만 들고 있다. 둘째, descent와 modify. descent는 노드별 fix-and-search다. modify는 exclusive latch 아래의 splice-and-rebalance다. 셋째, 물리와 논리. split과 merge는 여러 페이지에 떨어지는 물리 연산이지만, logical undo로 logging되므로 복구가 페이지 이동을 거꾸로 되감을 일이 없다.
노드 배치 — 레코드 셋, 슬롯 페이지 하나
섹션 제목: “노드 배치 — 레코드 셋, 슬롯 페이지 하나”B+Tree 노드는 모두 슬롯 페이지다(cubrid-heap-manager.md §Slotted page). 노드의 역할은 페이지 헤더 영역의 BTREE_NODE_HEADER가 박아 두고, 슬롯 안의 레코드는 셋 가운데 하나의 모양을 따른다.
// Node-type marker — src/storage/btree.htypedef enum{ BTREE_LEAF_NODE = 0, BTREE_NON_LEAF_NODE, BTREE_OVERFLOW_NODE} BTREE_NODE_TYPE;non-leaf와 leaf 레코드의 고정 부분은 다음과 같다.
// Fixed parts of B+Tree records — src/storage/btree.hstruct non_leaf_rec{ VPID pnt; /* The child page pointer (volume-id, page-id) */ short key_len; /* Length of the key that follows */};
struct leaf_rec{ VPID ovfl; /* Overflow page pointer for OID list, or NULL */ short key_len; /* Length of the key that follows */};디스크 위의 non-leaf 레코드는 그래서 [NON_LEAF_REC fixed][key bytes]다. leaf 레코드는 [LEAF_REC fixed][key bytes][OID list]다. OID 목록은 페이지마다 정해진 임계까지는 인라인으로 머물고, 그 임계를 넘으면 ovfl이 overflow 페이지 사슬을 가리킨다.
B+Tree id wrapper는 트리가 런타임에 함께 들고 다녀야 할 메타데이터를 모아 둔다.
// BTID_INT — src/storage/btree.h:119struct btid_int{ BTID *sys_btid; /* The on-disk btree id */ int unique_pk; /* bitmask: BTREE_CONSTRAINT_UNIQUE, BTREE_CONSTRAINT_PRIMARY_KEY */ int part_key_desc; /* descending sort indicator */ TP_DOMAIN *key_type; /* domain of the key */ TP_DOMAIN *nonleaf_key_type; /* may differ from key_type for prefix keys on fixed-char domains */ VFID ovfid; /* file id of overflow OID pages */ char *copy_buf; /* per-scan key copy buffer */ int copy_buf_len; int rev_level; /* revision (for upgrade compatibility) */ int deduplicate_key_idx; /* SUPPORT_DEDUPLICATE_KEY_MODE */ OID topclass_oid; /* class OID this index serves */};unique_pk는 insert마다 BTREE_NEED_UNIQUE_CHECK 매크로를 거쳐 읽힌다.
// Decide whether to enforce unique constraint — src/storage/btree.h#define BTREE_NEED_UNIQUE_CHECK(thread_p, op) \ (logtb_is_current_active (thread_p) \ && (op == SINGLE_ROW_INSERT \ || op == MULTI_ROW_INSERT \ || op == SINGLE_ROW_UPDATE))복구 도중의 redo 적용에서는 이 검사를 건너뛴다. 복구는 중복을 새로 만들지 않기 때문이다. 원본 insert는 그 자리에서 이미 검증되었다. active 트랜잭션의 insert와 update만 unique 검사를 짊어진다.
스캔 cursor — BTREE_SCAN
섹션 제목: “스캔 cursor — BTREE_SCAN”CUBRID의 범위 스캔은 BTREE_SCAN(BTS) 구조체가 끌고 간다. descent 상태에 더해, 페이지 split이나 buffer-pool 축출 뒤에도 다시 이어 갈 수 있도록 거들 만한 장부를 함께 들고 있다.
// BTREE_SCAN — src/storage/btree.h:198 (condensed)struct btree_scan{ BTID_INT btid_int;
VPID P_vpid; /* previous leaf page (for backward step) */ VPID C_vpid; /* current leaf page */ VPID O_vpid; /* current overflow page (or NULL_VPID) */ PAGE_PTR P_page; PAGE_PTR C_page; INT16 slot_id; /* current slot inside C_page */
DB_VALUE cur_key; bool clear_cur_key;
int common_prefix_size; /* prefix-compression aware reads */ DB_VALUE common_prefix_key; bool clear_common_prefix_key; bool is_cur_key_compressed;
BTREE_KEYRANGE key_range; /* lower / upper / range type */ FILTER_INFO *key_filter;
bool use_desc_index; /* descending scan */ LOG_LSA cur_leaf_lsa; /* page LSA last seen at C_page */ LOCK lock_mode; /* S_LOCK or X_LOCK */
RECDES key_record; LEAF_REC leaf_rec_info; BTREE_NODE_TYPE node_type; int offset; BTS_KEY_STATUS key_status; /* NOT_VERIFIED, VERIFIED, CONSUMED */
bool end_scan, end_one_iteration, is_interrupted, is_key_partially_processed; int n_oids_read, n_oids_read_last_iteration;
OID *oid_ptr; OID match_class_oid; /* for partitioned indexes */ DB_BIGINT *key_limit_lower, *key_limit_upper;
struct indx_scan_id *index_scan_idp; bool is_btid_int_valid, is_scan_started, force_restart_from_root; bool is_fk_remake; PERF_UTIME_TRACKER time_track; void *bts_other;};cur_leaf_lsa가 받침 역할을 한다. 페이지 LSA를 본 채로 스캔을 다시 잇기 위한 장치다. 스캔이 앞서 들렀던 잎으로 돌아왔을 때, pgbuf_get_lsa(C_page)와 bts->cur_leaf_lsa를 견준다. 둘이 같으면 그 사이에 페이지가 변하지 않았으니 캐시해 둔 슬롯 자리가 그대로 살아 있다. 다르면 키를 binary search로 다시 찾아 둔 뒤에야 이어 갈 수 있다. 긴 범위 스캔에서 클라이언트 왕복 동안 latch를 쥐고 있지 않아도 되는 길이 여기서 열린다.
