(KO) CUBRID Page Buffer Manager — BCB, 3-zone LRU, private quota, direct victim 인계, custom latch
목차
- 학술적 배경
- DBMS 공통 설계 패턴 (Common DBMS Design)
- CUBRID의 구현
- 소스 코드 가이드
- 소스 검증 (2026-04-29 기준)
- CUBRID 너머 — 비교 설계와 연구 동향 (Beyond CUBRID — Comparative Designs & Research Frontiers)
- 출처
학술적 배경
섹션 제목: “학술적 배경”페이지 버퍼 (page buffer; 또는 buffer pool) 는 디스크와 DBMS 의 다른 모든 모듈 사이에 놓인 메모리 캐시다. 디스크 I/O 는 메모리 접근보다 몇 자릿수 더 느리다. 그래서 엔진은 최근에 건드린 페이지의 사본을 RAM 에 두고, 모든 읽기와 쓰기를 그 사 본으로 한다. Database System Concepts (Silberschatz, Korth, Sudarshan, 6판) 13장 Storage and File Structure 는 버퍼를 다른 모듈이 디스크 지연이 없는 척하게 해 주는 단위 로 설명 한다. 대부분의 페이지는 대부분의 시간 동안 메모리에 머문다. 그 환상을 유지하는 컴포넌트가 buffer manager 다.
교재가 정리한 버퍼 매니저의 네 가지 핵심 요소는 다음과 같다.
- 페이지 테이블 (page table). 디스크 페이지 식별자를 메 모리 슬롯으로 매핑하는 해시 테이블. 모든 페이지 읽기 경로 의 핫 패스다.
- 자유 / 교체 리스트 (free / replacement list). 요청된 페이지가 버퍼에 없을 때, 빈 슬롯을 찾거나 victim 을 골라 eviction 한다. 고전 알고리즘은 LRU 다. clock, ARC, 2Q, LRU-K 같은 변형은 정확도와 관리 비용을 trade-off 한 다.
- Fix / unfix 프로토콜. 페이지를 읽거나 쓰려는 스레드는
먼저 버퍼 슬롯을 fix 한다. fix 는 슬롯의 참조 카운터를
1 증가시키고 페이지 래치 (page latch; read 또는 write) 를
잡는 일을 함께 한다. fix 된 동안에는 슬롯이 evict 되지 않
는다. unfix 는 래치를 풀고 카운터를 1 줄이는 반대 동작이
다. 이 page latch 는 트랜잭션 잠금 (lock) 과 다르다 —
짧게만 잡히고, 슬롯에 내장되어 있고, 격리 (isolation) 와
무관하다 (
cubrid-lock-manager.md의 §“Lock vs latch separation” 참고). - Write-Ahead Logging (WAL) 정합. 마지막 flush 이후 수정 된 dirty 페이지는 그 수정 내역을 담은 로그 레코드가 디스 크에 먼저 flush 된 뒤가 아니면 디스크에 쓸 수 없다. 표준 인용처는 Mohan et al. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging (TODS 1992) 이다. buffer manager 와 log manager 사이에는 단방향 순서 제약이 있다 — log 가 먼저 디스크에 가고, page 는 그 다음에 간다.
여기에 더해 모든 현대 구현이 공유하는 두 가지 아키텍처 요소가 있다.
- 고동시성 환경에서의 free-page 조정. 여러 스레드가 동시 에 victim 을 찾을 때 단일 락으로 LRU 리스트를 보호하면 모든 작업이 직렬화되어 버린다. 그래서 실제 시스템은 리스트를 여 러 작은 리스트로 쪼갠다. 각 리스트마다 별도의 락을 두거나, 아예 lock-free 로 운영한다.
- Background flusher 와 double-write. 페이지는 evict 될
때만 flush 되는 것이 아니라 background daemon 에 의해서도
flush 된다 (PostgreSQL bgwriter, MySQL 의
innodb_io_capacityflusher, CUBRID 의 page flush daemon). 일부 엔진은 OS 의 디스크 페이지 크기보다 DB 의 페이지 크기 가 더 큰 환경에서 발생할 수 있는 torn write 를 복구하기 위해, 페이지를 실제 위치에 쓰기 전에 double-write buffer 에도 미리 써 둔다.
이 문서는 위 요소들을 CUBRID 가
src/storage/page_buffer.{h,c} 와 관련
src/storage/double_write_buffer.{hpp,cpp} 에서 어떻게 구현했
는지를 차례로 따라간다.
DBMS 공통 설계 패턴 (Common DBMS Design)
섹션 제목: “DBMS 공통 설계 패턴 (Common DBMS Design)”교재가 모델을 준다면, 이 섹션은 거의 모든 DBMS buffer manager
가 어떤 형태로든 채택하는 공학적 관행 의 이름을 모은다.
PostgreSQL, Oracle, MySQL InnoDB, SQL Server, CUBRID 가 모두
이 패턴을 공유한다. 다음 섹션 ## CUBRID의 구현 은 발명이 아
니라, 이 공유 설계 공간 위에서 선택된 다이얼 조합으로 읽으면
된다.
Buffer Control Block (BCB) — 페이지 메타데이터 + 슬롯 자체
섹션 제목: “Buffer Control Block (BCB) — 페이지 메타데이터 + 슬롯 자체”버퍼 풀은 고정 크기 슬롯의 배열이고, 슬롯 하나가 캐시된 페이
지 하나에 대응한다. 각 슬롯은 작은 control block 으로 감
싸여 있다. 이 블록에는 페이지 식별자, 래치 상태, fix count,
dirty bit, LRU 위치, 그리고 슬롯이 참여하는 여러 리스트의 포
인터들이 들어 있다. 이 블록의 이름은 엔진마다 다르다 —
PostgreSQL 은 BufferDesc, Oracle 은 buffer header, CUBRID
는 PGBUF_BCB 라 부른다. 실제 페이지 바이트가 들어가는 데이
터 영역은 메타데이터를 담는 컨트롤 영역과 분리되어 있다. 페
이지 본체를 OS 와 디스크의 페이지 크기에 맞춰 정렬해 I/O 효율
을 확보하기 위해서다.
Page table = VPID 에서 슬롯으로 가는 해시
섹션 제목: “Page table = VPID 에서 슬롯으로 가는 해시”해시 테이블이 디스크 페이지 식별자를 BCB 로 매핑한다. CUBRID
는 키로 VPID = (volid, pageid) 를, PostgreSQL 은
BufferTag = (rel, fork, blocknum) 을 쓴다. 키의 모양은 본질
적으로 같다. 크기는 서버 시작 시점에 한 번 정해진다. CUBRID
의 경우 2²⁰ 버킷으로 고정되며, 충돌은 chaining 으로 처리한다.
이 테이블은 모든 페이지 접근의 핫 패스라서 컨텐션을 줄이려고
적극적으로 분할 (partitioning) 되는 것이 일반적이다.
Invalid (free) list = 비어 있는 슬롯 풀
섹션 제목: “Invalid (free) list = 비어 있는 슬롯 풀”페이지가 매핑되어 있지 않은 슬롯들을 모아 둔 작은 단일 연결 리스트다. 새 요청은 이 리스트를 우선 쓴다. eviction (victim 선정) 은 이 리스트가 비었을 때만 동작한다. “사용되지 않은 슬 롯 경로와 누군가를 evict 하는” 경로를 따로 두는 것은 보편적 인 최적화다. 흔한 경우의 할당 비용을 한 자릿수 이상 줄여 주기 때문이다.
Multi-zone LRU = 최근성을 인지하는 eviction
섹션 제목: “Multi-zone LRU = 최근성을 인지하는 eviction”순수 LRU 는 sequential flooding 에 취약하다. 큰 스캔 한 번 이 DB 의 모든 페이지를 건드리면, 핫 working set 이 통째로 밀 려난다. 그래서 실제 시스템은 LRU 를 두세 개의 zone 으로 나눈 다. 최근에 접근된 페이지는 hot zone 에 살고, 일정 기간 다시 접근되지 않으면 중간 warm zone 으로 떨어진다. 더 오래되면 차가운 cold zone 으로 내려간다. eviction 대상이 되는 것은 cold zone 까지 떨어진 페이지뿐이다. CUBRID 는 zone 을 셋으로 나눈다 (LRU 1 / 2 / 3 = top / middle / bottom). PostgreSQL 의 clock-sweep, MySQL InnoDB 의 mid-point insertion strategy, Oracle 의 touch-count 모두 같은 발상에 다른 이름을 붙인 것이 다.
Worker 별 (private) LRU — 스캔 flooding 에 대한 방어
섹션 제목: “Worker 별 (private) LRU — 스캔 flooding 에 대한 방어”워커 스레드가 동시 다발로 돌면 단일 공유 LRU 리스트는 컨텐션 병목이자 정보 병목 이 된다. 한 워커의 풀 테이블 스캔이 다른 워커의 hot working set 을 망쳐 버리기 때문이다. 해결책은 스 레드 단위 (private) LRU 리스트 를 두는 것이다. 각 워커는 우 선 자기 LRU 리스트 안에서만 페이지를 promote 하고 evict 한 다. 페이지가 그 워커의 로컬 교체 압력을 견디고 살아남았을 때 에만 shared LRU 리스트로 옮겨 간다. CUBRID 의 private LRU 에 는 최근 hit 활동에 따라 적응적으로 조정되는 quota 가 추 가로 붙는다.
Lock-free 큐로 victim 조정
섹션 제목: “Lock-free 큐로 victim 조정”버퍼가 압박을 받을 때는 여러 스레드가 동시에 victim 을 찾는 다. 이 탐색을 단일 락으로 조정하면 코어 수가 늘수록 재앙이 된다. 표준 해법은 lock-free circular queue 다. victim 후 보가 한 개 이상 있는 LRU 리스트들만 모아 둔 큐다. 스레드는 큐에서 리스트를 꺼내 스캔하고, 경합이 발생하면 다음 리스트로 넘어간다. CUBRID 에서는 이를 LFCQ 라고 부른다. 같은 자료 구조 가 여러 엔진에서 반복적으로 등장하는 패턴이다.
Direct victim 인계 (hand-off)
섹션 제목: “Direct victim 인계 (hand-off)”private LRU 와 LFCQ 를 갖춰도 즉시 가용한 후보가 없는 순간은 여전히 발생한다. 단순한 답은 spin 을 돌거나 전역 condition variable 위에서 sleep 하는 방법이다. 그보다 더 나은 답이 direct victim 인계 다. 슬롯을 해제 한 스레드 (예: flush 가 끝난 BCB 를 들고 있는 스레드) 가 sleep 중인 다른 스레드에 게 그 슬롯을 직접 넘기는 방식이다. 인계 지점은 정적 배열의 스레드 단위 슬롯이다. CUBRID 는 이를 우선순위 큐 두 개 (High / Low) 로 구현해서, vacuum worker 와 재시도 중인 alloc 에게 우선권을 준다.
사용자 정의 (user-level) page latch
섹션 제목: “사용자 정의 (user-level) page latch”OS mutex 는 빠른 경로에서도 수백 나노초가 걸린다. 모든 페이지
읽기와 쓰기마다 잡히는 page latch 에서는 그 비용이 지배적이
다. 그래서 실제 엔진은 atomic counter 위에 사용자 정의 read
/ write latch 를 직접 만든다. 보통 holder 와 waiter 리스트,
그리고 명시적 promotion 지원이 함께 따라온다. PostgreSQL 에는
LWLock, MySQL InnoDB 에는 rw_lock_t, CUBRID 에는 BCB
latch 가 있다. 모두 같은 세 가지 기본 동작을 갖춘다 — read /
write 호환성 판정, FIFO waiter wake, read → write promotion.
다중 페이지 deadlock 회피를 위한 ordered fix
섹션 제목: “다중 페이지 deadlock 회피를 위한 ordered fix”heap 연산이 home page, forwarded page, overflow page
세 곳을 모두 fix 해야 하는 경우가 있다. 이때 서로 다른 스레드
가 페이지를 다른 순서로 잡으면 데드락이 발생할 수 있다. 교재
의 해법은 ordered fix 다. 모든 페이지에 숫자 rank 를
매기고 (예: heap-header < heap-normal < overflow), 항상 rank
오름차순으로 fix 하는 방식이다. CUBRID 는 이를
pgbuf_ordered_fix 와 PGBUF_WATCHER 구조체로 노출한다.
PostgreSQL 은 같은 문제를 인덱스 / 힙 프로토콜
(_bt_findinsertloc 류 흐름) 에서 해결한다. 근본 제약은 같
다.
Background flush daemon + double-write buffer
섹션 제목: “Background flush daemon + double-write buffer”foreground 워커와 함께 여러 daemon 스레드가 돈다.
- Page Flush Daemon: 주기적으로 dirty 페이지를 디스크로 flush.
- Page Post-Flush Daemon: flush 가 끝난 페이지의 후처리. 가능하면 direct victim 으로 인계.
- Page Maintenance Daemon: 최근 활동에 따라 private LRU 의 quota 를 조정.
OS 의 디스크 블록 크기보다 DB 의 페이지 크기가 더 큰 환경 (예: OS 4 K vs DB 16 K) 에서는 페이지 한 장의 일부만 디스크에 기록되는 torn page 가 발생할 수 있다. 이를 복구하기 위한 장치가 double-write buffer 다. 페이지를 실제 위치에 쓰기 전에 DWB 에 먼저 써 두는 방식이다. 순서는 — (1) 순차 DWB 영 역에 페이지를 쓴다. 그 다음 (2) 실제 페이지 위치에 쓴다. 크 래시 복구 시점에는 손상된 페이지를 DWB 의 깨끗한 사본으로 복 원한 뒤 WAL 을 다시 적용한다. MySQL InnoDB 와 CUBRID 모두 DWB 를 구현하고, PostgreSQL 은 대신 full-page-image WAL 레코 드로 같은 보호를 제공한다.
이론 ↔ CUBRID 명칭 매핑
섹션 제목: “이론 ↔ CUBRID 명칭 매핑”§학술적 배경 의 교재 개념과 CUBRID 의 명명된 엔티티가 다음
과 같이 대응된다. ## CUBRID의 구현 은 각 행을 차근차근 따라
들어간다.
| 이론 (Theory) | CUBRID 명칭 |
|---|---|
| Buffer control block | PGBUF_BCB (page_buffer.c) |
| 디스크 페이지의 물리 포맷 | FILEIO_PAGE (LSA + ptype + page contents) |
| 페이지 식별자 | VPID = (volid, pageid) |
| Page table (해시) | pgbuf_Pool.buf_HT[] (2²⁰ 버킷, chaining) |
| Free / invalid list | pgbuf_Pool.buf_invalid_list |
| 3-zone LRU | LRU 1 / 2 / 3 = top / middle / bottom (LRU 리스트 내부) |
| Worker 별 LRU | private LRU 리스트, 워커당 하나 |
| Private 리스트별 적응형 quota | pgbuf_adjust_quotas (Page Maintenance Daemon) |
| Lock-free victim 조정 | LFCQ (big private / private / shared) |
| Direct victim 인계 | pgbuf_assign_direct_victim / pgbuf_get_direct_victim |
| 사용자 정의 page latch | BCB latch (PGBUF_LATCH_READ / _WRITE / _FLUSH) |
| Alloc 중 VPID 단위 잠금 | PGBUF lock |
| 다중 페이지 deadlock 회피용 ordered fix | pgbuf_ordered_fix + PGBUF_WATCHER + PGBUF_ORDERED_RANK |
| Background flush | Page Flush / Post-Flush / Maintenance daemon 3개 |
| Torn-write 복구 | Double Write Buffer (double_write_buffer.{hpp,cpp}) |
CUBRID의 구현
섹션 제목: “CUBRID의 구현”CUBRID 는 위의 관행을 단일 전역 pgbuf_Pool 구조체로 구체화
한다. 이 구조체 안에 고정 크기 PGBUF_BCB 배열, 다섯 개의 상
태 zone, 세 종류의 LFCQ, 세 개의 background daemon, 그리고
사용자 정의 BCB latch 가 모두 들어 있다. 차별화된 선택은 여섯
가지다. (1) 3-zone LRU (1 / 2 / 3). 기본 임계값은 5 % 이
고, boost 시점에는 old enough 게이트를 둔다. (2) 적응형
quota 를 가진 워커별 private LRU, 그리고 private 의 교체
압력을 견딘 페이지를 받는 shared LRU. (3) over-quota 정도
가 큰 리스트를 우선 탐색하도록 big-private / private /
shared 로 계층화된 lock-free circular queue. (4) 스레드
별 슬롯 bcb_victims[] 을 통한 direct victim 인계, 그리
고 우선순위 큐 두 개. (5) 명시적 promotion 과 별도 FLUSH 대기
상태를 가진 사용자 정의 BCB latch. (6) 동일 페이지에 대한
동시 alloc 을 직렬화하는 VPID 단위 PGBUF lock.
Page fix 가 흐르는 방식 (How a page fix flows)
섹션 제목: “Page fix 가 흐르는 방식 (How a page fix flows)”flowchart LR
A["pgbuf_fix(VPID, fetch_mode,\nlatch_mode, condition)"] --> B{"page table에 있나?"}
B -- "있음" --> L["BCB latch 호환성 검사"]
L -- "호환" --> F["fcnt++, PAGE_PTR 반환"]
L -- "비호환" --> W["waiter list에 등록, sleep"]
W --> L
B -- "없음" --> A1["pgbuf_claim_bcb_for_fix:\nBCB 할당"]
A1 --> I{"invalid list\n비었나?"}
I -- "안 비었음" --> G["free BCB 하나 가져옴"]
I -- "비었음" --> V["pgbuf_get_victim:\nprivate/shared LFCQ 스캔"]
V --> V2{"victim 찾았나?"}
V2 -- "예" --> G
V2 -- "아니오" --> D["direct-victim queue에서 sleep\n(High / Low priority)"]
D --> G
G --> R{"fetch_mode\n== NEW_PAGE?"}
R -- "아니오" --> RD["DWB → 디스크 순으로 read"]
R -- "예" --> Z["zero-fill"]
RD --> P["page table에 등록,\nlatch 잡고 PAGE_PTR 반환"]
Z --> P
F --> END
P --> END[" "]
그림 1 — pgbuf_fix 호출부터 page table 히트·미스 분기, BCB latch 호환성 검사, direct-victim 대기, 디스크 read, page table 등록까지 페이지 fix 전체 경로.
각 박스는 아래 서브섹션에서 풀어 본다.