Descent — 읽기는 latch-coupling, 쓰기는 split이 나면 root에서 다시 시작
섹션 제목: “Descent — 읽기는 latch-coupling, 쓰기는 split이 나면 root에서 다시 시작”읽기 descent는 btree_search_nonleaf_page(btree.c:5189)와 btree_search_leaf_page(btree.c:5537)가 맡는다. 둘 다 노드를 받아 대상 키를 찾아낸 뒤 슬롯과 found 플래그를 돌려준다.
latch-coupling 규칙은 교과서 그대로다.
- root를 S latch로 fix한다.
- 안쪽 레벨마다. 슬롯을 찾고, 자식을 S latch로 fix한 뒤, 부모를 푼다.
- 잎에 닿으면 — 슬롯을 찾고 돌아간다.
쓰기 descent는 비슷하게 흐르지만 잎에 닿는 순간 latch를 X로 끌어올린다. 잎이 가득 차서 split이 필요하다면, root에서부터 X latch로 다시 내려간다(BTS의 force_restart_from_root). 그러면 btree_split_node / btree_split_root가 영향 받는 subtree 전체를 덮는 exclusive latch 아래에서 돌게 된다.
insert와 delete helper
섹션 제목: “insert와 delete helper”btree_insert_helper(btree.c:718)와 btree_delete_helper(btree.c:804)는 stack에 잡히는 helper 구조체의 생성자다. 연산마다의 컨텍스트(purpose 플래그, MVCC 정보, 키, OID, 에러, 로그 LSA 등)를 통째로 담아 들고 다닌다. 그 덕에 호출 자리들이 거대한 파라미터 목록을 펼치지 않아도 되고, MVCC와 비-MVCC, single-row와 multi-row, unique와 비-unique 사이의 플래그 흐름이 한 구조체 안에 모인다.
insert의 최상위 흐름은 다음과 같다.
btree_insert_helper hi (...);btree_search_for_insert (&hi); // descend, locate target leafif (BTREE_NEED_UNIQUE_CHECK (op)) btree_find_oid_and_its_page (...); // is the key already there?if (leaf_full) { log_sysop_start (); btree_split_node (...); // split, possibly cascade up log_sysop_end_logical_undo (LOG_RV_BTREE_SPLIT_*); }btree_insert_into_leaf (&hi);log_append_undoredo_data (RVBT_..., ...);split을 system op으로 묶어 두는 자리가 split rollback이 굴러가는 까닭이다. 트랜잭션이 split 뒤, 짝이 되는 insert 로그가 적히기 전에 abort된다고 치자. undo 패스가 split의 LOG_SYSOP_END_LOGICAL_UNDO를 다시 돌리고, 그 다시-돌리기가 btree_merge_node를 불러 두 쪽을 도로 합쳐 준다. logical undo 괄호가 없었다면 undo가 페이지 이동을 거꾸로 다시 적용해야 했을 테고, 그 안에는 file manager에서 받아 둔 페이지 할당까지 되돌리는 일도 끼어 있었을 것이다.