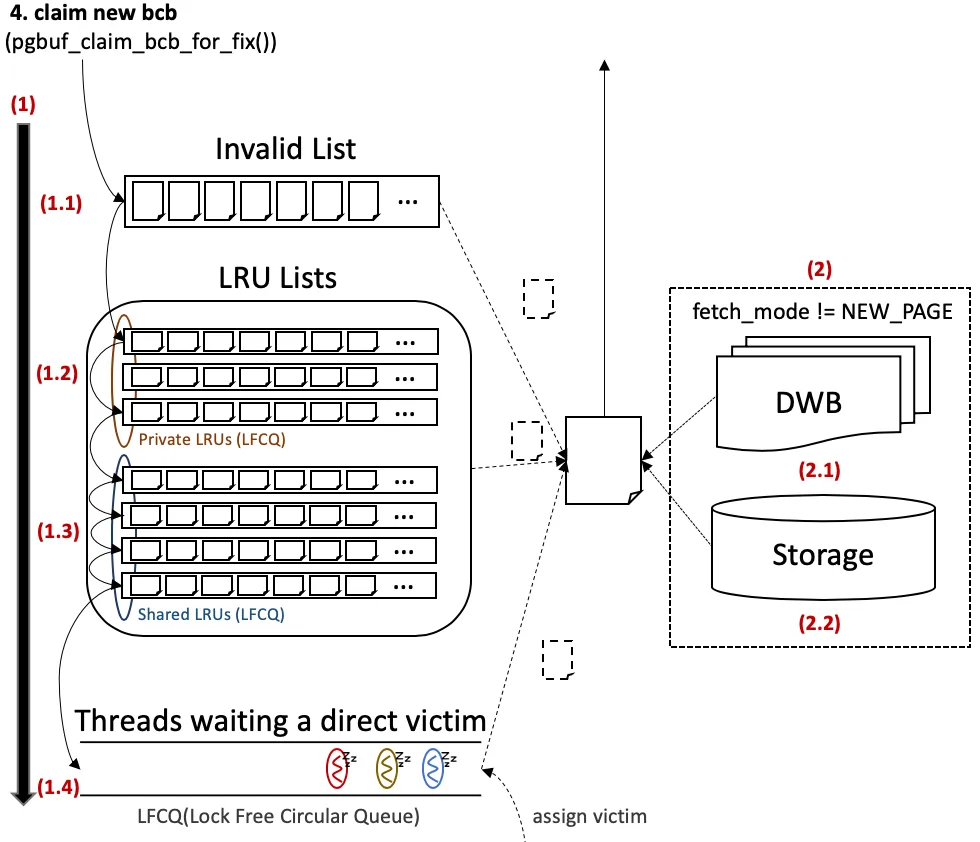
Figure (BCB allocation) — The right half of the Mermaid above, drawn
with the deck’s own conventions. Step 1 searches three places
in order: (1.1) the Invalid List of free BCBs, (1.2) the
worker’s Private LRUs (via the LFCQ), (1.3) the Shared LRUs
(via the LFCQ); on miss, (1.4) the thread joins a direct-victim
LFCQ and sleeps. Step 2 — once a BCB is in hand and
fetch_mode != NEW_PAGE — the page bytes are loaded by checking
(2.1) the DWB first, then (2.2) the actual Storage if the
DWB has no copy. (Source: deck Figure 4.)
Buffer Control Block — PGBUF_BCB
섹션 제목: “Buffer Control Block — PGBUF_BCB”BCB 하나가 버퍼 슬롯 하나를 감싸는 구조다. 페이지 식별자, fix
count, latch 상태, dirty bit, LRU 포인터, 해시 체인 포인터,
그리고 실제 페이지 바이트 (PGBUF_IOPAGE_BUFFER) 포인터를 한
자리에 모아 들고 있다.
// PGBUF_BCB (condensed) — src/storage/page_buffer.cstruct pgbuf_bcb{ pthread_mutex_t mutex; /* per-BCB mutex */ VPID vpid; /* (volid, pageid) of resident page */ int fcnt; /* fix count */ PGBUF_LATCH_MODE latch_mode; /* current latch mode */ THREAD_ENTRY *next_wait_thrd; /* head of waiter list */ volatile int flags; /* zone | LRU_index | BCB flags */
PGBUF_BCB *hash_next; /* hash chain (page table) */ PGBUF_BCB *prev_BCB; /* LRU chain — back */ PGBUF_BCB *next_BCB; /* LRU chain — forward */
int tick_lru_list; /* LRU bookkeeping */ int tick_lru3; int hit_age; volatile int count_fix_and_avoid_dealloc;
LOG_LSA oldest_unflush_lsa; /* oldest LSA not yet on disk */
PGBUF_IOPAGE_BUFFER *iopage_buffer; /* the page bytes */};flags 필드는 여러 종류의 상태를 32 비트 워드 하나에 묶어 저
장한다. 구체적인 비트 배치는 아래 §BCB flags 를 참고한다.
데이터 영역은 iopage_buffer 에 있다. 그 안의 FILEIO_PAGE
첫 16 바이트에는 페이지의 LOG_LSA (가장 최근 갱신 LSN) 와
ptype (volume header / heap / btree / …) 이 들어 있다.
page-write 코드가 WAL 순서를 강제할 때 이 두 값을 참조한다.
Page table — VPID 해시
섹션 제목: “Page table — VPID 해시”// pgbuf_Pool.buf_HT[] — src/storage/page_buffer.c (sketch)// 1 << 20 = 1,048,576 buckets, chaining, ~16M slot capacity.struct pgbuf_buffer_hash{ pthread_mutex_t hash_mutex; /* per-bucket mutex */ PGBUF_BCB *hash_next; /* head of BCB chain */ PGBUF_BUFFER_LOCK *lock_next; /* per-VPID lock chain (PGBUF lock) */};각 버킷에는 두 종류의 체인이 따로 매달려 있다. 하나는 BCB 체 인이다. 이 버킷으로 해싱되는 모든 BCB 의 연결 리스트다. 다른 하나는 PGBUF lock 체인이다. 어떤 스레드가 alloc 중이라 해 당 VPID 에 대한 BCB 가 아직 없는 상태에서 사용된다. PGBUF lock 의 역할은 두 스레드가 동시에 같은 VPID 의 BCB 를 새로 allocate 하는 것을 막는 것이다. 먼저 잡은 쪽이 이기고, 늦게 온 쪽은 대기하다가 깨어난다. 깨어난 뒤 이미 등록된 BCB 를 통 해 일반 hash-hit 경로로 진행한다.
Invalid list — free pool
섹션 제목: “Invalid list — free pool”flowchart LR S["서버 시작"] --> I["모든 BCB가 invalid_list에"] I --> AL["pgbuf_get_bcb_from_invalid_list\n(head를 꺼내옴)"] AL --> U["BCB가 VOID zone에 잠시 머무름\n(transient)"] U --> P["fix + unfix 후 LRU 2로 들어감"] P --> Z["BCB는 이후 평생 어떤 zone에 산다"] Z -. "에러 시" .-> I
그림 3 — 서버 시작 시 모든 BCB가 invalid_list에 있다가 pgbuf_get_bcb_from_invalid_list로 꺼내져 VOID zone을 거쳐 LRU 2에 진입하는 BCB 초기 할당 흐름.
페이지가 매핑되지 않은 BCB 들을 모아 둔 단일 연결 리스트다. 서버 시작 시점에는 모든 BCB 가 이 리스트에 들어 있다. 이 리스 트는 새로운 BCB 가 필요할 때만 참조된다. victim 탐색은 이와 는 별도의 메커니즘이다. alloc 도중 에러가 발생하면 BCB 는 이 리스트로 되돌아 간다.
3-zone LRU 리스트
섹션 제목: “3-zone LRU 리스트”각 LRU 리스트는 BCB 의 양방향 연결 리스트다. 두 임계값 카운터
(threshold_lru1, threshold_lru2, 기본 5 % 씩) 에 의해 세
zone 으로 나뉜다. top (LRU 1), middle (LRU 2), bottom (LRU 3)
이 그 셋이다.
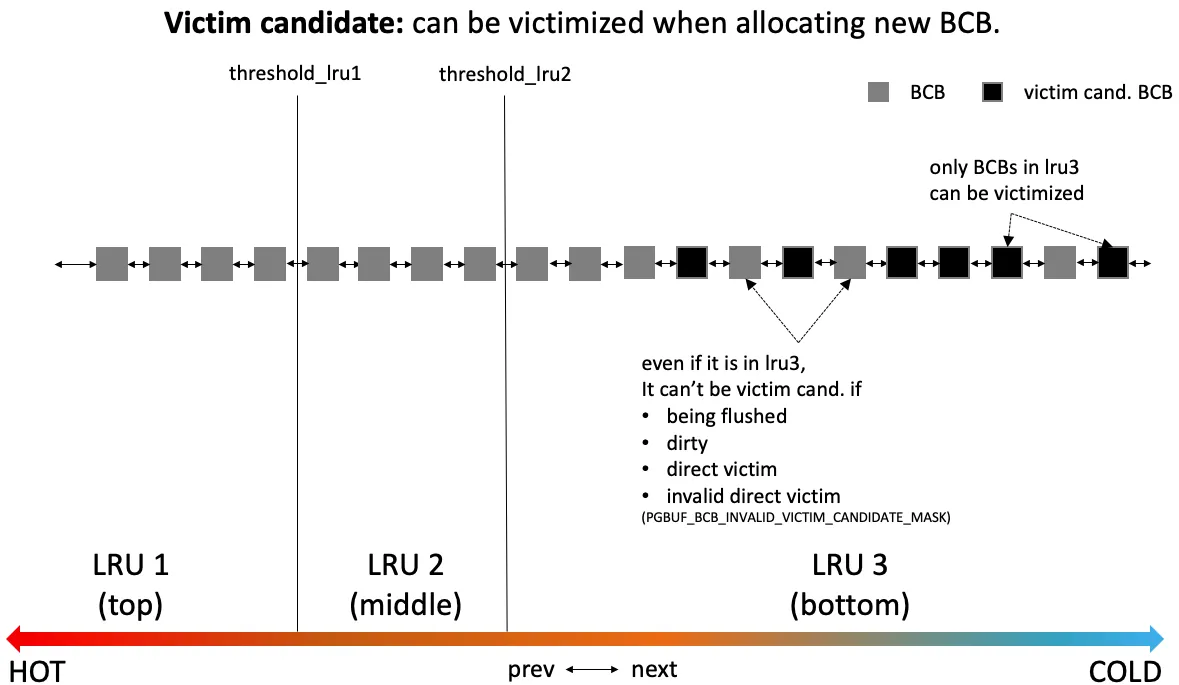
Figure 1 — A single LRU list with three zones. Black squares are victim candidates — only BCBs in LRU 3 (bottom) are eligible, and even there a BCB is excluded if it is currently being flushed, dirty, already chosen as a direct victim, or marked as an invalid direct victim. Promotions move a BCB toward LRU 1 on hit; demotions push it toward LRU 3 over time. Eviction always picks from the cold end. (Source: original Buffer Manager analysis deck, Figure 6.)
그림의 네 가지 제외 조건은 BCB 의 flag 에 대응한다.
PGBUF_BCB_FLUSHING_TO_DISK_FLAG— flush 가 진행 중인 상 태.PGBUF_BCB_DIRTY_FLAG— 마지막 flush 이후 변경된 상태. WAL 이 디스크에 도달하기 전에는 evict 할 수 없다.PGBUF_BCB_VICTIM_DIRECT_FLAG— 이미 sleep 중인 어떤 스레 드에게 direct hand-off 로 넘어가기로 약속된 상태.PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG— 한 번 약속되었 으나 그 사이에 다시 fix 되어 더 이상 가용하지 않게 된 상 태.
Private LRU 리스트 + 적응형 quota
섹션 제목: “Private LRU 리스트 + 적응형 quota”flowchart TB
subgraph PRIVATE["Private LRU 리스트들 (워커당 하나)"]
P1["worker 1 LRU\n(LRU 1/2/3 zones)"]
P2["worker 2 LRU"]
Pn["worker N LRU"]
end
subgraph SHARED["Shared LRU 리스트들"]
S1["shared LRU 1"]
S2["shared LRU 2"]
Sm["shared LRU M"]
end
PMD["Page Maintenance Daemon\n(매 100 ms)"]
PMD -- "활동량 측정\n(리스트당 hit 수)" --> P1
PMD -- "재분배" --> P2
PMD -- "shared 임계값" --> S1
P1 -- "hot이면서 old enough\n(fix ≥ 64), 또는\n다른 스레드가 unfix" --> S1
P2 -- "..." --> S2
그림 5 — 워커별 private LRU 리스트와 shared LRU 리스트의 관계. Page Maintenance Daemon이 100 ms마다 활동량을 측정해 private quota를 재분배하고, old enough이면서 hot인 BCB가 private에서 shared로 승격된다.
워커 스레드는 각각 자기 소유의 private LRU 리스트를 갖는다. 그 워커가 새로 할당하는 BCB 는 우선 자기 private LRU 리스트로 들어간다. 이후 두 조건 중 하나가 맞아 떨어지면 BCB 가 shared LRU 리스트로 옮겨진다. 첫째는 BCB 가 old enough 이면서 hot 인 경우다. old enough 는 LRU 2 의 절반 이상이 그 BCB 보다 더 hot 한 위치로 밀려난 상태를 가리키고, hot 은 fix count 가 64 이상인 상태를 가리킨다. 둘째는 fix 한 스레드와 다 른 스레드가 unfix 한 경우다. shared 리스트는 자기 소유 워커의 eviction 압력을 견딘 페이지들이 모이는 자리다.
적응형 quota 로직은 Page Maintenance Daemon
(pgbuf_adjust_quotas) 이 100 ms 마다 수행한다.
- 지난 구간 동안의 모든 private LRU 전체 hit 수를 합산한다.
- private 비율 = (private hit) / (total hit) 을 계산한다.
all_private_quota = (전체 버퍼 - invalid) * private 비 율.all_private_quota를 각 private 리스트의 활동량 비율에 따라 분배한다.- 새 quota 에 맞춰 리스트별
threshold_lru1/threshold_lru2를 다시 계산한다. - 남은 버퍼 수는 shared 리스트들에 균등 분배해서, shared 리 스트의 임계값 베이스로 쓴다.
quota 는 victim 탐색 단계에서 의미를 가진다. private 리스트 는 BCB 수가 quota 를 넘어야만 victim 대상이 될 수 있다. 이 규칙 덕분에 각 워커의 hot 페이지가 quota 안에 머물고, quota 를 초과하는 워커 (와 그에 속한 페이지) 에 eviction 압력이 모 이게 된다.
LFCQ — victim 선정
섹션 제목: “LFCQ — victim 선정”BCB 할당자가 evict 해야 할 때는 lock-free circular queue 들을 순회한다. 각 큐에는 victim 후보가 한 개 이상 있는 LRU 리스트들만 들어간다.
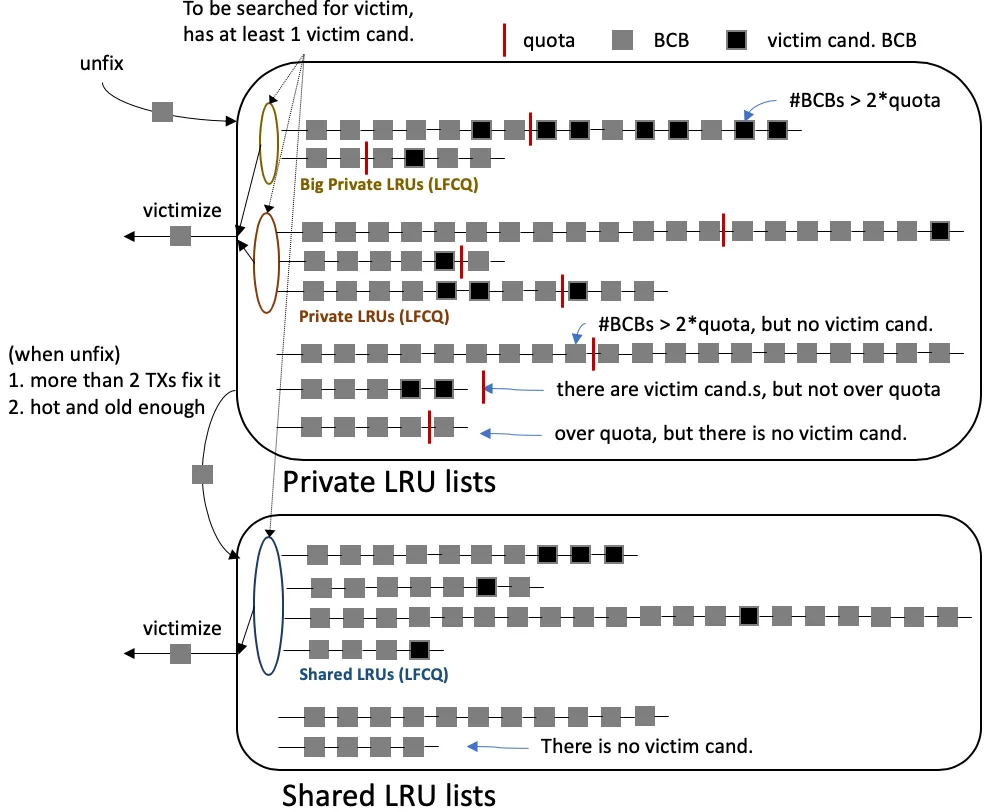
Figure 2 — Three LFCQs partition the victim search. Big Private LRUs (top) hold private lists whose BCB count exceeds 2× their quota — these are searched first because they are over-quota and likely have many candidates. Private LRUs (middle) hold private lists with at least one candidate but BCB count ≤ 2× quota. Shared LRUs (bottom) are scanned last. Each list joins the LFCQ only when it has at least one victim candidate; lists with no candidate are skipped entirely. (Source: deck Figure 9.)
// pgbuf_get_victim (sketch) — src/storage/page_buffer.cPGBUF_BCB *pgbuf_get_victim (THREAD_ENTRY *thread_p){ /* 1. Try this worker's own private LRU list first. */ /* 2. Try big-private LFCQ (#BCBs > 2 * quota). */ /* 3. Try private LFCQ. */ /* 4. Try shared LFCQ. */ /* 5. If none found → caller will sleep on direct-victim queue. */}Direct victim 인계 (hand-off)
섹션 제목: “Direct victim 인계 (hand-off)”위 네 단계 LFCQ 탐색에 모두 실패한 스레드는 재시도하지 않는 다. 대신 인계받을 때까지 자기 슬롯에서 sleep 한다.
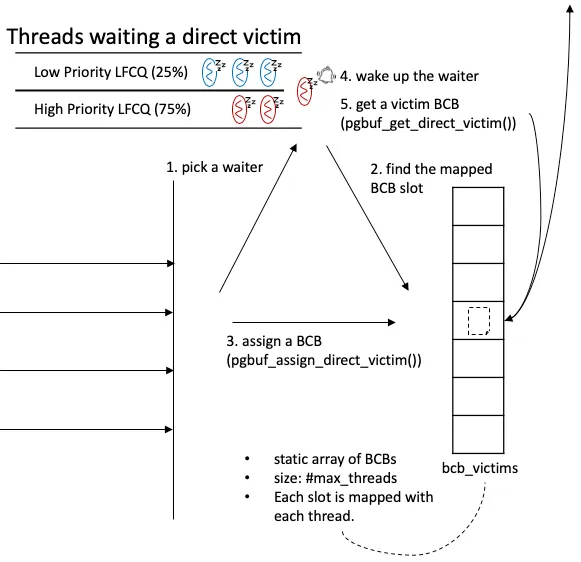
Figure 3 — Two priority LFCQs of waiting threads (High and Low,
75 / 25 weight in selection). When a producer (any of the three
flushing daemons, a normal flush completion, or maintenance work)
finds a now-victimizable BCB, it picks one waiter, finds that
waiter’s slot in the static bcb_victims[] array, writes the BCB
into that slot, and wakes the waiter. The waiter, when scheduled,
reads its own slot and proceeds. If between assign and get the BCB
gets re-fixed, the get path observes
PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG and returns to sleep.