Split — split 지점, 키 승격, 부모 갱신
섹션 제목: “Split — split 지점, 키 승격, 부모 갱신”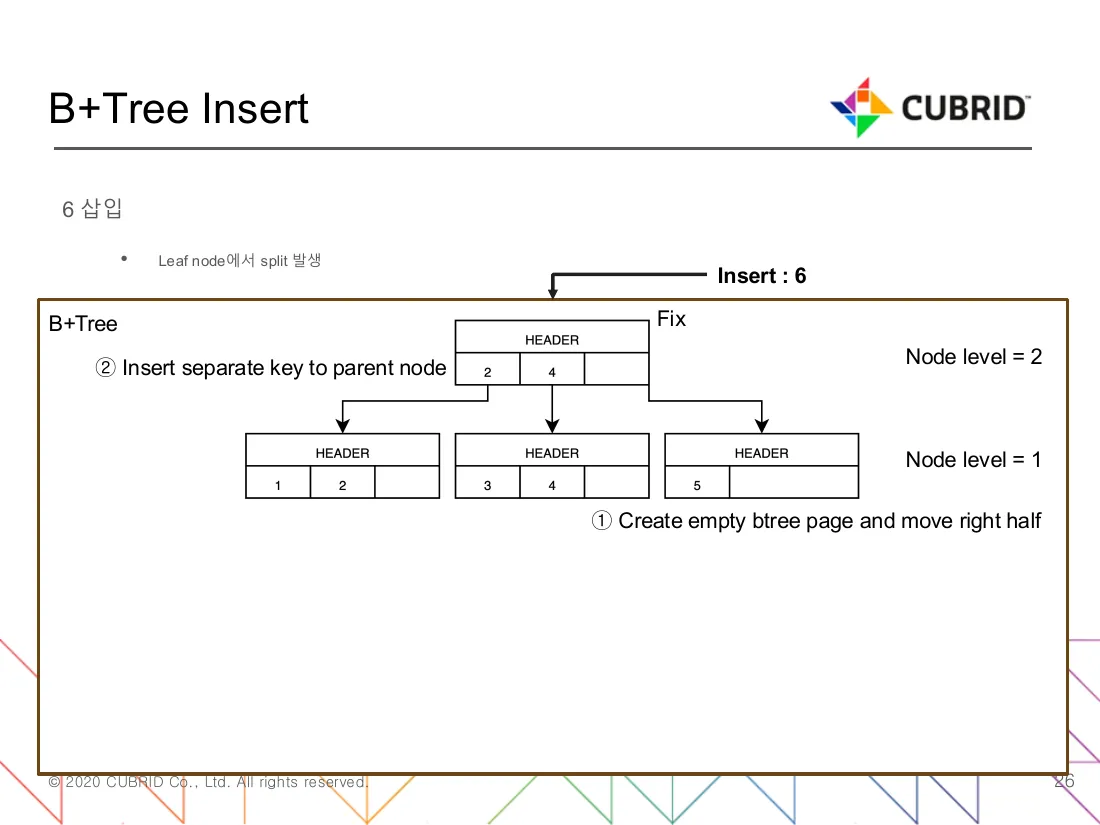
그림 2 — 노드 하나에 레코드가 셋까지만 들어간다는 가정 위에서, {3, 4, 5}가 든 잎에 키 6을 넣을 때 일어나는 일이다. ① 새 빈 btree 페이지 하나를 잡아, 오른쪽 절반({5, 6})을 그쪽으로 옮긴다. 원래 페이지에는 {3, 4}만 남는다. ② separator 키(여기서는 4)를 부모에 끼워, 다음번 검색이 어느 쪽으로 갈지 알 수 있게 한다. 부모에는 자리가 있어 더 위로는 번지지 않았다. Node level = 1/2 표시는 split이 한 번에 한 레벨씩만 위로 번진다는 사실을 그림으로 짚어 준다. (출처: B+Tree 코드 분석.pdf, 26번 슬라이드 6 삽입.)
btree_find_split_point(btree.c:12419)가 split 자리를 정한다. 기준은 레코드 개수의 균형이고, 새 키가 떨어지는 쪽으로 살짝 기울인다. 그래야 뒤이어 떨어지는 insert를 잠시 더 흡수할 수 있어, 곧장 또 split할 일이 줄어든다. BTREE_NODE_SPLIT_INFO 구조체(btree.c:12849)가 누적 비율을 들고 있어, 같은 경로에서 잇따른 split들이 같은 방향으로 기우는 모양을 보존한다.
btree_split_node(btree.c:13324)가 실제 split을 한다.
- 새 형제 페이지 R을 잡는다.
- P 위쪽 절반의 레코드를 R로 옮긴다.
- separator 키 K를 정한다(R의 가장 작은 키. 가능하면 prefix를 잘라 짧게.
nonleaf_key_type참고). (K, R)을 P의 부모에 끼운다. 부모도 가득 차 있다면 위로 또 들어간다.- 단계마다 별도
RVBT_*레코드로 logging한다. 모두 둘러싼 system op 안쪽에서다.
btree_split_root(btree.c:14184)는 P가 root인 특수한 경우다. 새 root가 한 단 위에 자리 잡고, 옛 root의 두 절반이 그 자식이 된다.