(Source: deck Figure 13.)
high-priority 큐는 vacuum worker 와, 직전에 인계받은 direct victim 이 invalidate 되어 다시 기다리는 스레드를 위해 따로 마 련된 자리다. producer 는 셋이다.
- Page Flush Daemon (
class pgbuf_page_flush_daemon_task) — dirty BCB 를 flush 하다가 victim 가능한 BCB 를 만나면 인 계한다. 세 daemon 가운데 유일하게 전용 task class 로 구현 되어 있다. - Page Post-Flush Daemon (
pgbuf_page_post_flush_execute) — flush 가 끝난 BCB 가 victim 후보가 되면 인계한다. 별도 class 가 아니라cubthread::entry_callable_task에 묶여 등록된다. - Page Maintenance Daemon
(
pgbuf_page_maintenance_execute) — quota 를 조정하면서 동 시에 명시적으로 direct victim 을 찾아 인계한다. 등록 패턴 은 post-flush 와 같은 callable-task 방식이다.
Zone — 다섯 가지 상태 분류
섹션 제목: “Zone — 다섯 가지 상태 분류”모든 BCB 는 다음 다섯 zone 중 정확히 하나에 속한다.
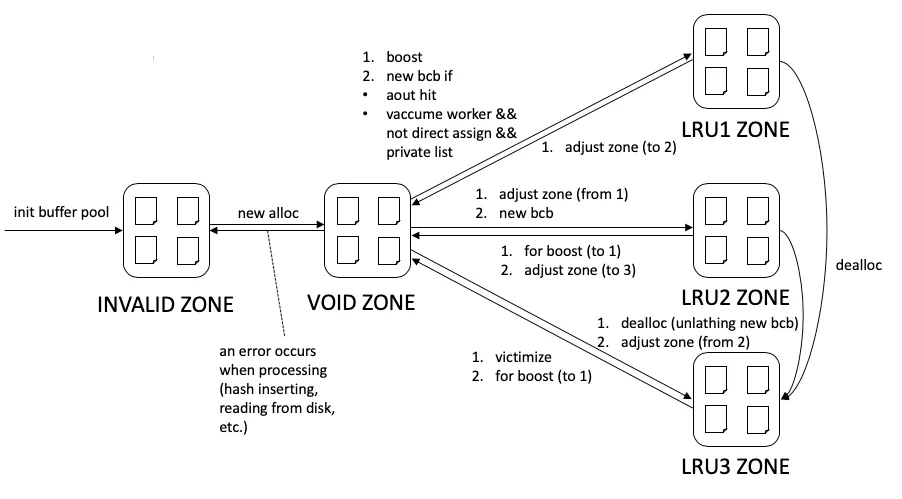
Figure 4 — Zone transitions. INVALID is the initial pool; VOID is the transient state during allocation/movement; LRU 1 / 2 / 3 are the active LRU zones. New BCBs are claimed out of INVALID into VOID; after fix+unfix they land in LRU 2 (or LRU 1 for vacuum workers / aout-hit boost). On error during alloc the BCB falls back to INVALID. Deallocation pushes a BCB straight into LRU 3 (waiting to be flushed and reused), regardless of where it currently is. (Source: deck Figure 10.)
flags.zone 필드가 이 상태를 들고 있다. zone 과 자료 구조는
일대일로 대응된다. INVALID 는 invalid list 위에 있는 상태다.
VOID 는 어떤 리스트에도 들어 있지 않은 상태다. LRU 1 / 2 / 3
은 특정 LRU 리스트의 해당 zone 영역에 있는 상태다.
BCB flags — 상태를 한 워드에 묶기
섹션 제목: “BCB flags — 상태를 한 워드에 묶기”flags 필드는 세 종류의 상태를 32 비트 워드 하나에 묶어 저장
한다.
+-------------+----------+--------+--------------------+ | BCB_FLAGS | unused | ZONE | LRU_INDEX (16) | | (7) | (5) | (4) | | +-------------+----------+--------+--------------------+BCB-specific flag 는 워드의 상위 7 비트 를 차지한다. 다만
#define 된 일곱 개 마스크가 연속 (contiguous) 되지 않는
다. 사용 비트는 31..25 — DIRTY 0x80000000, FLUSHING
0x40000000, VICTIM_DIRECT 0x20000000, INVALIDATE_DIRECT_VICTIM
0x10000000, MOVE_TO_LRU_BOTTOM 0x08000000, TO_VACUUM
0x04000000, ASYNC_FLUSH_REQ 0x02000000 — 이며, flag 영역 안의
0x01000000 비트는 예약 / 미사용이다. 항목별 의미는 다음과 같
다.
PGBUF_BCB_DIRTY_FLAG— 마지막 flush 이후 변경됨. 페이지 갱신 연산마다 set 된다. flush 시작 시 unset (실패 시 다시 set), invalidate 시 unset.PGBUF_BCB_FLUSHING_TO_DISK_FLAG— flush 가 진행 중. direct victim producer 가 인계 시 unset 한다.PGBUF_BCB_ASYNC_FLUSH_REQ— flush 요청은 들어왔으나 BCB 가 write latch 로 fix 되어 있는 상태. 해당 fixer 가 unfix 할 때 flush 를 해 달라는 요청.PGBUF_BCB_VICTIM_DIRECT_FLAG— sleep 중인 스레드에게 인계 됨.PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG— 인계받은 BCB 가 그 사이에 다시 fix 되어 무효화됨. waiter 는 다시 큐로 돌아 가야 한다.PGBUF_BCB_MOVE_TO_LRU_BOTTOM_FLAG— dealloc 시 set. unfix 경로가 일반 LRU promotion 로직을 건너뛰고 BCB 를 LRU 3 로 직행시키게 한다.PGBUF_BCB_TO_VACUUM_FLAG— vacuum 의 검사 대상으로 큐잉된 페이지에 set 된다. Producer:pgbuf_notify_vacuum_follows(page_buffer.c:15579). Consumer:pgbuf_bcb_is_to_vacuum(page_buffer.c:15591). 이 비트는PGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK(line 258) 에도 포함되어 있어, vacuum 대기 중인 BCB 는 victim 탐색에서 제외 된다. unfix 경로와 vacuum 주도의pgbuf_fix_if_not_deallocated흐름에서pgbuf_bcb_update_flags로 unset 된다 (line 2454, 8395).
BCB latch — 사용자 정의 R / W 락
섹션 제목: “BCB latch — 사용자 정의 R / W 락”모든 fix 는 BCB 에 latch 를 잡는 동작을 동반한다. 헤더가 선언
하는 PGBUF_LATCH_MODE 값은 다섯 가지다 — PGBUF_NO_LATCH,
PGBUF_LATCH_READ, PGBUF_LATCH_WRITE, PGBUF_LATCH_FLUSH,
그리고 PGBUF_LATCH_INVALID (sentinel; 실제 fix 시점에는 관
찰되지 않는다). 실제 상태는 앞의 네 가지뿐이다. 이 가운데
FLUSH 모드는 condition variable 처럼 사용된다. 어떤 스레드가
진행 중인 flush 가 끝나기를 기다릴 때 쓰는 모드이고, 실제로
latch 가 잡히는 상태는 아니다.
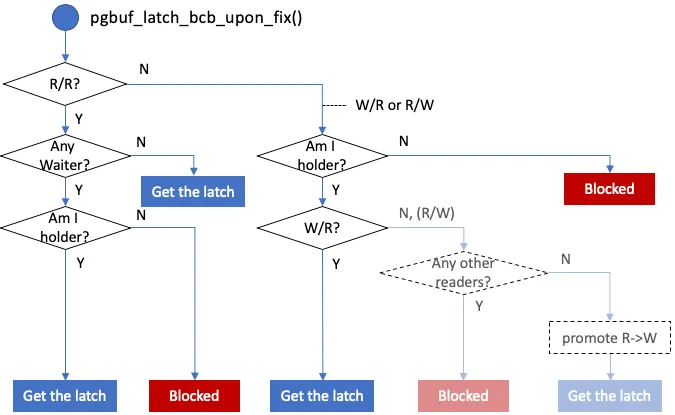
Figure 5 — pgbuf_latch_bcb_upon_fix decision tree. R/R is
compatible by default, but if any thread is already waiting (e.g.,
a write request) the new R yields and blocks to prevent
starvation. W/R and R/W block by default; a thread that already
holds the latch can pass W→R because it already holds the stronger
latch. The R→W upgrade in-place was deprecated (CUBRIDSUS-10294)
and re-added later as a separate pgbuf_promote_read_latch call
(CUBRIDSUS-15376). (Source: deck Figure 15.)
waiter 리스트는 BCB.next_wait_thrd 에 들어 있다. unlatch 시
점이 되면 pgbuf_wakeup_read_writer 가 리스트를 순회하며 다
음 규칙을 적용한다.
- 첫 번째 FLUSH waiter 는 건너뛴다. FLUSH waiter 는 별도로
pgbuf_wake_flush_waiters가 처리하기 때문이다. - 첫 번째 NO_LATCH waiter 는 정리한다. timeout 으로 깨어나서 실패 처리되어야 하는 스레드를 가리킨다.
- 첫 번째 READ waiter 를 만나면 연속된 READ waiter 모두 를 깨운다. read 는 병렬로 진행할 수 있기 때문이다.