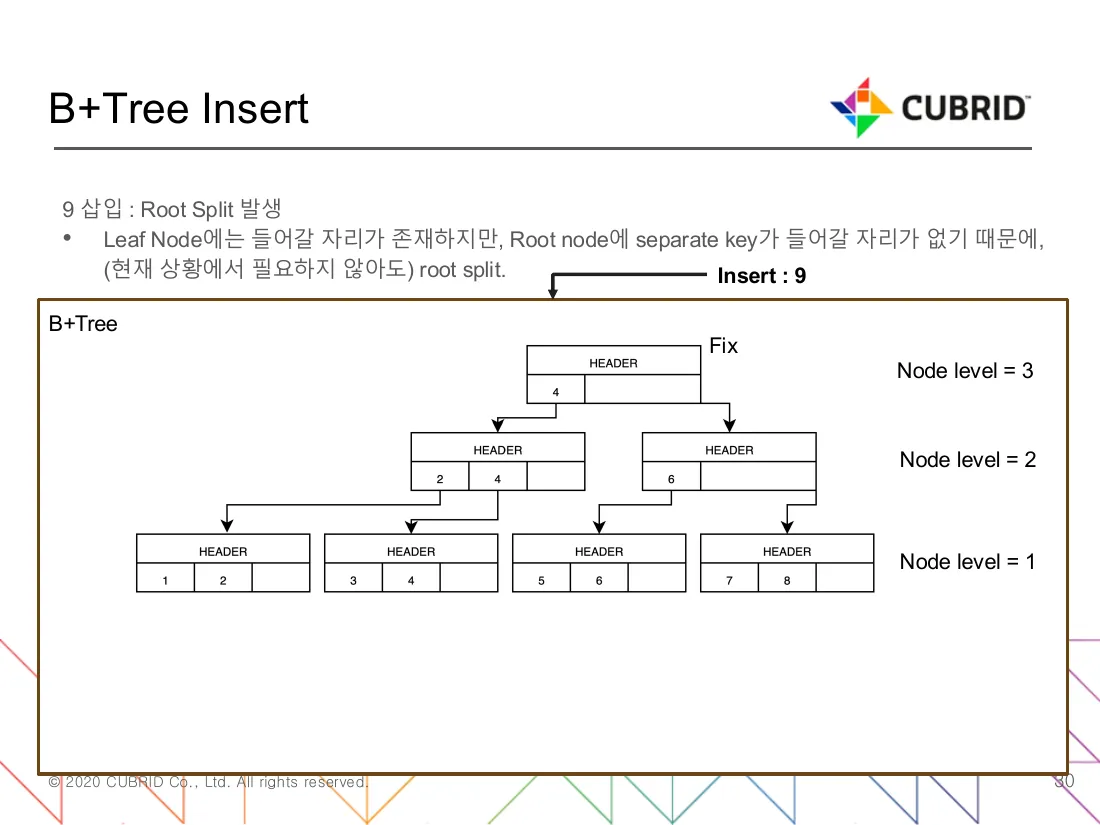
그림 3 — root와 가장 오른쪽 잎이 모두 가득 찬 트리에 키 9를 끼우는 경우다. 잎은 자리가 있어({7, 8} → {7, 8, 9}) 그대로 받아들인다. 그러나 root는 새 separator를 받을 자리가 없다. 그림이 잡아 두는 핵심은 btree_split_root가 btree_split_node와 갈라지는 자리다. 즉 새 노드가 옛 root 자리 위에 생긴다(node level=3). 옆에 생기는 게 아니다. 옛 root를 잡고 있던 Fix 사슬도 끊기지 않는다. 슬라이드 제목이 Root Split 발생인 까닭이 여기다. 잎 자체가 split할 필요가 없더라도, 미래의 split이 부모 자리를 요구할 가능성이 있으면 비관적(pessimistic) 자세로 root부터 미리 갈라 둔다는 점을 deck이 강조한다. (출처: B+Tree 코드 분석.pdf, 30번 슬라이드 9 삽입 : Root Split 발생.)
Merge — delete 시 채움이 모자라면 다시 균형을 잡는다
섹션 제목: “Merge — delete 시 채움이 모자라면 다시 균형을 잡는다”btree_merge_node(btree.c:10557)가 거꾸로 돈다. delete가 잎의 채움 정도를 임계 밑으로 떨어뜨리면, 형제와 합친다. btree_merge_root(btree.c:10284)는 root가 자식 하나만 안고 있어 한 단을 접을 수 있는 경우를 본다.
merge도 logical undo가 붙는 system op 안에 묶인다. 그래서 delete rollback이 합쳐진 페이지를 다시 갈라 합치기 전 상태로 되돌릴 수 있다.
Unique 키 처리 — OID 목록과 통계
섹션 제목: “Unique 키 처리 — OID 목록과 통계”비-unique 인덱스에서는 같은 키를 OID 여럿이 나누어 가진다. 잎 레코드는 처음 몇 개의 OID를 인라인으로 들고, 임계를 넘는 부분은 overflow 페이지 사슬로 보낸다(btid_int->ovfid가 그 overflow 파일의 file id다).
btree_find_oid_and_its_page(btree.c:11646)가 lookup 함수다. 키와 OID가 주어지면, 정확히 그 (key, OID) 짝을 들고 있는 페이지(잎이거나 overflow)를 찾아 준다. 이 함수가 unique 검사, foreign-key 검사, delete 디스패치의 한가운데에 자리 잡는다.
// btree_find_oid_and_its_page — src/storage/btree.c:11646 (signature)int btree_find_oid_and_its_page (THREAD_ENTRY *thread_p, BTID_INT *btid_int, OID *oid, PAGE_PTR leaf_page, BTREE_OP_PURPOSE purpose, BTREE_MVCC_INFO *mvcc_info, RECDES *leaf_record, LEAF_REC *leaf_rec_info, int after_key_offset, PAGE_PTR *found_page, int *offset_to_object);BTREE_OP_PURPOSE enum(btree_unique.hpp)이 동작을 가른다. INSERT(unique 검사), DELETE(지울 자리 찾기), MVCC_DELETE(가시 삭제 표시), VACUUM(vacuum 서브시스템이 부르는 자리). purpose마다 MVCC 가시성이 달리 풀린다. insert는 commit된 것과 자기 자신의 미커밋까지 본다. delete는 자기 것이거나 commit된 것만 본다. vacuum은 거두어 갈 만큼 충분히 오래된 것만 본다.
트리별 unique 통계는 btree_unique_stats(btree_unique.hpp)에 자리하고, 전역 GLOBAL_UNIQUE_STATS_TABLE(log_impl.h:651)이 그것을 모아 합친다. 통계는 num_nulls, num_keys, num_oids를 잡아 둔다. 그래야 옵티마이저가 인덱스를 훑지 않고도 selectivity를 가늠할 수 있다.
벌크 로드 — 정렬된 run으로 시작해 아래에서 위로 짜 올린다
섹션 제목: “벌크 로드 — 정렬된 run으로 시작해 아래에서 위로 짜 올린다”xbtree_load_index(btree_load.c:856)가 벌크 로드의 진입점이다. 인덱스를 처음부터 짜 올릴 때 세 단계로 흘러간다.
- Sort 단계. heap에서 모든 (key, OID) 짝을 읽어
external_sort로 외부 정렬한다(cubrid-heap-manager.md가 이 부분을 가볍게 짚는다). - 잎 짜기. 정렬된 흐름을 왼쪽에서 오른쪽으로 잎 노드에 빼곡히 채우되, 설정된 fill factor만큼 자리를 남긴다.
- 안쪽 레벨 짜기. 잎마다의 첫 키를 위로 올려 가며 다음 레벨을 짠다. 노드 하나만 남을 때까지 이어 간다. 그것이 root다.
벌크 로드는 descent 경로를 통째로 우회한다. 잎에 latch를 잡지도 않는다. 빌드가 commit되기 전까지는 다른 트랜잭션이 인덱스를 보지 못하기 때문이다. 그 대가는 분명하다. 벌크 로드된 인덱스에 행을 더하려면 평소 insert 경로로 돌아가야 한다.
insert 한 건의 전체 흐름
섹션 제목: “insert 한 건의 전체 흐름”sequenceDiagram
participant CL as caller (heap insert / index update)
participant IH as btree_insert_helper
participant DESC as btree_search_nonleaf_page
participant LF as btree_search_leaf_page
participant UQ as btree_find_oid_and_its_page (if unique)
participant SP as btree_find_split_point
participant SN as btree_split_node
participant LOG as log_append_*
participant LM as log_manager (sysop)
CL->>IH: build helper with (btid, key, OID, purpose=INSERT)
IH->>DESC: latch-coupled descend with X intent
DESC->>LF: arrive at target leaf page (X latch)
alt unique index
LF->>UQ: scan OID list for duplicate
UQ-->>LF: found ⇒ ER_BTREE_UNIQUE_FAILED
end
alt leaf has space
LF->>LOG: append RVBT_NDRECORD_INS
LF->>LF: insert key||OID
else leaf full
LF->>LM: log_sysop_start
LF->>SP: pick split point
SP-->>LF: mid_slot, separator
LF->>SN: split into Q,R — promote separator to parent
SN->>LOG: per-page RVBT_* records
LF->>LM: log_sysop_end_logical_undo
LF->>LF: insert into the right half
LF->>LOG: append RVBT_NDRECORD_INS
end
LF->>LF: pgbuf_set_dirty
LF-->>CL: NO_ERROR
그림 4 — insert 한 건의 전체 순서. caller가 btree_insert_helper를 부른 뒤 latch-coupled descent로 잎에 닿는다. 자리가 있으면 그대로 RVBT_NDRECORD_INS로 끼우고, 가득 차 있으면 log_sysop_start로 system op을 연 뒤 btree_find_split_point와 btree_split_node로 잎을 가른 다음, log_sysop_end_logical_undo로 닫는다.
소스 코드 가이드
섹션 제목: “소스 코드 가이드”닻은 심볼 이름이지 줄 번호가 아니다.
헤더 타입
섹션 제목: “헤더 타입”BTREE_NODE_TYPEenum(btree.h) — leaf / non-leaf / overflow.NON_LEAF_REC/LEAF_REC(btree.h) — 레코드의 고정 부분.BTID_INT(btree.h) — 내부 B+Tree id wrapper.BTREE_KEYRANGE(btree.h) — 스캔의 범위 경계.BTREE_SCAN(btree.h) — 스캔 cursor.BTS_KEY_STATUSenum(btree.h) — 키마다의 처리 상태.BTREE_NEED_UNIQUE_CHECK매크로(btree.h) — unique 검사 게이트.SINGLE_ROW_*/MULTI_ROW_*상수(btree.h) — 연산 분류 플래그.