- 첫 번째 WRITE waiter 를 만나면 자기 자신만 깨운다. write 는 단독으로 실행되어야 하기 때문이다.
holder 는 스레드 단위로 PGBUF_HOLDER 리스트에 추적된다. 덕
분에 내가 이 BCB 를 이미 잡고 있는가? 라는 질문에 O(local)
로 답할 수 있다.
PGBUF lock — VPID 단위의 alloc 잠금
섹션 제목: “PGBUF lock — VPID 단위의 alloc 잠금”fix 가 page table 에서 miss 되어 새 BCB 를 할당해야 하는 경 로에서, 같은 VPID 를 두고 두 스레드가 경쟁하면 양쪽 모두 alloc 을 시도하게 된다. PGBUF lock 은 이 경쟁을 막기 위한 장치다. alloc 전 에 해당 VPID 를 lock 을 잡고, BCB 가 page table 에 등록되면 풀어 준다.
flowchart LR T1["스레드 A:\nfix VPID 100"] --> H1["page table miss"] H1 --> L1["pgbuf_lock_page(VPID 100)"] L1 --> A1["BCB 할당,\n디스크에서 read,\npage table에 등록"] A1 --> U1["pgbuf_unlock_page(VPID 100)"] T2["스레드 B:\nfix VPID 100\n(좀 늦게 시작)"] --> H2["page table miss"] H2 --> L2["pgbuf_lock_page(VPID 100)\n→ A 뒤에서 block"] L2 -. "U1 후 wake" .-> RT["재시도 → page table hit"] RT --> DONE["일반 hash-hit 경로로 진행"]
그림 10 — 동일 VPID를 두고 두 스레드가 동시에 alloc을 시도할 때 PGBUF lock으로 경쟁을 직렬화하는 흐름. 먼저 lock을 잡은 스레드가 BCB를 등록하면 나중 스레드는 깨어나 hash-hit 경로로 진행한다.
lock 체인은 BCB 체인과 같은 해시 버킷에 매달려 있다. 경쟁에 서 진 쪽 스레드는 깨어난 뒤 page table 에 이미 들어 있는 BCB 를 발견하고, 일반 hash-hit 경로로 진행한다.
Ordered fix — 다중 페이지 deadlock 회피
섹션 제목: “Ordered fix — 다중 페이지 deadlock 회피”한 연산이 여러 페이지를 동시에 fix 해야 할 때가 있다. 예를 들
어 REC_RELOCATION 과 REC_NEWHOME 두 heap 페이지를 함께 잡
아야 하거나, REC_BIGONE 과 overflow 페이지를 함께 잡아야 하
는 경우다. 이때 서로 다른 연산이 같은 페이지들을 다른 순서로
잡으면 데드락에 빠진다. CUBRID 의 답은 ordered fix 다. 모
든 페이지에 숫자 rank 를 매기고, 항상 rank 오름차순으로
fix 하는 방식이다.
// PGBUF_ORDERED_RANK — src/storage/page_buffer.htypedef enum{ PGBUF_ORDERED_HEAP_HDR = 0, /* heap header 페이지 먼저 */ PGBUF_ORDERED_HEAP_NORMAL, /* 그 다음 일반 heap 페이지 */ PGBUF_ORDERED_HEAP_OVERFLOW, /* 그 다음 overflow 페이지 */ PGBUF_ORDERED_RANK_UNDEFINED,} PGBUF_ORDERED_RANK;
// PGBUF_WATCHER — ordered fix를 지원하는 page latch handlestruct pgbuf_watcher{ PAGE_PTR pgptr; PGBUF_WATCHER *next; PGBUF_WATCHER *prev; PGBUF_ORDERED_GROUP group_id; /* group(HEAP header)의 VPID */ unsigned latch_mode:7; unsigned page_was_unfixed:1; /* refix가 일어났는가? */ unsigned initial_rank:4; unsigned curr_rank:4; /* (debug fields elided) */};pgbuf_ordered_fix 는 요청된 rank 가 현재 잡고 있는 watcher
들의 rank 가운데 어느 것보다도 더 큰지 검사한다. 더 작거나 같
다면, 순서가 어긋난 페이지들을 일단 unfix 하고 정렬한 뒤
rank 순서로 다시 fix 한다. 이때 page_was_unfixed = true 는
caller 에게 그 사이에 페이지 상태가 바뀌었을 수 있다 라고
알려 주는 신호다.
Background daemon
섹션 제목: “Background daemon”server mode 에서 foreground worker 와 별도로 세 daemon 이 돈 다.
| Daemon | 주기 | 하는 일 |
|---|---|---|
| Page Flush Daemon | adaptive | dirty 페이지 flush; victimizable이면 인계 |
| Page Post-Flush Daemon | event-driven | flush 완료 후처리; victimizable이면 인계 |
| Page Maintenance Daemon | 100 ms | private LRU quota 조정; direct victim 검색 |
flush daemon 의 flush 속도는
pgbuf_flush_control_from_dirty_ratio 가 dirty 비율에 따라
조정한다. dirty 비율이 높아질수록 flush 가 빨라진다. daemon
의 활성도는 boolean 두 개
(pgbuf_keep_victim_flush_thread_running,
pgbuf_assign_flushed_pages) 가 게이팅한다.
Double Write Buffer (DWB) — torn page 방어
섹션 제목: “Double Write Buffer (DWB) — torn page 방어”DB 의 페이지 크기가 OS 의 디스크 블록 크기보다 클 때 (예: DB 16 K vs OS 4 K), 페이지 한 장의 일부만 디스크에 기록된 상태에 서 크래시가 일어날 수 있다. 이를 torn page 라고 한다. 이 경우 디스크 위의 DB 페이지는 앞부분에는 새 데이터가, 뒷부분에 는 옛 데이터가 섞인 frankenstein 상태가 된다. WAL 은 일관된 옛 상태를 가정하기 때문에 WAL 재적용만으로는 이런 페이지를 복 구할 수 없다.
DWB 는 이 문제를 풀기 위한 메커니즘이다. 모든 페이지는 두 번 에 걸쳐 디스크에 쓰인다. 먼저 (1) 순차적인 DWB 영역에 쓰고, 그 다음 (2) 실제 페이지 위치에 쓴다. 크래시 복구 시점에는 다 음 단계를 거친다.
- checksum 이 깨진 DB 페이지마다 DWB 를 조회한다.
- 그 VPID 의 깨끗한 사본이 DWB 에 있으면 그 사본으로 복원한 다.
- 복원된 페이지 위에 WAL 을 다시 적용한다.
CUBRID 의 DWB 는 src/storage/double_write_buffer.{hpp,cpp}
(약 4 200 줄) 에 자리한다. page buffer 의 fix 경로는 cache
miss 시점에 디스크 read 보다 먼저 DWB 를 조회한다.
// fix path on page-table miss → claim BCB// if (fetch_mode != NEW_PAGE)// // 먼저 DWB부터 시도// if (DWB has VPID)// read from DWB into the BCB's iopage_buffer// else// read from storage이 덕분에 DWB hit 가 일어난 cache miss 는 디스크 read 를 한 번 절약하게 된다.
소스 코드 가이드
섹션 제목: “소스 코드 가이드”심볼명을 anchor 로 삼는다 — 라인 번호가 아니다. CUBRID 소스는 시간이 지나면 변한다. 그에 비해 함수명·struct 태그· enum 태그 같은 심볼은 잘 변하지 않는 안정된 식별자다. 현재 위치는
git grep -n '<symbol>' src/storage/로 찾으면 된 다.
타입 정의 (src/storage/page_buffer.{h,c})
섹션 제목: “타입 정의 (src/storage/page_buffer.{h,c})”struct pgbuf_bcb(page_buffer.c) — buffer control block.struct pgbuf_iopage_buffer(page_buffer.c) — 페이지 바이 트 carrier;FILEIO_PAGE를 임베드.struct pgbuf_buffer_hash(page_buffer.c) — page-table 버킷: BCB 체인 + PGBUF lock 체인 + bucket mutex.struct pgbuf_buffer_lock(page_buffer.c) — BCB allocation 시 사용되는 VPID 단위 잠금.struct pgbuf_holder(page_buffer.c) — 한 스레드가 들고 있는 latch 정보.struct pgbuf_lru_list(page_buffer.c) — LRU 리스트 한 개.struct pgbuf_pool(pgbuf_Pool,page_buffer.c) — buffer manager 전역 상태.enum PAGE_FETCH_MODE(page_buffer.h) — 7 가지 모드 (OLD_PAGE / NEW_PAGE / OLD_PAGE_IF_IN_BUFFER / OLD_PAGE_PREVENT_DEALLOC / OLD_PAGE_DEALLOCATED / OLD_PAGE_MAYBE_DEALLOCATED / RECOVERY_PAGE).enum PGBUF_LATCH_MODE(page_buffer.h) — 5 가지 모드.enum PGBUF_LATCH_CONDITION(page_buffer.h) — UNCONDITIONAL / CONDITIONAL.enum PGBUF_PROMOTE_CONDITION(page_buffer.h) — ONLY_READER / SHARED_READER (R → W promotion).enum PGBUF_ORDERED_RANK(page_buffer.h) — ordered fix 용 4 단계 rank.struct pgbuf_watcher(page_buffer.h) — ordered fix 용 handle.
라이프사이클 (src/storage/page_buffer.c)
섹션 제목: “라이프사이클 (src/storage/page_buffer.c)”pgbuf_initialize— 모듈 초기화.pgbuf_finalize— 모듈 해제.pgbuf_daemons_init/pgbuf_daemons_destroy— 세 flush daemon 생성 / 해제.pgbuf_thread_variables_init— 워커별 초기화 (private LRU 인덱스 할당).