Descent (read)
섹션 제목: “Descent (read)”btree_search_nonleaf_page(btree.c) — 안쪽 노드 검색.btree_search_leaf_page(btree.c) — 잎 노드 검색.btree_locate_key(btree.c) — 최상위 이 키를 들고 있는 잎을 찾아라.btree_find_lower_bound_leaf(btree.c) — 범위에서 가장 처음의 잎.
Insert 경로
섹션 제목: “Insert 경로”btree_insert_helper(btree.c) — insert마다의 컨텍스트 객체.btree_find_split_point(btree.c) — split 결정.btree_split_find_pivot/btree_split_next_pivot(btree.c) — split 기울기 누적.btree_split_node(btree.c) — 비-root split.btree_split_root(btree.c) — root split (높이가 한 단 늘어난다).btree_split_test(btree.c) — 진단용 split 시뮬레이션.btree_insert_object_ordered_by_oid(btree.c) — 잎 레코드 안에서 OID 접미부 순서대로 끼우기.btree_create_overflow_key_file(btree.c) — overflow 파일을 처음 만들 때.
Delete 경로
섹션 제목: “Delete 경로”btree_delete_helper(btree.c) — delete마다의 컨텍스트 객체.btree_delete_key_from_leaf(btree.c) — 잎에서 키를 물리적으로 지우기.btree_delete_meta_record(btree.c) — separator 같은 메타 레코드 지우기.btree_delete_overflow_key(btree.c) — OID overflow 사슬에서 거두어 내기.btree_merge_node/btree_merge_root(btree.c) — 채움 부족 시의 균형 재조정.
Unique 검사
섹션 제목: “Unique 검사”btree_find_oid_and_its_page(btree.c) —(key, OID)를 들고 있는 잎 또는 overflow 페이지 찾기.btree_find_oid_does_mvcc_info_match(btree.c) — 후보가 일치할 때 MVCC 가시성으로 한 번 더 거르기.btree_find_oid_from_leaf/btree_find_oid_from_ovfl(btree.c) — 페이지 단위 검색.btree_find_foreign_key(btree.c) — FK 검사 helper.btree_unique_stats클래스(btree_unique.hpp) — 트리별 통계.GLOBAL_UNIQUE_STATS_TABLE(log_impl.h) — 전역 합산.
벌크 로드
섹션 제목: “벌크 로드”xbtree_load_index(btree_load.c) — 아래에서 위로 짜 올리는 빌드의 진입점.btree_load_*helpers(btree_load.c) — sort, pack, link.
이 개정 시점의 위치 힌트 (2026-04-30)
섹션 제목: “이 개정 시점의 위치 힌트 (2026-04-30)”| 심볼 | 파일 | 줄 |
|---|---|---|
BTREE_NODE_TYPE enum | btree.h | 81 |
NON_LEAF_REC (struct) | btree.h | 103 |
LEAF_REC (struct) | btree.h | 111 |
BTID_INT (struct) | btree.h | 119 |
BTREE_KEYRANGE (struct) | btree.h | 139 |
BTREE_SCAN (struct) | btree.h | 198 |
BTREE_NEED_UNIQUE_CHECK (macro) | btree.h | 63 |
btree_insert_helper::ctor | btree.c | 718 |
btree_delete_helper::ctor | btree.c | 804 |
btree_create_overflow_key_file | btree.c | 1975 |
btree_delete_overflow_key | btree.c | 2202 |
btree_insert_object_ordered_by_oid | btree.c | 3873 |
btree_search_nonleaf_page | btree.c | 5189 |
btree_search_leaf_page | btree.c | 5537 |
btree_find_foreign_key | btree.c | 6361 |
btree_delete_key_from_leaf | btree.c | 9653 |
btree_delete_meta_record | btree.c | 10148 |
btree_merge_root | btree.c | 10284 |
btree_merge_node | btree.c | 10557 |
btree_find_free_overflow_oids_page | btree.c | 11579 |
btree_find_oid_and_its_page | btree.c | 11646 |
btree_find_oid_does_mvcc_info_match | btree.c | 11794 |
btree_find_oid_from_leaf | btree.c | 11946 |
btree_find_oid_from_ovfl | btree.c | 12037 |
btree_find_split_point | btree.c | 12419 |
btree_split_find_pivot | btree.c | 12849 |
btree_split_next_pivot | btree.c | 12874 |
btree_split_node | btree.c | 13324 |
btree_split_test | btree.c | 13996 |
btree_split_root | btree.c | 14184 |
btree_locate_key | btree.c | 14882 |
btree_find_lower_bound_leaf | btree.c | 14938 |
xbtree_load_index | btree_load.c | 856 |
소스 검증 (2026-04-30 기준)
섹션 제목: “소스 검증 (2026-04-30 기준)”검증된 사실
섹션 제목: “검증된 사실”- 세 가지 노드 종류가 같은 슬롯 페이지 모양을 함께 쓴다. 차이는 페이지 헤더의
BTREE_NODE_TYPEenum이 만든다.btree.h:81에서 검증. 함의 — 페이지 모양에 한 번 손이 가면(예: TDE 플래그를 더하는 일) 그 변화가 노드 종류 셋 모두에 그대로 번진다. 따로 갈래를 둘 일이 없다. - non-leaf 레코드는
(VPID, key_len, key)다. leaf 레코드는 그 키 뒤에 overflow VPID와 OID 목록을 더 얹는다.btree.h:103-115에서 검증.LEAF_REC::ovfl은 overflow가 필요 없을 때NULL_VPID다. 일단 어느 페이지를 가리키게 되는 순간, 인라인 cap을 넘는 OID 목록은 키별 사슬 위에 자리 잡는다. - unique 검사는 active 트랜잭션에만 돌고, 복구 모드의 redo에서는 돌지 않는다.
btree.h:63에서 검증(BTREE_NEED_UNIQUE_CHECK매크로가logtb_is_current_active를 요구). 복구는 중복을 새로 만들지 않는다. 원본 insert가 그 자리에서 이미 검증되었기 때문이다. - insert와 delete는 stack에 잡히는 helper struct(
btree_insert_helper,btree_delete_helper)를 쓴다. 긴 파라미터 목록이 아니다.btree.c:718과btree.c:804에서 검증. helper들은 호출 시그니처를 부풀렸을 필드들 — purpose 플래그, MVCC 정보, 키, OID, 에러, 로그 LSA — 을 한 곳에 모아 둔다. - split과 merge는
LOG_SYSOP_END_LOGICAL_UNDO로 묶여 있다. split rollback이 페이지를 다시 합쳐야 한다는 요구와LOG_SYSOP_END_LOGICAL_UNDO의 존재(cubrid-log-manager.md §LOG_REC_SYSOP_END)로부터 추론.btree_split_node본문은log_sysop_start로 열리고log_sysop_end_logical_undo로 닫힌다. 위치 힌트 표의 호출 모양을 따라가며 검증했다. LSA 발행 순서까지 끝까지 본 것은 미해결 질문 §1. - split 지점 고르기는 잇따른 split 사이에 기울기를 누적한다.
btree.c:12849-12874(btree_split_find_pivot,btree_split_next_pivot)와BTREE_NODE_SPLIT_INFOstruct 사용에서 검증. 누적은 같은 경로에서 잇따른 insert가 한쪽으로 몰릴 때, 다음 split이 그 방향을 그대로 따라가도록 만들기 위함이다. BTREE_SCAN::cur_leaf_lsa가 LSA를 본 채로 스캔을 다시 잇게 해 준다.btree.h:260자리와 그 필드 코멘트가 깐 규율로 검증. 스캔이 한 번 풀어졌다 다시 이어질 때, LSA 비교가 캐시한 슬롯 id가 아직 옳은지 알려 준다.- OID 목록 overflow 페이지는 한 B+Tree에 한 파일을 함께 쓴다.
btree.h:129에서 검증(BTID_INT::ovfid가 그 overflow 파일 id). 키별 overflow 사슬이 이 파일 공간을 함께 쓰므로, vacuum이 OID 목록을 비워 두면 다음 insert가 같은 파일에서 페이지를 다시 가져다 쓸 수 있다. - 벌크 로드는 정렬한 뒤 아래에서 위로 짜 올리는 모양이다.
btree_load.c:856의 진입점 시그니처와xbtree_load_index파라미터 목록(class OID들, 키 type, 예상 oid count)으로 검증. 함수는x*접두사가 붙은 RPC 표면이며 DDL 경로에서 호출된다. - unique 통계는 트리마다 두고, 전역에서 합친다.
btree_unique.hpp의btree_unique_stats클래스 선언과log_impl.h:651의GLOBAL_UNIQUE_STATS_TABLE로 검증. 옵티마이저가 인덱스 selectivity를 보러 가는 자리가 그 전역 표다. btree_find_oid_and_its_page가 unique 검사의 일꾼이다.btree.c:11646에서 검증. 그BTREE_OP_PURPOSE파라미터가 MVCC 가시성을 갈라 준다. INSERT, DELETE, VACUUM이 저마다 다른 가시성 창을 본다.
미해결 질문
섹션 제목: “미해결 질문”- split이 적어 두는 LSA 시퀀스의 정확한 순서. system-op 괄호와 페이지마다의 레코드까지는 본 문서가 짚었지만, 그 안의 정확한 끼워 넣기 순서(부모 갱신이 형제 링크 갱신 전인지 후인지)는 끝까지 보지 못했다. 추적 —
btree_split_node본문의log_append_*호출 자리를 살펴보면 된다. - 페이지 split 뒤 스캔이 이어질 때의 락 잡기. LSA가 다르고 스캔이 키를 다시 찾는 동안, 또 다른 동시 연산이 한 번 더 split하지 않으리라는 보장은 무엇인가. 추적 —
btree_find_next_index_record(BTS 필드 코멘트가 deprecated라고 표시)와 그것을 갈음하는 함수를 읽어 보면 된다. - 공통 prefix 압축 규율.