Fix / unfix (src/storage/page_buffer.c)
섹션 제목: “Fix / unfix (src/storage/page_buffer.c)”pgbuf_fix(debug, release variants) — 공개 진입점.pgbuf_fix_with_retry— 일시적 실패 시 재시도 wrapper.pgbuf_simple_fix/pgbuf_simple_unfix— temporary file 용 최소 경로.pgbuf_ordered_fix/pgbuf_ordered_unfix—PGBUF_WATCHER를 쓴 다중 페이지 deadlock-free fix.pgbuf_promote_read_latch— R → W 승격.pgbuf_unfix/pgbuf_unfix_all.pgbuf_fix_if_not_deallocated— deallocation 을 인지하는 변형.
BCB allocation (src/storage/page_buffer.c)
섹션 제목: “BCB allocation (src/storage/page_buffer.c)”pgbuf_claim_bcb_for_fix— 외부 allocate-and-bind 루프.pgbuf_allocate_bcb— 할당 (invalid → victim → direct- victim sleep).pgbuf_get_bcb_from_invalid_list.pgbuf_get_victim— LFCQ 스캔.pgbuf_assign_direct_victim/pgbuf_get_direct_victim.
LRU + zone (src/storage/page_buffer.c)
섹션 제목: “LRU + zone (src/storage/page_buffer.c)”pgbuf_lru_add_bcb_to_top/_to_middle/_to_bottom.pgbuf_move_bcb_to_bottom_lru.pgbuf_lru_boost_bcb— LRU 1 로 promote.pgbuf_lru_adjust_zones— 임계값 변경 후 재균형.pgbuf_should_move_private_to_shared.pgbuf_adjust_quotas— Page Maintenance Daemon 이 100 ms 마다 수행.PGBUF_IS_BCB_OLD_ENOUGH— boost gate.
Page table + PGBUF lock (src/storage/page_buffer.c)
섹션 제목: “Page table + PGBUF lock (src/storage/page_buffer.c)”pgbuf_hash_func_mix— VPID 해싱.pgbuf_hash_chain_lookup— bucket walk.pgbuf_lock_page/pgbuf_unlock_page— VPID 단위 alloc 잠금.
BCB latch (src/storage/page_buffer.c)
섹션 제목: “BCB latch (src/storage/page_buffer.c)”pgbuf_latch_bcb_upon_fix— 호환성 결정.pgbuf_block_bcb— waiter 로 등록 후 sleep.pgbuf_wakeup_read_writer— unlatch 시 waiter 깨우기.pgbuf_wake_flush_waiters— flush 완료 시 FLUSH waiter 깨 우기.pgbuf_promote_read_latch_release/_debug— R → W 승 격.
Flush + DWB (src/storage/page_buffer.c,
섹션 제목: “Flush + DWB (src/storage/page_buffer.c,”src/storage/double_write_buffer.cpp)
pgbuf_flush/pgbuf_flush_with_wal— BCB 1 개 flush.pgbuf_flush_victim_candidates— Page Flush Daemon 본체.pgbuf_flush_checkpoint— checkpoint flush.pgbuf_flush_all/_unfixed/_unfixed_and_set_lsa_as_null.pgbuf_bcb_flush_with_wal— flush 전후의 flag 조작.dwb_*— double write buffer 진입 / lookup / recovery.
Daemon (src/storage/page_buffer.c, server mode 전용)
섹션 제목: “Daemon (src/storage/page_buffer.c, server mode 전용)”class pgbuf_page_flush_daemon_task— Page Flush Daemon 본체 (세 daemon 중 유일한 전용 task class).pgbuf_page_post_flush_execute— Page Post-Flush Daemon 의 callable.cubthread::entry_callable_task에 묶여 등록 된다.pgbuf_page_maintenance_execute— Page Maintenance Daemon 의 callable. 등록 방식은 post-flush 와 같다.pgbuf_page_flush_daemon_init/pgbuf_page_post_flush_daemon_init/pgbuf_page_maintenance_daemon_init— daemon 기동.pgbuf_keep_victim_flush_thread_running.pgbuf_assign_flushed_pages.pgbuf_direct_victims_maintenance.
이 개정 시점의 위치 힌트
섹션 제목: “이 개정 시점의 위치 힌트”| 심볼 | 파일 | 라인 |
|---|---|---|
enum PAGE_FETCH_MODE | page_buffer.h | 172 |
enum PGBUF_LATCH_MODE | page_buffer.h | 190 |
enum PGBUF_ORDERED_RANK | page_buffer.h | 222 |
struct pgbuf_watcher | page_buffer.h | 234 |
PGBUF_FIX_COUNT_THRESHOLD | page_buffer.c | 106 |
PGBUF_BCB_DIRTY_FLAG | page_buffer.c | 224 |
PGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK | page_buffer.c | 258 |
PGBUF_HASH_SIZE | page_buffer.c | 296 |
pgbuf_initialize | page_buffer.c | 1518 |
pgbuf_fix_release | page_buffer.c | 2041 |
pgbuf_latch_bcb_upon_fix | page_buffer.c | 6073 |
pgbuf_lock_page | page_buffer.c | 7718 |
pgbuf_claim_bcb_for_fix | page_buffer.c | 8133 |
pgbuf_get_victim | page_buffer.c | 8805 |
pgbuf_adjust_quotas | page_buffer.c | 13639 |
pgbuf_assign_direct_victim | page_buffer.c | 14809 |
pgbuf_page_maintenance_execute | page_buffer.c | 16375 |
class pgbuf_page_flush_daemon_task | page_buffer.c | 16396 |
pgbuf_page_post_flush_execute | page_buffer.c | 16450 |
page_buffer.c 는 약 17 000 줄이라 심볼 단위 git grep 이
권장되는 lookup 방식이다.
소스 검증 (2026-04-29 기준)
섹션 제목: “소스 검증 (2026-04-29 기준)”각 항목은 현재 소스에 대한 사실이고, 원본 분석 자료를 함께 보지 않아도 그 자체로 읽힌다. 끝의 부연은 어떻게 검증 되었는지를 적고, 관련이 있을 때는 역사적 드리프트나 검증의 한계도 적는다. 미해결 질문 은 큐레이터가 해결을 미루고 기록 해 둔 갭이다 — 차후 독자는 이를 알려진 버그가 아니 라 시작점으로 다룬다.
검증된 사실
섹션 제목: “검증된 사실”-
page-table 해시는 2²⁰ = 1 048 576 버킷, 서버 시작 시점에 고정.
pgbuf_initialize/pgbuf_initialize_buffer_hash_table에서 2026-04-29 검증. 각 버킷이 자기hash_mutex, BCB 체인, PGBUF-lock 체인을 들고 있다. 하드코딩 — 런타임 파라미터 아님. -
PGBUF lock 체인은 해시 버킷 단위 로 존재한다 — VPID 단 위가 아니다.
pgbuf_lock_page/pgbuf_unlock_page를 읽어서 2026-04-29 검증. lock 객체는 버킷 구조체 안에 산다 — 즉, BCB alloc 경쟁을 버킷 단위로 직렬화한다. -
LRU 는 정확히 세 zone 을 가진다 (top / middle / bottom = LRU 1 / 2 / 3), 기본 임계값 5 %.
page_buffer.c의 zone 상수에서 2026-04-29 검증. evict 가능한 BCB 는 LRU 3 에 있는 것뿐이다. LRU 1, 2 는 보호된다. -
victim 후보 자격을 박탈하는 네 가지 조건. BCB 는 다음 중 하나라도 해당하면 후보가 아니다 — flush 중 (
PGBUF_BCB_FLUSHING_TO_DISK_FLAG), dirty (PGBUF_BCB_DIRTY_FLAG), 이미 direct victim (PGBUF_BCB_VICTIM_DIRECT_FLAG), invalidate 된 direct victim (PGBUF_BCB_INVALIDATE_DIRECT_VICTIM_FLAG). 이 네 비트는PGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK로 묶여 있다. 2026-04-29 검증. -
direct victim 선택은 우선순위 큐 두 개 (75 / 25 가중치) 를 사용한다. BCB producer 는 high-priority LFCQ 에서 low-priority 의 3 배 확률로 선택한다.
pgbuf_assign_direct_victim을 읽어서 2026-04-29 검증. high priority 는 vacuum worker, 그리고 invalidate 후 재시도 중인 스레드에 할당된다. -
server mode 에서 background daemon 셋이 돈다. Page Flush, Page Post-Flush, Page Maintenance —
pgbuf_daemons_init에 선언되어 있다. 2026-04-29 검증. -
quota 조정 주기는 100 ms. Page Maintenance Daemon 의
pgbuf_adjust_quotas가 100 ms 마다 돈다. daemon task 를 읽어서 2026-04-29 검증. quota 값은 history 와 보간되어 smoothing 된다 — 한 구간의 raw 활동량을 그대로 쓰지는 않는 다. -
boost 용 old enough 기준 = LRU 2 의 절반 이상이 그 BCB 보다 더 hot 한 위치로 밀려난 상태.
PGBUF_IS_BCB_OLD_ENOUGH매크로에 구현되어 있다. 2026-04-29 검증. 짧게 살았다 사라지는 BCB 가 단 한 번의 fix-unfix 로 LRU 1 까지 boost 되는 것을 막는다. -
private → shared 이동 트리거. 다음 둘 중 하나면 이동된 다 — (a) BCB 가 hot 이면서 (fix count ≥ 64) old enough 이 거나, (b) fix 한 스레드와 다른 스레드가 unfix 한 경우.
pgbuf_should_move_private_to_shared에서 2026-04-29 검 증. -
R → W in-place 승격은 폐기되었다가 별도로 다시 추가되었 다. 원래 동작은 잡고 있는 read latch 를
pgbuf_latch_bcb_upon_fix에서 자동으로 write 로 승격하는 것이었다. CUBRIDSUS-10294 에서 제거되었고, 이후 CUBRIDSUS-15376 에서 별도의pgbuf_promote_read_latch호출 로 다시 추가되었다. 현재 결정 트리는 in-place 승격 경로가 도달 불가능함을 assert 한다. BCB latch 결정 로직을 읽어서 2026-04-29 검증. -
DWB 는 page-table miss 시 디스크 read 보다 먼저 조회된 다. BCB claim 경로 (
pgbuf_claim_bcb_for_fix→pgbuf_read_page→ DWB 조회) 에서 2026-04-29 검증. DWB hit 는 디스크 read 한 번을 절약하고, miss 면 볼륨 read 로 fall through 한다.
미해결 질문
섹션 제목: “미해결 질문”-
PGBUF_BCB_TO_VACUUM_FLAG는 무엇인가?pgbuf_notify_vacuum_follows(page_buffer.c:15579), consumer 는pgbuf_bcb_is_to_vacuum(page_buffer.c:15591) 이다. 이 비트는PGBUF_BCB_INVALID_VICTIM_CANDIDATE_MASK(line 258) 에 포함되어 있어 vacuum 대기 중인 BCB 는 victim 으로 선택될 수 없다. unfix 경로의pgbuf_bcb_update_flags가 unset 한다 (line 2454, 8395). 남은 후속 과제 —pgbuf_notify_vacuum_follows의 caller (heap / vacuum 서 브시스템) 전체 열거. page-buffer 문서의 범위 밖이다. -
page-table 크기가 왜 2²⁰ 으로 하드코딩인가? 해시 크기 는
pb_buffer_capacity파라미터와 무관하게 고정이다. 매 우 큰 buffer pool 을 쓰는 워크로드에서는 체인 길이가 길어 질 수 있다. 추적 경로 — 메모리가 큰 워크로드에서 bucket 체인 길이를 계측. 해시 크기를 buffer pool 용량에 비례시켜 야 하는지 검토. -
OLD_PAGE_PREVENT_DEALLOC/OLD_PAGE_DEALLOCATED/OLD_PAGE_MAYBE_DEALLOCATED가 TBU 로 적혀 있다. 헤더 에는 PAGE_FETCH_MODE 값으로 등록되어 있지만 발표 자료가 의 미를 적어 두지 않았다. 추적 경로 — 각 변형의 호출지를 읽 어서 사용 패턴에서 의미를 역추론. -
direct-victim 인계 시점에
PGBUF_BCB_FLUSHING_TO_DISK_FLAG를 왜 unset 하는가? 발 표 자료가 명시적으로 “왜 끄는지는 모르겠음. 플러시를 중지 시키는 것도 아니고” 라고 적었다. unset 이 실제로 flush 를 취소하지는 않는다. 추적 경로 — 인계 시점에 flag 를 끄는 것이 어떤 consumer 에게 어떤 영향을 주는지 (아마 “이 BCB 가 아직 flush 대상인가?” 를 보는 다른 코드 경로) 추적. -
direct-victim slot 의 starvation 가능성. 어떤 스레드가 반복적으로 invalidate (assign → re-fix → invalidate) 되면 high-priority 큐에 계속 머물게 된다. 병리적 워크로드에서 다른 high-priority waiter 를 굶길 수 있는가? 추적 경로 — 고경합 워크로드에서 re-queue 횟수를 계측.
-
flush daemon 의 적응형 속도 (
pgbuf_flush_control_from_dirty_ratio) 는 burst 워크로드 에서 실제로 어떻게 동작하는가? 발표 자료는 dirty ratio 기반이라는 점만 언급한다. smoothing 동작은 적혀 있지 않 다. 추적 경로 — 함수 본체를 읽고 입력값을 추적. -
TDE (Transparent Data Encryption) 와의 상호작용. 헤더 가
pgbuf_set_tde_algorithm을 선언하고 BCB 가 페이지별 TDE 상태를 들고 있지만, 발표 자료가 암호화를 다루지 않는 다. 추적 경로 — flush 와 read 경로에서 encrypt / decrypt 경계를 추적.
CUBRID 너머 — 비교 설계와 연구 동향 (Beyond CUBRID — Comparative Designs & Research Frontiers)
섹션 제목: “CUBRID 너머 — 비교 설계와 연구 동향 (Beyond CUBRID — Comparative Designs & Research Frontiers)”분석이 아닌 포인터 (pointers). 각 항목은 후속 문서의 시작 점이고, 깊이는 의도적으로 얕다.
- PostgreSQL clock-sweep + buffer 파티션. PostgreSQL 은
LRU 가 아니라 clock 알고리즘을
BufferDesc배열 위에서 돌 린다.BufFreelistLock과BufMappingLock은 해시별로 파 티션된다. per-worker LRU 는 없다. 비교로 CUBRID 의 private LRU 복잡도가 정당한 비용인지, 아니면 공유 캐시 패턴 에 대한 과도한 정교화인지를 가늠할 수 있다. - MySQL InnoDB 의 midpoint LRU + 적응형 flush. InnoDB 의
LRU 에는 head 로부터 3 / 8 지점에 midpoint 가 있다 — 새 페
이지는 head 가 아니라 midpoint 로 들어가서 scan flooding 에
저항한다. 적응형 flush 는
innodb_io_capacity와 redo-log 지연 (lag) 에 따라 페이지 out 속도를 조절한다. CUBRID 의 3-zone LRU + dirty-ratio flush 제어와 대응된다. 나란히 비 교한 글이 도움이 될 것이다. - Oracle 의 multi-pool buffer cache. Oracle 은 KEEP, RECYCLE, DEFAULT 의 세 풀을 노출해서 DBA 가 hot 테이블을 KEEP 에 고정하고 스캔을 RECYCLE 로 보낼 수 있게 한다. CUBRID 에는 이런 풀 분할이 없다. 비슷한 역할을 워커 주도 private LRU 가 한다. trade-off 비교 (DBA control vs adaptive) 가 가치 있을 듯.
- HyPer / Hekaton — buffer pool 자체가 없는 경우. in-memory 엔진은 buffer manager 를 통째로 건너뛴다. 이 비 교의 의미는, 우리가 디스크 거주 (disk-resident) 라는 이 유로 지불하는 비용을, 그 비용을 지불하지 않는 엔진과 함께 측정해 보는 것에 있다.
- WBL 과 SSD. persistent memory 와 SSD-aware page management 에 대한 최근 연구는 16 K 페이지라는 가정 자체를 의문에 부친다. CUBRID 의 DWB 는 HDD 시대의 torn-page 방어 책으로 설계되어 있고, 최신 NVMe 위에서의 비용 / 효과는 재평 가가 필요하다.
- Lock-free buffer manager. Sadoghi et al. LeanStore
(ICDE 2018), Hekaton (VLDB 2013) 는 핫 패스에서 OS mutex
를 완전히 제거한다. CUBRID 의 BCB latch 는 사용자 정의지
만, 상태 변경에는 여전히 BCB 별
pthread_mutex_t를 쓴다. 비교가 도달 가능한 latency 하한선을 분명히 해 준다. - 관련된 최근 연구 흐름. Mohan et al., ARIES (TODS 92) — WAL / buffer 프로토콜; Stoica & Ailamaki, Enabling Efficient OS Paging for Main-Memory OLTP Databases (DaMoN 13) — buffer / OS 상호작용; 본 지식 베이스의 OOS feature 설계 문서 — 최근 CUBRID buffer 관련 변경의 최신 동향.
이 섹션의 의도는 다음 문서의 씨앗을 뿌리는 것이지, 여기서 분석을 마치는 것이 아니다. 각 항목은 차례가 오면 자체 큐레이 트 노트가 되어야 한다.
원본 분석 (raw/code-analysis/cubrid/storage/buffer_manager/)
섹션 제목: “원본 분석 (raw/code-analysis/cubrid/storage/buffer_manager/)”CodeAnal_BM.docx— 메인 텍스트. 9 개 섹션이 BCB, fix / unfix, page table, invalid list, private / shared LRU- LFCQ, zone, direct victim, BCB flag, BCB latch + PGBUF lock 을 다룬다. 이 DOCX 에 임베드된 18 개 figure 가 본 문서 의 6 개 임베드 이미지의 출처다.
CodeAnal_BM_pt_1.pdf— 같은 내용의 PDF 렌더.DesignDoc-PageBuffer_page_quota.pdf— private LRU quota 시스템의 설계 노트 (pgbuf_adjust_quotas의 근거).
Notion (CUBRID DEV WIKI)
섹션 제목: “Notion (CUBRID DEV WIKI)”- Storage – Concurrency 코드 분석 — Page Buffer 가 다른 모 든 모듈 (heap, index, catalog) 아래에 깔려서 I/O 경로가 모 두 통과하는 관계를 module 단위로 보여 주는 컨텍스트.
교재 챕터 (knowledge/research/dbms-general/)
섹션 제목: “교재 챕터 (knowledge/research/dbms-general/)”- Database System Concepts (Silberschatz, Korth, Sudarshan, 6판), 13장 Storage and File Structure — buffer manager, page replacement.
- Database Internals (Petrov), 4장 Implementing B-Trees, 5장 “Transaction Processing and Recovery” — buffer / log 상호작용.
- Mohan et al., ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging (TODS 1992) — buffer manager 의 WAL 순서 invariant.
CUBRID 소스 (/data/hgryoo/references/cubrid/)
섹션 제목: “CUBRID 소스 (/data/hgryoo/references/cubrid/)”src/storage/page_buffer.hsrc/storage/page_buffer.csrc/storage/double_write_buffer.hppsrc/storage/double_write_buffer.cpp