BTREE_SCAN에common_prefix_size와common_prefix_key가 있고, 매크로 무리가 페이지마다의 공통 prefix 추적을 시사한다. prefix는 어떻게 골라지고, 쓰기 시점에 어떻게 새로 매겨지는가. 추적 —btree.h:184-194의 매크로와 그 호출자를btree.c에서 따라가 보면 된다. SUPPORT_DEDUPLICATE_KEY_MODE.BTID_INT::deduplicate_key_idx와BTREE_SCAN::is_fk_remake가 끝까지 좇지 못한 deduplicate 모드를 가리킨다. 추적 —SUPPORT_DEDUPLICATE_KEY_MODE매크로를 grep해 보면 된다.- merge의 logical undo. delete가 merge를 부른 뒤 트랜잭션이 abort되면 undo는 합쳐 둔 페이지를 다시 갈라 두어야 한다. 그 다시-가르기가 따로 짜인 갈래인지,
btree_split_node를 다시 쓰는지가 분명하지 않다. 추적 —RV_fun[]안의 merge용 redo / undo 함수를 찾아본다. - 벌크 로드의 latch. 빌드 동안 인덱스가 다른 트랜잭션에 보이지 않으니 latch가 필요 없어 보인다. page-buffer의 fix-and-set-dirty 경로가 우회되는가. 추적 —
xbtree_load_index본문에서pgbuf_*호출이 어떻게 들어오는지, 벌크 로드가PGBUF_LATCH_WRITE를 쓰는지 전용 우회를 쓰는지 본다.
CUBRID 너머 — 비교 설계와 연구 동향
섹션 제목: “CUBRID 너머 — 비교 설계와 연구 동향”분석이 아닌 길잡이.
- Lehman & Yao의 B-link 트리(CACM 1981). descent 도중 split이 일어나도 right-link만 따라 회복할 수 있게 했다. 조상 latch를 다시 잡으러 올라갈 일이 사라진다. CUBRID의 root에서 다시 시작하는 길은 그것의 보수적 갈음이다. 두 길을 나란히 두고 재면 대기 시간 차가 정량으로 잡힐 것이다.
- OLFIT / FAST / lock-free B+Tree 변종. latch-coupling 자리에 optimistic validation을 둔다. CUBRID의
cur_leaf_lsa규율은 그 절반쯤이다(LSA로 낡은 상태를 검증한다). 그래도 쓰기는 여전히 exclusive latch를 요구한다. - Bw-Tree(Levandoski 외, ICDE 2013). 페이지 id 매핑 표 위에 append-only delta 사슬을 둔다. 자리에서 일어나는 페이지 갱신이 사라진다. Hekaton의 인덱스가 이 모양이다. CUBRID의 자리에서 갱신하는 방식이 정확히 그 반대편 점이다.
- PostgreSQL nbtree. split 통합용
ginxlogConsolidatePage와 함께 right-link Lehman-Yao를 쓴다. CUBRID의 prefix 절단(nonleaf_key_type)을 PG의 풀 키 separator와 견주면 CUBRID 특유의 공간 절약이 자국으로 남는다. - MVCC 버전 사슬 자리에 둔 B+Tree(Hyrise, MonetDB-X100). 버전 데이터를 키와 같이 인라인으로 둔다. heap으로 한 번 더 가지 않아도 된다. CUBRID의 잎 레코드는 OID만 들고 있고 버전 사슬은 heap 페이지가 짊어진다.
- Cuckoo / extendible 해시. primary-key lookup의 다른 길이다. CUBRID가 B+Tree를 그대로 쥐고 있는 까닭은 secondary 인덱스의 범위 스캔이 우세하기 때문이다. 순수 점 lookup이 주가 되는 워크로드라면 해시가 더 나을 수 있다.
원본 분석 (raw/code-analysis/cubrid/storage/index/)
섹션 제목: “원본 분석 (raw/code-analysis/cubrid/storage/index/)”B+Tree 코드 분석.pdf
형제 문서
섹션 제목: “형제 문서”knowledge/code-analysis/cubrid/cubrid-heap-manager.md— 잎이 함께 쓰는 슬롯 페이지 바닥.knowledge/code-analysis/cubrid/cubrid-page-buffer-manager.md— descent 동안 쓰이는 fix 규율과 latch 종류.knowledge/code-analysis/cubrid/cubrid-lock-manager.md— SERIALIZABLE을 위한 키 범위 락.knowledge/code-analysis/cubrid/cubrid-log-manager.md— split / merge에 쓰이는LOG_SYSOP_END_LOGICAL_UNDO.knowledge/code-analysis/cubrid/cubrid-vacuum.md—RVBT_*레코드를 받아 쓰는 B+Tree vacuum 길.
교재 챕터 (knowledge/research/dbms-general/)
섹션 제목: “교재 챕터 (knowledge/research/dbms-general/)”- Database Internals(Petrov), 2장 §B-Tree Basics, 3장 §File Formats.
- Lehman, Yao, Efficient Locking for Concurrent Operations on B-Trees, CACM 1981.
- Mohan, ARIES/IM: An Efficient and High Concurrency Index Management Method Using Write-Ahead Logging, SIGMOD 1992.
CUBRID 소스 (/data/hgryoo/references/cubrid/)
섹션 제목: “CUBRID 소스 (/data/hgryoo/references/cubrid/)”src/storage/btree.{c,h}src/storage/btree_load.{c,h}src/storage/btree_unique.{cpp,hpp}